交互式分割
注意
Segment Anything Model for Medical Image Analysis: an Experimental Study | Papers With Code
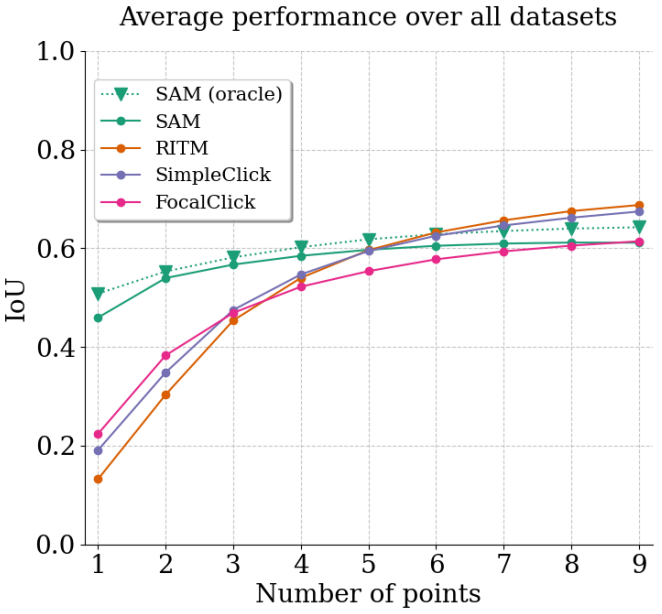
SAM outperforms similar methods RITM, SimpleClick, and FocalClick in almost all single-point prompt settings.
Deep Interactive Object Selection. CVPR 2016
Deep Interactive Object Selection 还用了 graph cut,处理FCN得到的概率图,得到最终的分割结果
该篇为将深度学习引入交互式分割的开山之作,贡献在于搭建了点击式交互式分割的基本pipeline,以及train/val protocol, 这些规范都沿用至今, 对后面的文章产生了深远影响。 如下图,它将positive、negative点击用distance map进行表示,和原图concat成5-channel input送进分割模型,预测目标掩码。
提出了为什么语义分割、检测为什么不能直接用于交互式分割的几个原因:
模型泛化问题、没有见过的实例

Interactive image segmentation with first click attention. In CVPR, 2020.
核心思想是:由于第一个点击一般都会点在目标物体的中心区域,所以第一个点击提供的信息应该比其他的点击多。于是该篇文章使用第一个点击生成attention对feature进行加权,也达到了更好的分割结果。
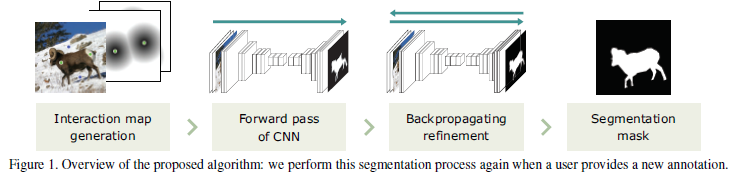
Interactive image segmentation via backpropagating refinement scheme. CVPR, 2019.
Backpropagating Refinement Scheme for Interactive Segmentation 反向传播修正机制 (CVPR2019)_cvpr 2019
传统的基于深度学习的交互式分割框架利用前向传播得到的结果,还是存在一定的偏差(比如交互部位在最后的分割结果中依然会被分割错)。因此提出 backpropagating refinement scheme 进行修正。
Training phase 按照传统的基于深度学习的交互式分割框架训练模型。 Testing phase
- 首先将待分割的图像和用户标注作为输入传入分割框架中进行前向传播得到初始分割结果。
- 由于初始前向传播的分割结果可能存在于用户标注不匹配的部分,因此采用反向传播修正机制 修正 interaction map (而不是对模型进行 fine-tuning),强制结果在用户交互的部分具有正确的结果。
- 上述步骤1和步骤2交替进行,直到结果可以满意。
f-brs: Rethinking backpropagating refinement for interactive segmentation. CVPR, 2020.
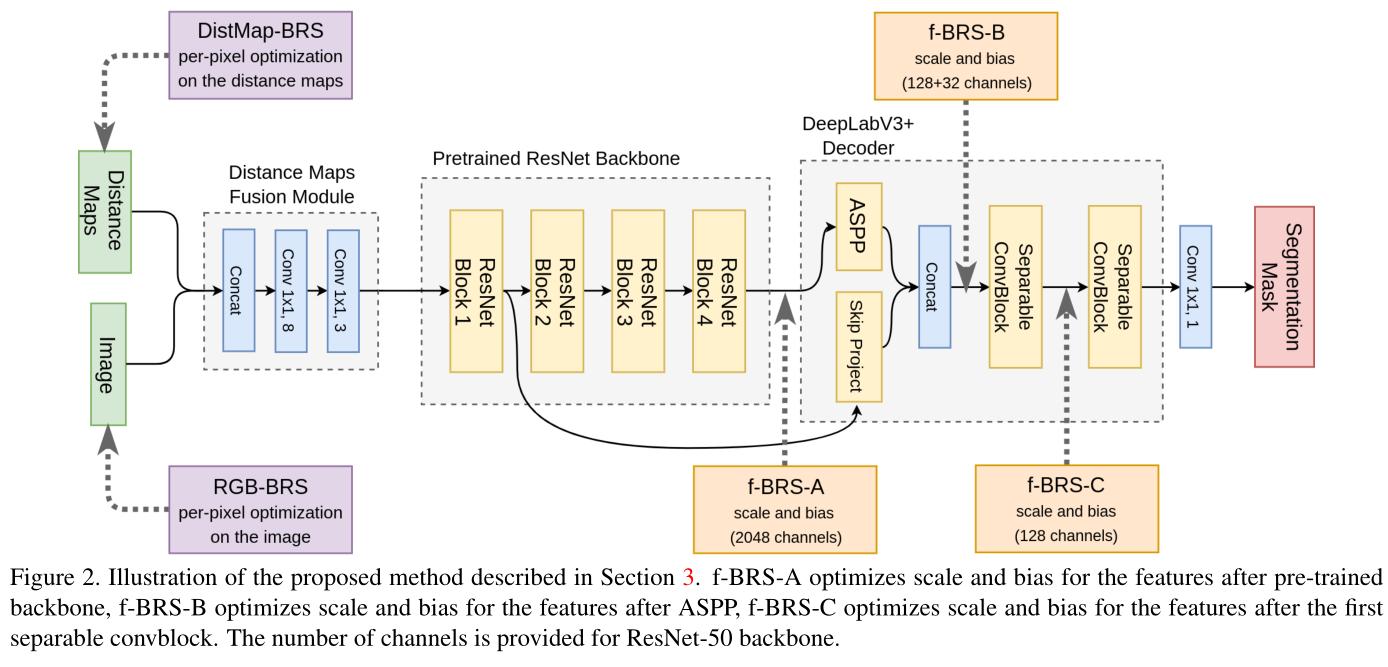
这两篇文章的的探索方向相同,核心思想都是:
- 用户施加的 postive/negative click都是有前景/背景label的,这些点击区域相当于有ground truth。
- 所以这两篇文章利用点击点的label信息对模型参数进行在线微调。
- 由此,模型对于特定的图片和特定的点击都会进行case by case的参数更新,从而达到更好的分割效果。
Iteratively trained interactive segmentation
[1805.04398] Iteratively Trained Interactive Segmentation (arxiv.org)
新的迭代训练策略
增加了一个mask作为每次迭代的输入
Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections. ECCV2020
https://arxiv.org/abs/1911.12709
非冻结的网络结构,每次推理都是对网络的微调
EdgeFlow. ICCV2021
[2109.09406] EdgeFlow: Achieving Practical Interactive Segmentation with Edge-Guided Flow (arxiv.org)
(13条消息) EdgeFlow(ICCV2021) 论文阅读笔记(理论篇)_QianZ423的博客-CSDN博客
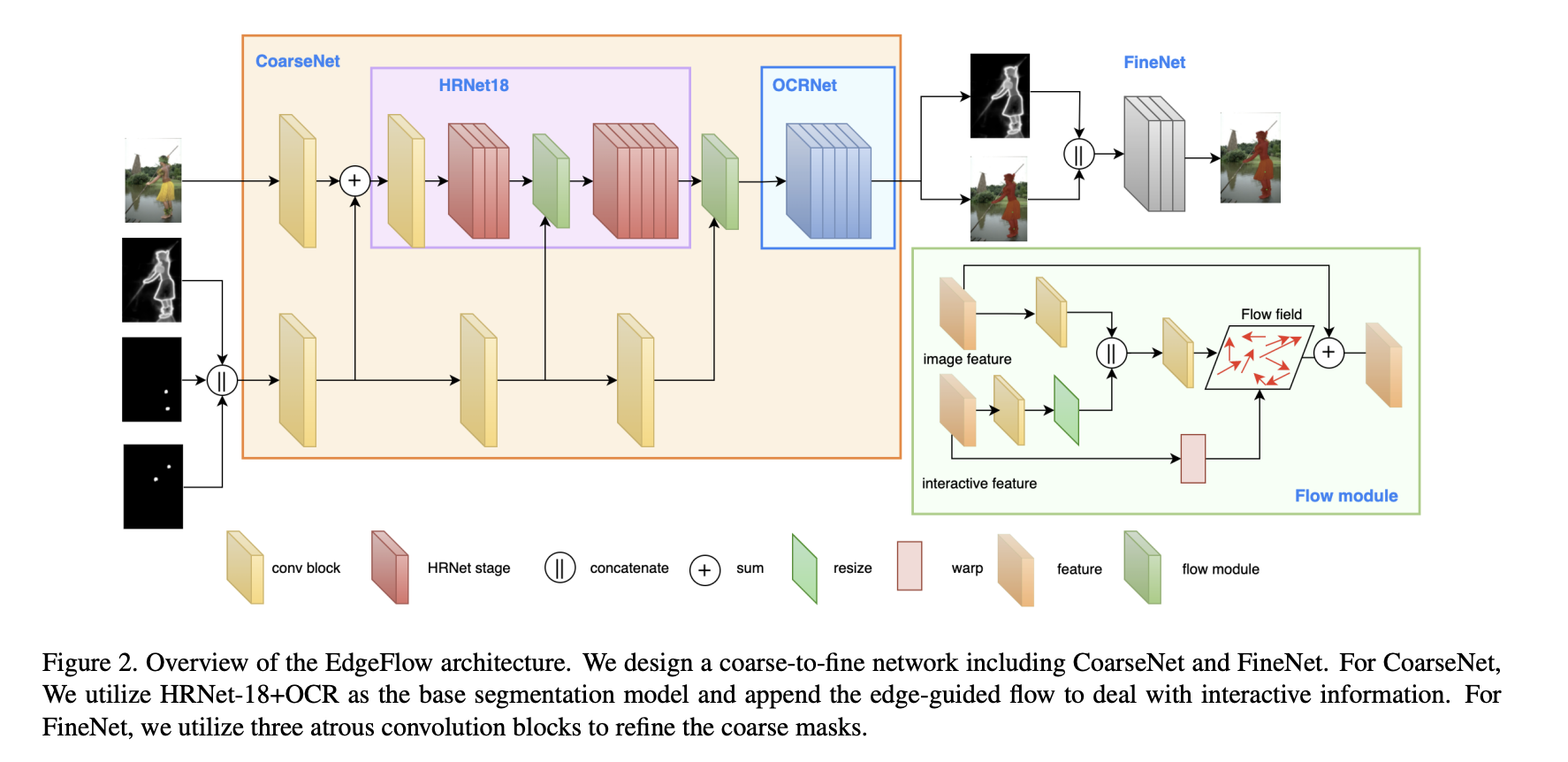
利用 HRNet-18 作为主干和 OCRNet 作为分割头
早晚融合:
- 在骨干网络之前融合了交互和图像特征,这就是所谓的早期融合。早期的融合方法普遍存在交互信息提取不正确的问题。交互特征比图像特征稀疏得多,并且包含高级信息,例如 位置信息。骨干网的早期层侧重于低层特征提取,因此交互特征会通过早期层被稀释,网络无法及时响应用户点击。
- 为了防止特征稀释,作者提出了一种早晚融合策略来整合交互和图像特征。作者设计了多阶段特征融合,而不是仅在网络开始时融合特征
边缘掩码方案,
- 全掩码可能会使模型陷入局部最优
- 该方案将前一次迭代估计的对象边缘作为先验信息,而不是直接掩码估计。边缘估计比输入的全掩码更稀疏且波动更小,因此可以提高分割的稳定性和效率。
- 在交互式分割模型中,交互图像和边缘掩模特征是异构的,导致空间偏差很大。因此,有必要正确对齐这些。光流方法最初用于对齐视频中两个相邻帧的特征。在语义分割中,它对多尺度特征对齐同时融合不同层是有效的。受的启发,作者采用流模块来对齐图像和交互特征,以便可以精确表示空间信息。
RITM
【论文阅读】Reviving Iterative Training with Mask Guidance for Interactive Segmentation-CSDN博客
《Reviving Iterative Training with Mask Guidance for Interactive Segmentation》论文笔记_m_buddy的博客-CSDN博客](https://blog.csdn.net/m_buddy/article/details/115285213?spm=1001.2101.3001.6650.4&utm_medium=distribute.pc_relevant.none-task-blog-2defaultCTRLISTRate-4-115285213-blog-114885638.pc_relevant_3mothn_strategy_and_data_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2defaultCTRLISTRate-4-115285213-blog-114885638.pc_relevant_3mothn_strategy_and_data_recovery&utm_relevant_index=6)
核心思想:
修修补补
用户每一次点击,模型都会有一个mask预测的结果,它也可以提供很多信息。由此,该文章在每一次点击之后将上一次点击预测的mask和连同click map, image一起concat成6-channel input输入模型。同时该文章还在loss, 以及模型结构,训练数据等细节上进行了很多探究。 相比与前面的文章,该论文取得了较大的提升。
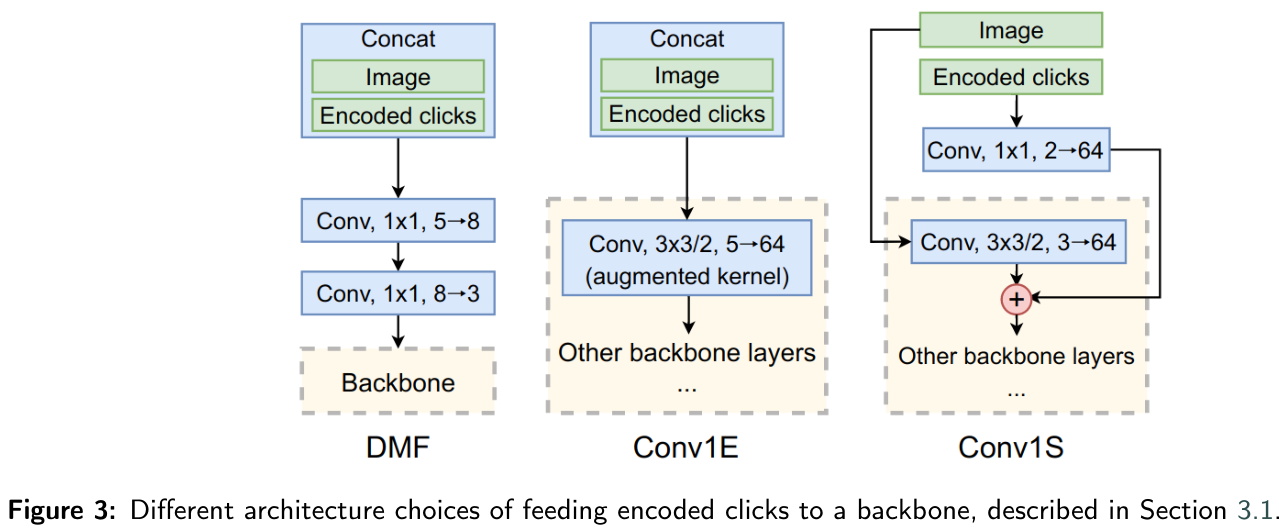
FocalClick: Towards Practical Interactive Image Segmentation (CVPR2022)
核心思想:
- 之前的方法太重了:轻量化的标注工具不希望用又慢又大的模型,如果标注人员达到一定规模。不可能给每个标注员配GPU。
- 之前的方法没有兼容性:由于每次需要将所有的点击作为输入,对mask的每个像素进行新的预测,之前的方法根本不能和其他工具配合。举个例子,对人像进行精细分割标注时, 头发的细节需要用matting工具或者手工标注。当切换到别的工具标好了头发后,就无法切回交互式分割工具了。因为一旦用交互式分割工具打一个点,之前标好的头发区域也会被完全重新预测,相当于白标。同理,之前的方法也不能在已有的略带瑕疵的掩膜上进行修改。
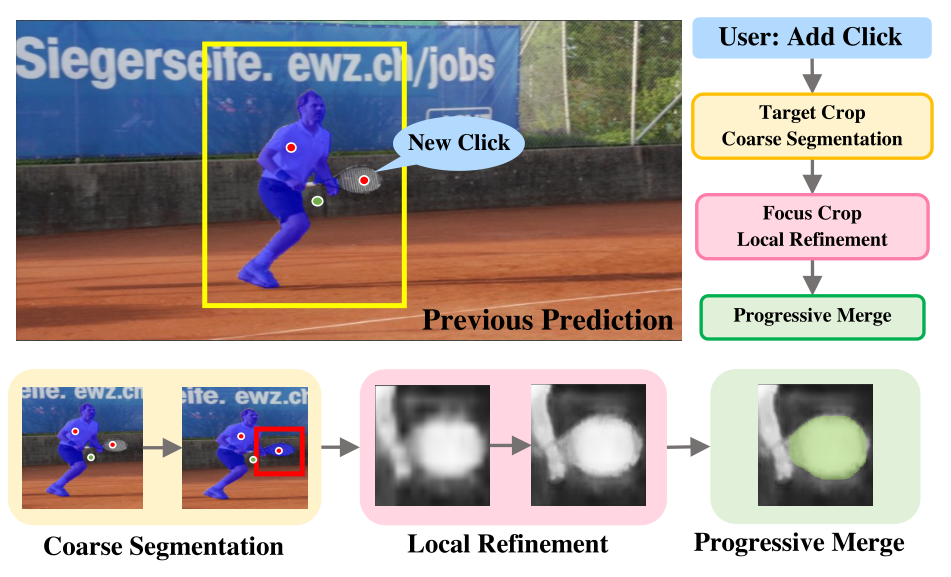
我们发现,问题就出在“每次点击后,模型会对所有像素全局重新预测”上。其实每一次点击都是有“小目标”的,如下图,这个点击在球拍上的new click的目标就是把球拍加入前景。由此,我们不需要对球员的区域进行重新预测和更改,只需要对球拍区域进行预测就好了,球员区域的预测保留。
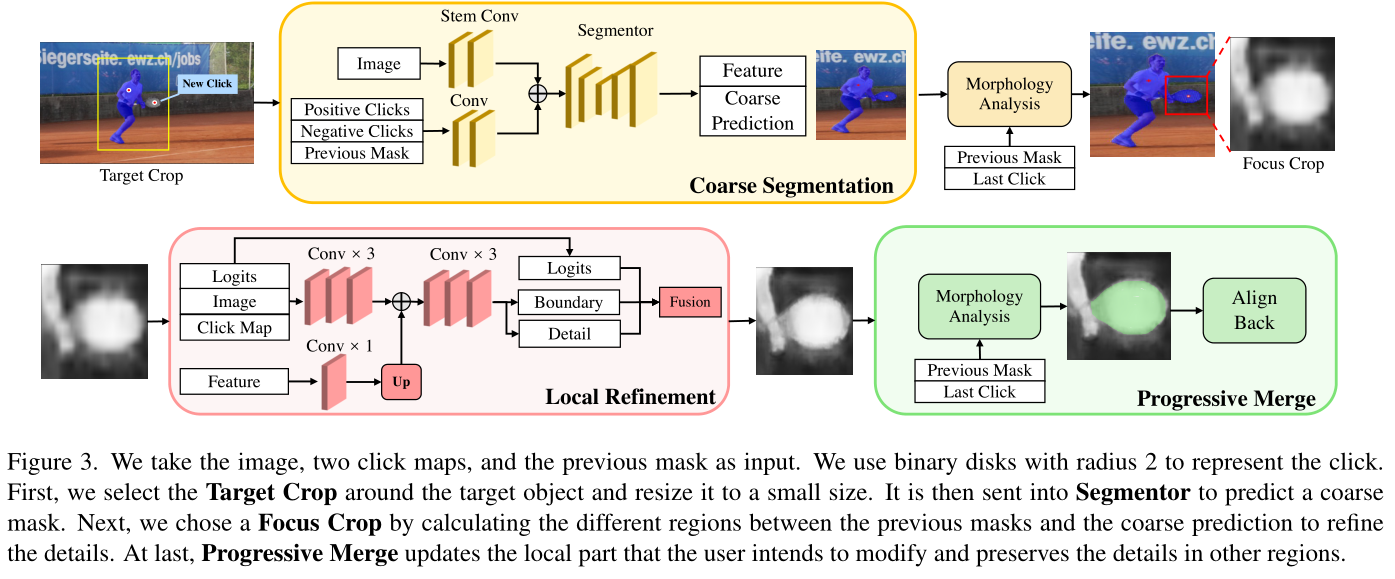
提示
新的子任务--interactive mask correction
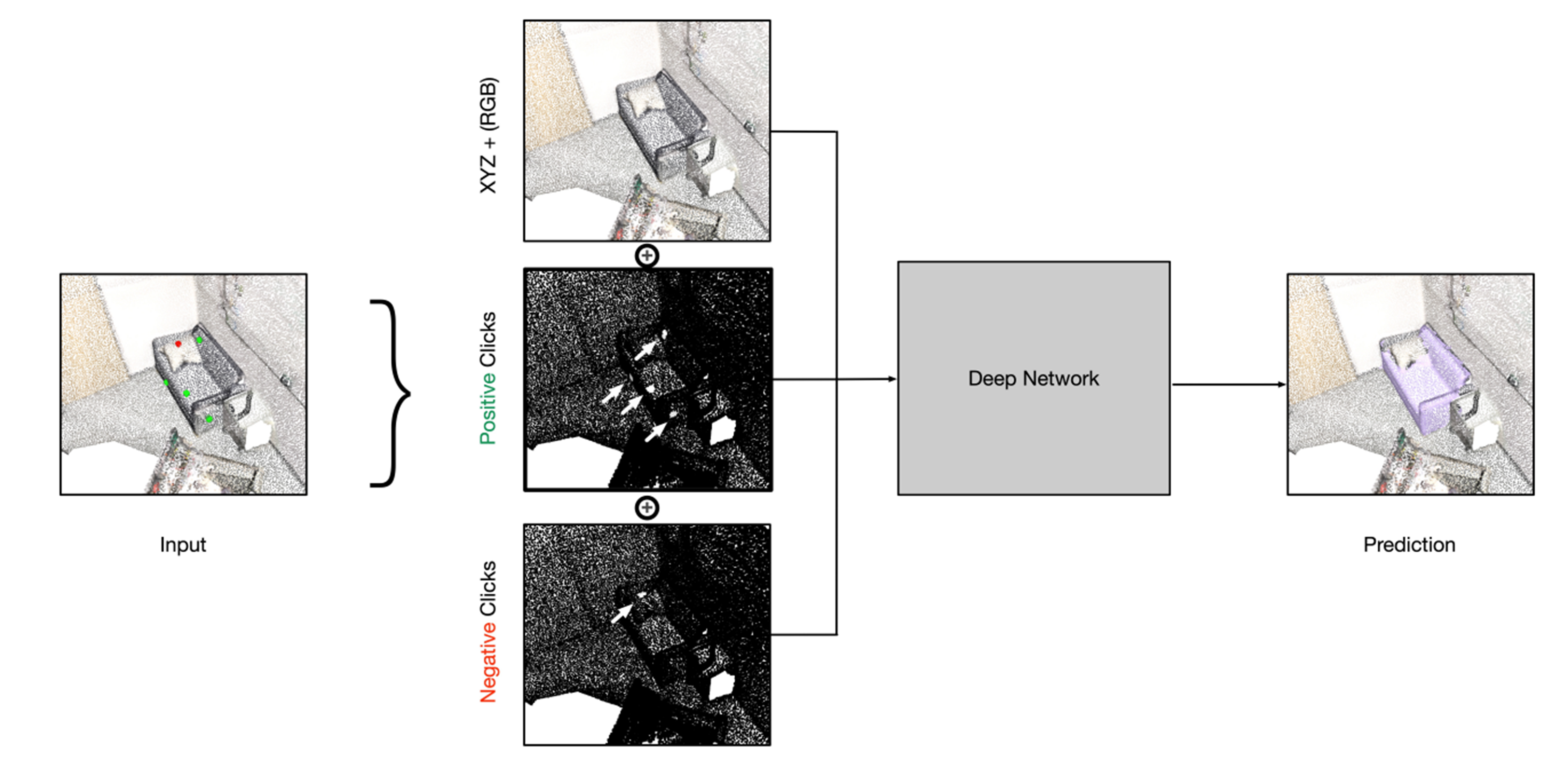
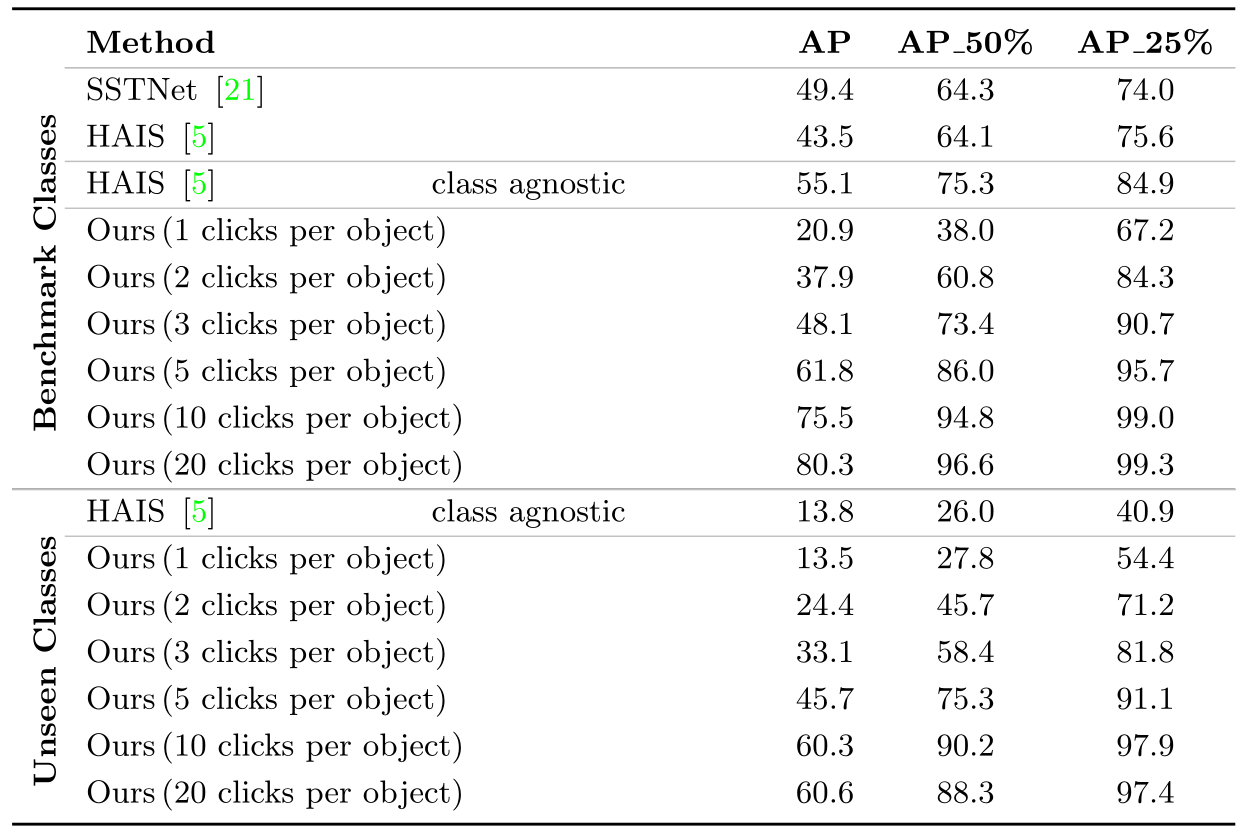
Interactive Object Segmentation in 3D Point Clouds
额外两个通道