
Semanticmap综述
摘要
智能体(例如机器人)在陌生环境中需要执行复杂的语义任务。在众多必备技能中,构建和维护环境的语义地图对长期任务至关重要。语义地图能够以结构化的方式捕捉环境信息,使得智能体在整个任务过程中能够引用它来进行高级推理。
虽然现有的具身智能综述大多集中在整体进展或具体任务(如导航、操作),但本文针对室内导航,全面回顾了具身智能中的语义地图构建方法。我们从两大维度对这些方法进行分类:
- 结构表示 —— 空间网格(spatial grids)、拓扑图(topological graphs)、稠密几何(dense geometric maps)或混合地图(hybrid maps);
- 信息类型 —— 隐式特征(implicit features)或显式环境数据(explicit environmental data)。
我们进一步探讨了不同方法的优缺点,指出当前面临的挑战,并提出未来研究方向。我们发现该领域正朝着开放词汇(open-vocabulary)、可查询(queryable)、任务无关(task-agnostic)**的地图表示发展,但**高内存需求和计算效率低下仍是尚未解决的难题。
本文旨在为当前和未来的研究者提供指导,推动语义地图技术在具身智能系统中的发展。
1 引言
智能代理,无论是物理机器人还是虚拟具身系统,都必须在复杂、非结构化的环境中运行。在这些环境中,有效行为不仅依赖于低级感知与执行,更需要形成结构化的内部表示,将感知与推理、决策过程联系起来。语义地图正是承担这一角色的关键工具,它不仅编码空间几何信息,还编码环境的高层语义(如物体类别、可供性等)。因此,语义地图在机器人学和具身智能中具有基础性地位,尤其适用于自动驾驶(Bao et al., 2023;Li et al., 2024b)、搜救任务(Gautham et al., 2023)、自动清洁机器人(Singh et al., 2023)等开放世界场景。
传统的地图构建技术侧重于几何精度,用于定位和避障。然而,随着深度学习、计算机视觉和多模态感知的进步,研究重点已转向富含语义信息的地图。尽管已有大量文献,语义地图构建仍是一个开放且快速发展的研究领域。
现有综述多将语义地图置于其下游应用背景下进行回顾,因此主要聚焦于任务本身(Pfeifer & Iida, 2004;Kostavelis & Gasteratos, 2015;Cadena et al., 2017;Xia et al., 2020;Duan et al., 2022;Deitke et al., 2022;Zhu et al., 2021;Zhang et al., 2022b;Wu et al., 2024;Lin et al., 2024;Garg et al., 2020;Achour et al., 2022;Zheng et al., 2024a)。Song et al. (2025) 最近回顾了室内机器人中的语义地图构建,但其重点在于获取的语义类型及其提取技术。
与之不同,本文提供了一个系统性的回顾,聚焦于语义地图构建方法本身,而非特定下游任务。我们从地图表示的结构出发,深入探讨其设计选择,这一视角既及时又必要,因为基础模型的进展和对通用、开放词汇、任务无关表示的需求正在快速增长。
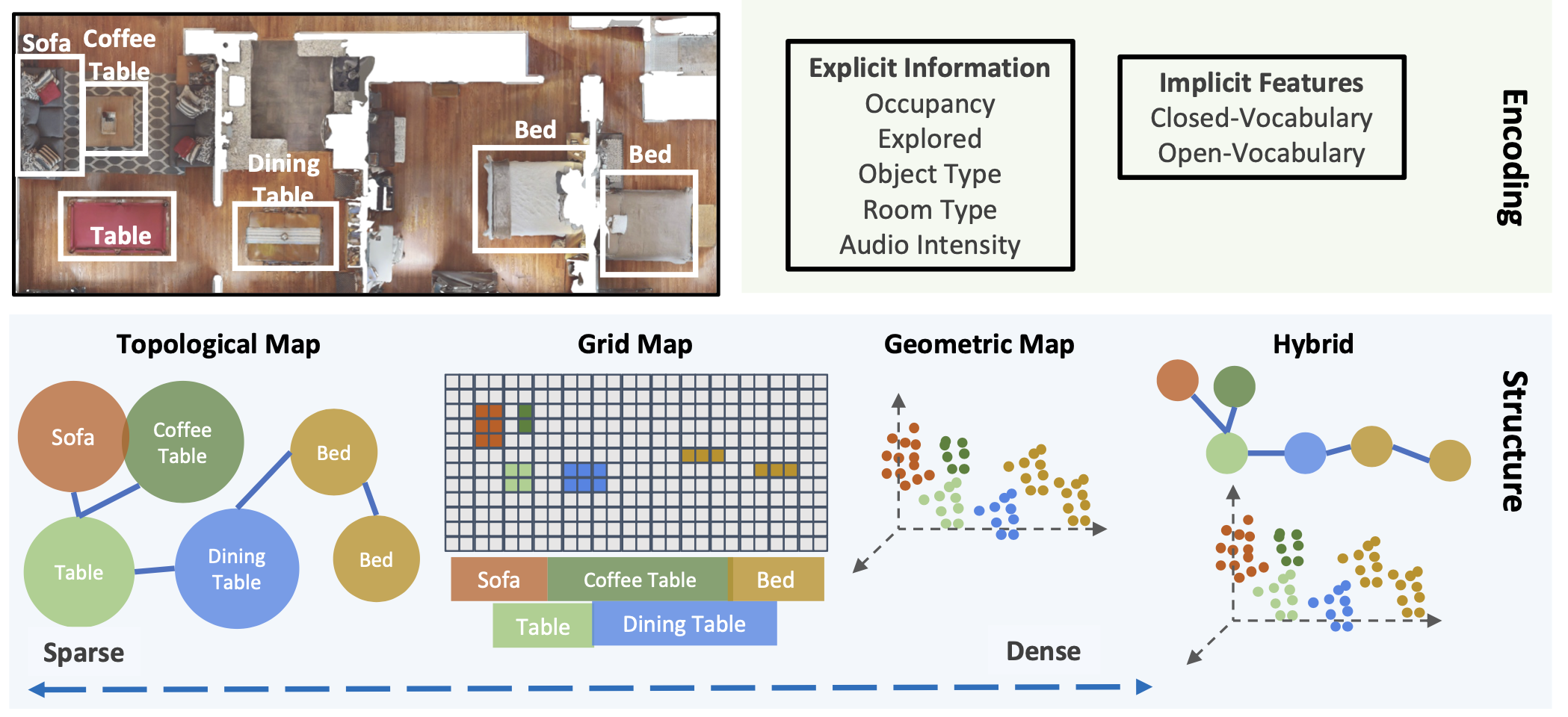
为了提供对语义地图构建方法的原则性理解,本综述沿着两个基本轴对文献进行了分类(见图1):地图结构(例如,拓扑图、空间网格、密集几何形状以及混合表示)和语义编码(显式注释与学习到的隐式特征)。这种分类反映了影响地图可扩展性、可解释性、泛化能力、多模态融合和查询的核心设计选择。通过以这种方式组织方法,我们旨在统一不同的研究方向(见表1对所综述论文的总结),突出不同表示方法之间的权衡,并呈现语义地图构建的关键挑战和未来机遇。本综述以室内移动机器人为背景,聚焦于语义地图构建方法,这一领域为研究提供了一个定义明确、实践相关且技术丰富的环境。我们专注于具身人工智能(embodied AI)中的语义地图构建,这使得能够在控制环境中将语义地图的高级推理能力与嘈杂传感器和现实世界观测的复杂性区分开来。同时,本综述还建立了与基于SLAM(Simultaneous Localization and Mapping,即同步定位与地图构建)的方法的联系,以强调它们的方法论重叠,并将机器人学中的基础技术与具身人工智能中新兴范式联系起来。
本文结构如下:
- 第 2 节 提供背景知识;
- 第 3 节 介绍语义地图及其核心组成部分;
- 第 4 节 探讨不同的地图结构;
- 第 5 节 讨论编码策略;
- 第 6 节 回顾现有的评估方法;
- 第 7 节 分析语义地图构建中的关键挑战;
- 第 8 节 展望未来研究方向;
- 第 9 节 对全文进行总结与归纳。
2 背景知识
具身任务(Embodied tasks)涉及一个智能代理,无论是物理机器人还是模拟的身体,通过其具身(传感器、执行器等)感知并与环境互动。这些任务要求代理不仅要通过视觉、语言等方式理解世界,还要在其中采取有意义的行动(例如导航或物体操纵)。在本节中,我们对机器人学和具身人工智能中探索的具身任务进行了简要概述,强调了它们作为不断发展的研究方向的演变。这有助于为我们的研究重点——语义地图构建提供背景,因为语义地图构建通常与这些具身任务一起研究。
2.1 具身任务(Embodied Tasks)
具身任务涉及一个智能体(物理机器人或虚拟体)通过自身的传感器和执行器感知并与环境交互。这类任务要求智能体不仅要理解世界(通过视觉、语言等),还要能够在其中采取有意义的行动(如导航或物体操作)。本节简要概述了机器人学与具身智能中的具身任务,并强调其作为研究方向的不断发展。这也为我们关注的语义地图提供了语境,因为它常常与具身任务结合研究。
2.1.1 机器人学任务
现代机器人时代始于 Unimate——第一台工业机械臂(Detesan & Moholea, 2024)和 Shakey——第一台移动机器人(Center, 1984)。此后,该领域不断演进,自主性与复杂推理能力日益增强。这一进程得益于多个研究方向的发展,从基础导航与避障,到涉及感知、建图与操作的复杂现实能力。早期研究聚焦于碰撞避免(Fox et al., 1997)、蒙特卡洛定位(Thrun et al., 2001)以及使机器人能在未知环境中同步定位与建图的 SLAM 框架(Thrun, 2002;Thrun & Montemerlo, 2006;Taheri & Xia, 2021)。随着传感器性能逐年提升,语义建图逐渐兴起,将物体识别和场景理解整合进空间地图(Salas-Moreno et al., 2013)。与此同时,机器人操作成为核心议题,任务包括抓取-放置、插装与物品重排。基于力控制的经典方法(Raibert & Craig, 1981;Yoshikawa, 1985)已被现代强化学习系统如 QT-Opt(Kalashnikov et al., 2018)和 Transporter Networks(Zeng et al., 2020)所补充。该领域还扩展到多任务与长程规划,要求智能体完成一系列相互关联的任务而非孤立动作。其中突出的框架是任务与运动规划(TAMP)(Garrett et al., 2020),它将高层符号推理(如“拿起杯子,打开门,把杯子放到桌上”)与低层连续运动规划(如计算关节角度与轨迹以执行这些动作)相结合,使智能体能在复杂动态环境中运行。近期趋势包括不确定性感知规划(Stachniss et al., 2005;Blanco et al., 2008a;Georgakis et al., 2022a;Carlone et al., 2013;Pan et al., 2019)、语义建图(Rosinol et al., 2020b)以及动态环境中的任务规划(Rosinol et al., 2020a)。机器人学的另一快速发展领域是自动驾驶(Guan et al., 2024;Zhao et al., 2024),其最新趋势日益依赖鸟瞰图(BEV)表示,通过端到端学习模型将多视角传感器输入转换为统一的俯视图。BEV 是一种常见的中介表示,用于简化对空间布局、障碍物、车道等语义元素的推理。基于 Transformer 的架构如 BEVFormer(Li et al., 2024c)和 BEVFusion(Liu et al., 2023b)已成为最先进的方法,能够生成空间一致、语义丰富的 BEV 地图,支持检测、规划与轨迹预测等任务。例如,LaneSegNet(Li et al., 2024b)训练端到端系统,从多视角环视图像中预测车道段。与本文讨论的语义地图不同,BEV 地图通常是短时、局部的(逐帧)表示,并专门针对驾驶场景。总体而言,机器人学的这些进展共同体现了从反应式、单任务机器人向鲁棒、通用、能在动态现实环境中自主运行的系统的转变。
2.1.2 具身智能任务
具身式人工智能(embodied AI)领域大约于 2017–2018 年开始显著兴起,其催化剂是 AI2-THOR(Kolve 等,2017)、Habitat(Savva 等,2019)等仿真环境,以及 Vision-and-Language Navigation(视觉-语言导航,VLN)(Anderson 等,2018b)、Embodied Question Answering(具身式问答,EQA)(Wijmans 等,2019a)等基准测试的发布。历史上,具身式 AI 与机器人学分道扬镳:前者更侧重于利用视觉、语言和动作,在仿真环境中与基于学习的智能体交互,而通常不依赖实体硬件。这一分歧的动机源于真实世界机器人在可扩展性和可重复性方面面临的挑战,以及在大规模条件下研究认知、规划和多模态学习的需求。广义而言,具身式 AI 定位于计算机视觉、自然语言处理与强化学习的交汇点,而经典机器人学则聚焦于控制、感知及与现实世界的物理交互。
具身式 AI 任务根据智能体与环境交互方式的不同而有所差异。大体上,可将这些任务归为三类:
- 探索任务(Exploration task,Chaplot et al., 2019):要求智能体高效地遍历环境;
- 导航任务(Navigation task,Wijmans et al., 2019b; Batra et al., 2020b):要求智能体采取行动在环境中移动;
- 操作任务(Manipulation task,Szot et al., 2021; Weihs et al., 2021):要求智能体执行交互动作以改变环境中其他对象的状态。
此外,任务还可根据提供给智能体的目标说明进一步细分,不同的说明决定了需要保留的信息粒度。以导航为例,以下几类设定尤为常见:
- PointNav(Point-Goal Navigation,Wijmans et al., 2019b):给出相对于起点的目标坐标;
- ImageNav(Image-Goal Navigation):给出目标图像(Chaplot et al., 2020b);
- ObjectNav(Object-Goal Navigation):要求导航至某一物体类别的任意实例(Yadav et al., 2022);
- MultiON(Multi-Object Navigation,Wani et al., 2020):要求按特定顺序依次导航至多个物体;
- VLN(Vision-and-Language Navigation,Anderson et al., 2018b):根据自然语言指令找到目标;
- Audio-Visual Navigation:在户内环境中导航至发出特定声音的物体(Chen et al., 2020a; Gan et al., 2019)。
根据任务类型,有时仅在地图中存储物体类别即可(如 ObjectNav),有时则需保留更细粒度的信息(如 VLN)。本综述主要关注面向导航的房间级地图构建的最新研究,因为这类方法可扩展应用于操作任务的地图构建,并可用于探索任务。
2.2 同时定位与建图(Simultaneous Localization and Mapping, SLAM)
尽管我们在第 2.1 节中简要提及了机器人学的应用,但鉴于其与语义建图——尤其是语义 SLAM(Semantic SLAM)文献——关系紧密,我们在此单独讨论同步定位与建图(SLAM)(Thrun et al., 1998a;2000;Ferris et al., 2007;Huang et al., 2011;Carlone et al., 2024)。虽然二者都致力于用语义信息丰富空间表示,但其关注范围与目的并不相同。源于机器人学的语义 SLAM 旨在构建全局一致、具备姿态信息的地图,并通过引入语义来增强定位精度、建图准确性以及长期鲁棒性;而具身式人工智能中的语义建图则更强调能够支撑高层推理与决策的表示形式,通常会抽象掉精确定位与底层传感器噪声,以换取更强的适应性。
2.2.1 SLAM 基础
SLAM(同步定位与建图)使机器人能够利用多种传感器(相机、激光雷达、惯性测量单元等)的数据感知环境,并在构建环境地图的同时,实时确定自身在地图中的位置。从数学上看,SLAM 的目标是在存在传感器噪声和运动估计误差的条件下,联合估计机器人的轨迹和环境地图。
机器人的运动可用状态转移函数建模,该函数根据上一时刻姿态和控制输入预测下一时刻姿态:
xₜ = f(xₜ₋₁, uₜ) + wₜ (1)
其中,xₜ 为时刻 t 的机器人状态,uₜ 为控制输入(如轮速里程计或 IMU 数据),wₜ 为过程噪声。
同时,机器人观测环境中的路标,其观测模型由测量方程给出:
zᵢₜ = h(xₜ, mᵢ) + vₜ (2)
其中,zᵢₜ 为时刻 t 对路标 i 的观测,mᵢ 为路标位置,vₜ 为测量噪声。
观测预测值与实际值之间的差异称为残差(误差):
eₜ(x) = zᵢₜ − h(xₜ, mᵢ) (3)
SLAM 将该估计问题形式化为非线性最小二乘优化,旨在寻找最优轨迹 x* 和路标位置 m*,以使所有测量得到最佳解释:
x*, m* = arg minₓ,ₘ Σₜ Σᵢ eₜ(x)ᵀ Ωₜ eₜ(x) (4)
其中,Ωₜ 为信息矩阵(协方差矩阵的逆),根据测量的不确定性对残差加权,即越可信的测量权重越大;eₜ(x)ᵀ 为误差 eₜ(x) 的转置,eₜ(x)ᵀ Ωₜ eₜ(x) 为加权平方误差。
在基于图优化的 SLAM 中,上述优化对应于因子图的优化(Loeliger, 2004;Dellaert et al., 2017)。因子图的节点表示机器人位姿,边表示空间约束,此时式 (4) 可写成:
x* = arg minₓ Σ_{(i,j)∈ε} ‖z_{ij} − ẑ_{ij}(x_i, x_j)‖²_{Ω_{ij}} (5)
其中,(i,j)∈ε 为位姿图中的边;z_{ij} 为节点 i 与 j 之间的相对位姿测量;ẑ_{ij} 为由当前估计得到的预测相对测量;‖·‖²_{Ω_{ij}} 为马氏距离(加权平方误差)。通过全局优化,最终得到的地图与轨迹能够最大程度地与全部带噪传感器数据保持一致。
2.2.2 SLAM 技术
主动 SLAM(Active SLAM,Ahmed et al., 2023)使智能体不再被动地随移动而制图,而是主动选择动作以同步改善地图与自身定位(见图 3 左)。典型的 SLAM 系统(Cadena et al., 2016;Pu et al., 2023)主要由前端和后端两大模块组成(见图 3 右)。
• 前端模块负责从传感器观测中提取特征、进行数据关联与特征分类;同时,它利用迭代最近点(ICP,He et al., 2017b)等算法将连续帧的观测对齐成一致的 3D 几何,并通过回环检测(loop closure,Tsintotas et al., 2022)判断当前观测是否对应曾经到访过的区域。
• 后端模块则依据前端提供的数据进行位姿优化与地图估计,并向前端反馈回环验证结果。
根据所用传感器的不同,SLAM 可分为多种路线:
– 激光 SLAM(LiDAR-SLAM,Khan et al., 2021);
– 视觉 SLAM(vSLAM),得益于廉价相机的普及与计算机视觉的进步而广泛应用。视觉 SLAM 通常借助 SIFT(Lowe, 2004)、SURF(Bay et al., 2008)、ORB(Rublee et al., 2011)等特征检测算法,从图像中提取并匹配几何特征(点、线、面)(Mur-Artal et al., 2015;Yang & Scherer, 2017;Kaess, 2015;Cai et al., 2021)。也有方法直接对像素强度进行操作(Newcombe et al., 2011b;Engel et al., 2014),从而保留图像全部信息。
– RGB-D SLAM(Newcombe et al., 2011a;Kaess et al., 2012;Endres et al., 2013;Whelan et al., 2016)使用可同时获取彩色图与深度图的 RGB-D 相机。
– 视觉-惯性 SLAM(Visual-Inertial SLAM,Mur-Artal & Tardós, 2017;Cheng et al., 2021)进一步引入 IMU 传感器,以缓解单靠相机带来的图像模糊与光照不足问题。
2.2.3 语义 SLAM
尽管 SLAM 系统中的几何地图足以支持简单导航与控制(Shan et al., 2020b;Campos et al., 2021),却难以提供对环境语义内容的深入理解。随着机器人系统日益复杂,并开始在未知的非结构化动态环境中作业,对高层理解的需求催生了语义 SLAM(Semantic SLAM)。该方法在几何地图上叠加“对象、房间、可供性”等有意义的概念,弥合了现代具身智能体中感知与任务级推理之间的鸿沟。
早期做法主要通过两种方式引入语义:一是将图像特征与物体模型数据库匹配(Civera et al., 2011;Salas-Moreno et al., 2013);二是把语义与几何线索融入运动恢复结构(Structure-from-Motion)(Bao & Savarese, 2011;Bao et al., 2012)和 SLAM 优化流程(Fioraio & Di Stefano, 2013)。
随着深度学习发展,近期语义 SLAM 研究(McCormac et al., 2017;Yin et al., 2020)在语义表达、实时性能以及动态环境建模方面均有显著提升。部分工作表明,语义地图能够提升 SLAM 各模块的性能(Xiang & Fox, 2017;Tateno et al., 2017;Qin et al., 2021;Qian et al., 2021);另一些工作则利用 SLAM 施加的一致性约束来改善语义分割精度(Mozos et al., 2007;Lai et al., 2014;Pronobis & Jensfelt, 2012;Pillai & Leonard, 2015;Cadena et al., 2015)。还有大量研究将 SLAM 与语义分割整合为联合框架,同时提升建图与物体识别效果(Flint et al., 2011;Bao et al., 2012;Hane et al., 2013;Kundu et al., 2014;Sengupta & Sturgess, 2015;Vineet et al., 2015)。
此外,与具身式 AI 中的语义建图类似,语义 SLAM 研究也可依据语义地图的“结构”与“编码方式”进行分类。例如:
• 结构层面
– 稀疏表示:仅保留少量关键几何-语义元素(Bowman et al., 2017;Yang & Scherer, 2019;Nicholson et al., 2018;Chen et al., 2020d;Shan et al., 2020a;Atanasov et al., 2018;Feng et al., 2019;Salas-Moreno et al., 2013)。
– 稠密表示:对空间进行逐像素/逐体素级填充(Rosinol et al., 2021;Grinvald et al., 2019;McCormac et al., 2018;Chen et al., 2019b;Maturana et al., 2018;Miller et al., 2021;2022)。
• 编码层面
– 显式概念:直接在地图中存储可解释的高层概念,如“房间”(Pronobis & Jensfelt, 2012)或“物体”(Pillai & Leonard, 2015)。
– 隐式特征:用神经网络的连续潜向量表示语义信息(Xiang & Fox, 2017;Tateno et al., 2017;Qin et al., 2021;Shah et al., 2023;Maggio et al., 2024;Werby et al., 2024)。
在全文后续章节中,我们将以上述具身式 AI 语义建图的分类体系为基准,对这些语义 SLAM 工作重新梳理与归类。
如需更全面、深入地了解 SLAM 及语义 SLAM,读者可参考以下综述论文:Thrun (2003)、Kostavelis & Gasteratos (2015)、Cadena et al. (2017)、Younes et al. (2017)、Taketomi et al. (2017)、Landsiedel et al. (2017)、Saputra et al. (2018)、Sualeh & Kim (2019)、Chen et al. (2020c)、Lluvia et al. (2021)、Taheri & Xia (2021)、Tourani et al. (2022)、Pu et al. (2023)、Racinskis et al. (2023)、Sousa et al. (2023)、Wang et al. (2024) 以及 Chen et al. (2025)。
2.3 系统设计策略
为具身智能体设计系统时,必须在==“端到端学习”与“模块化流水线”==这两种基本架构之间做出选择。
端到端方法用单一神经网络将原始感知输入直接映射为动作;
模块化系统则把任务拆分成若干可解释的子模块。
理解这一区别对于把语义建图置于更宏大的系统设计框架中至关重要,因为它决定了地图如何构建、表示与利用。本节简要概述这两种范式(第 2.3.1 节与第 2.3.2 节),并在第 2.3.3 节讨论二者之间的权衡,为后文即将介绍的建图方法提供背景。
2.3.1 端到端方法
在具身智能与机器人学领域,利用强化学习(RL)训练任务专用的端到端模型已取得显著进展(Tai et al., 2017)。这类模型直接从视觉观测中一次性输出离散动作(Wani et al., 2020)或连续动作(Kalapos et al., 2020)(参见图 4)。它们通常依赖非结构化的记忆机制,如 LSTM(Mei et al., 2016;Dobrevski & Skočaj, 2021)。然而,这种表示缺乏对三维空间与几何的显式推理,在长期路径规划上表现不佳。
为此,研究者提出在端到端框架中引入中间地图表示。该地图可通过可微分操作构建,从而支持梯度回传、端到端训练。Gupta et al. (2017) 表明,用这种方式构建的以自我为中心的地图可同时提升 PointNav 与 ObjectNav 性能;Henriques & Vedaldi (2018) 则利用全局地图完成定位任务。上述方法采用监督学习,而 Wani et al. (2020) 进一步利用 RL 在全局中间地图上直接预测动作,以解决复杂的 MultiON 任务。
在自动驾驶与路径规划领域,端到端方法尝试将原始传感器输入(图像、激光雷达等)直接映射到控制输出或运动轨迹。这类方法常借助基于 Transformer 的架构(Lin et al., 2022),在单一框架内联合建模感知、空间推理与决策。通过整体优化整个流水线,它们在复杂动态环境中展现出更强的鲁棒性与效率。近期研究显示,这类模型能够隐式地推理障碍物、目标及交通模式。然而,可解释性、泛化能力和安全验证仍是主要挑战。
无论采用何种地图表示或训练方式,一旦任务定义发生变化,这些端到端模型都需重新训练;甚至连完成该任务所需的基本技能也必须从零开始学习。
2.3.2 模块化流水线
另一条研究路线则尝试将复杂的导航任务拆解为一组 可复用的基础技能,使智能体可以先独立习得这些技能,再在不同任务间灵活调用,而无需每次都从零训练。
• 一些工作采用 双模块 结构:一个高层决策模块负责宏观策略,一个低层规划模块负责具体运动(Bansal et al., 2020)。
• 另一些工作(Chaplot et al., 2019, 2020a;Gervet et al., 2023;Raychaudhuri et al., 2023)则进一步细分为 视觉编码器(visual encoder)、建图器(mapper)、探索器(explorer)及低层规划器等多个子模块。
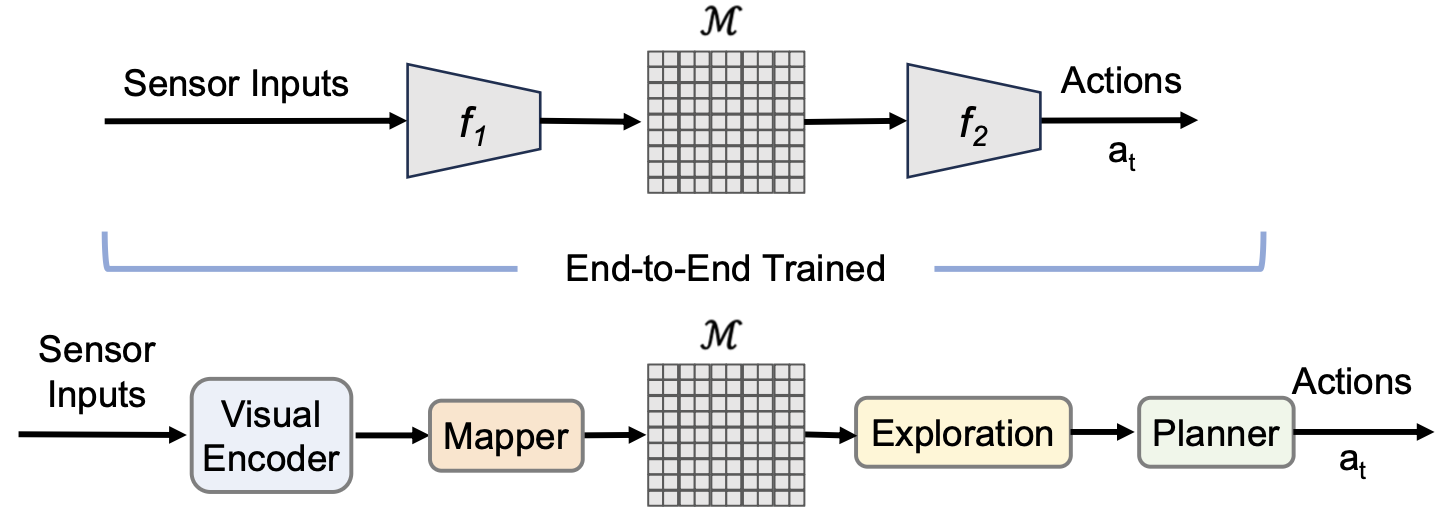
图 4 直观地对比了端到端方法与模块化方法的区别;接下来,我们将详细阐述这些子模块的职能及常见设计选择。
视觉编码器(Visual Encoder)
该模块在每个时间步将智能体的观测编码成语义视觉特征与预测。早期工作通常采用预训练骨干网络(如 ResNet He et al., 2016 或 ViT Dosovitskiy et al., 2020)提取视觉特征,并配合 Mask R-CNN He et al., 2017a 或 Faster R-CNN Ren et al., 2015 等目标检测器。正如第 5.2.2 节所述,随着大规模视觉-语言预训练模型和开放词汇检测器的出现,CLIP Radford et al., 2021、LSeg Li et al., 2022、DINO Caron et al., 2021; Oquab et al., 2023 等预训练模型日益成为构建开放词汇地图的基础。视觉编码器的选择决定了特征中包含的信息类型,以及是否能够获得可用于后续建图模块的实例级边界框或分割掩码。
建图器(Mapper)
建图器负责利用编码后的图像特征与智能体位姿,构建环境的语义地图。为随时间累积全局地图,建图器通常将当前地图与上一时刻地图进行聚合(详见第 3.4 节)。本文系统梳理了近期方法如何组织地图结构(第 4 节)以及在地图中编码何种信息(第 5 节)。表 2 总结了各类方法在地图中存储的信息类型,例如占用信息、已探索区域或检测目标的语义标签。
探索模块(Exploration)
该模块使智能体能够高效探索环境,以确保地图完整(最大化覆盖面积)或选择最可能包含目标的新区域。通常,探索模块会依据建图器生成的障碍地图及当前位姿,选定一个待探索的点或区域。
简单启发式方法包括:
• 均匀随机采样一个点(Zhang et al., 2021; Raychaudhuri et al., 2023);
• 以智能体为中心的系统网格四角采样(Luo et al., 2022);
• 从未探索前沿(frontier)中选取(Yamauchi, 1997)。
决定具体前沿点时,可采用以下策略:
• 距智能体最近点(Gervet et al., 2023);
• 基于语义推理的最有前景点。在语义推理方法中,智能体可选择预训练大视觉-语言模型(如 BLIP-2 Li et al., 2023)给出的最高文本-图像相关性得分(Gadre et al., 2023; Yokoyama et al., 2023),或直接采用 VLM 的最高概率输出(Ren et al., 2024),也可利用 LLM 抽取常识知识(Zhou et al., 2023)。
此外,研究者还训练了学习式策略(Chaplot et al., 2019; 2020a),通常以覆盖奖励(Chen et al., 2019a)或好奇心奖励(Pathak et al., 2017; Mazzaglia et al., 2022)进行强化学习。尽管学习式方法减少手工规则,却需数百万训练步及精心设计的奖励函数。
规划器(Planner)
地图建成后,低级路径规划模块负责从当前位姿到目标位姿规划可行路径,路径由智能体可直接执行的低级动作序列组成。多数先前工作采用启发式 Fast Marching Method Sethian, 1996;最近 MOPA Raychaudhuri et al., 2023 则使用离线 DD-PPO 训练的学习式 PointNav 策略 Wijmans et al., 2019b。
表 2 比较了常见模块化方法在四大模块中采用的启发式或学习式策略。模块化流水线的优势在于:能复用其他任务的预训练模型(Gervet et al., 2023; Raychaudhuri et al., 2023),并更容易从仿真迁移到真实机器人(Gervet et al., 2023)。
2.3.3 权衡
两种设计方案各有利弊。
• 端到端系统训练与部署简单,可直接优化任务性能;但可解释性差,泛化能力弱,且难以复用已有组件。
• 模块化流水线透明度高、组件可复用,且能灵活结合学习式与传统方法,因而更适用于需要长时规划与语义推理的复杂任务;其不足之处在于可能出现误差传播以及模块间集成不够最优。
3 语义地图
在本章中,我们介绍什么是语义地图(第 3.1 节),并概述其结构表示(第 3.2 节)、语义编码(第 3.3 节)以及构建过程(第 3.4 节)。
3.1 什么是语义地图?
仅有几何地图可以帮助智能体避开障碍物,却不足以应对更高阶的推理任务。人类之所以能够高效地在环境中感知与导航,正是因为我们不仅记录空间形状,还赋予其意义与上下文。语义地图正是这样一种超越几何、承载含义与情境的增强地图:它对环境中的物体与场所提供更丰富、细腻的认知,是完成复杂任务的关键——例如导航到特定房间(如厨房)(Narasimhan et al., 2020)、重新摆放物体(Trabucco et al., 2022),或对特定物体执行动作(如坐到沙发上)(Peng et al., 2023)。
无论是物理还是虚拟智能体,均通过传感器(相机、激光雷达等)感知环境,并借助认知能力对所见物体与区域进行分类(Ren et al., 2015;He et al., 2017a;Liu et al., 2024;Kirillov et al., 2023;Zhang et al., 2023b),随后将这些语义信息存入结构化的语义地图中,以供高效查询与推理。
3.2 地图的结构是什么?
语义地图可按结构划分为空间网格地图、拓扑地图、稠密几何地图以及它们的混合形式(见图 1)。
• 空间网格地图(spatial grid map)
采用俯视的离散网格,每个单元格(cell)对应物理环境中的一块区域。若某物体在 3D 场景中的位置为 (X,Y,Z),则在 2D 语义地图中,该物体的信息会被写入对应的网格单元 (x,y),其中 x、y 为行列索引,映射关系为 (X,Y,Z) → (x,y)。为了导航,多数空间地图仅用 2D 网格,即沿 Z 轴(高度方向)聚合语义信息并忽略其具体值;也可将 Z 轴离散化为若干高度槽,构建 3D 网格。
• 拓扑地图(topological map)
以图结构呈现:节点表示场景中的物体或关键地标,边表示它们之间的关系(距离、空间关系等)。
• 稠密几何地图(dense geometric map)
可视为带有可变密度的 3D 地图。与规则体素网格不同,稠密几何地图在每个 3D 点 (x,y,z) 上存储信息,这些点与物理空间中的 (X,Y,Z) 一一对应,且采样密度可以随场景复杂度而变化。
• 混合地图(hybrid map)
鉴于上述结构各有所长,一些研究将两种或多种结构结合,形成混合地图,以取长补短。我们将在第 4 节详细讨论每种结构。
3.3 地图中存储什么样的编码?
语义地图针对物理世界中的某一三维位置 (X, Y, Z) 存储两类信息:显式编码与隐式编码。
• 显式编码:每个值都有明确、单一的语义。例如,单元格 (X, Y, Z) 可记录该位置是否存在障碍物、是否已被智能体探索、该点物体的类别等。
• 隐式编码:通过在该位置观测到的感官输入(如图像)提取特征向量,保存为潜层表示。这些特征通常来自预训练编码器。若编码器仅针对有限类别图像训练,则得到 封闭词汇(closed-vocabulary)特征,只能识别预设类别;若编码器基于大规模互联网图文数据训练,则得到 开放词汇(open-vocabulary)特征,理论上可以识别“任意”物体。
3.4 地图是如何构建的?
构建精确且详尽的语义地图需要将来自相机、激光雷达、深度传感器等多种来源的数据进行整合。具体而言,建图过程要求智能体在空间中移动,并把时刻 t 的观测 Oₜ 累积到对应地图结构 mₜ 中(参见图 5)。为了得到准确的地图,智能体首先需要知道自己的位置(定位),然后从观测中提取语义信息 F(Oₜ)(特征提取),并随时间将这些特征合并到同一张地图中(累积)。在构建空间网格地图时,还需增加一步——将特征投影到网格(投影)。后三步常被合称为“建图”,并通常与定位一起在“同步定位与建图(SLAM)”框架内统一研究(第 2.2 节已简要介绍 SLAM)。
定位
由于传感器与执行器存在噪声,定位本身颇具挑战。为简化问题,具身智能社区通常采用两种假设:
- 每一步都提供完美位姿(Cartillier et al., 2021);
- 以回合起始点为基准,通过相对位移定位(Henriques & Vedaldi, 2018)。后者更易于迁移到真实场景,因为它不要求绝对位姿,只需知道相对于起点的位移即可最终建成地图。
特征提取
特征提取是语义建图的核心环节。理想情况下,这些特征应能充分表征地图中的物体。我们将在第 5 节深入讨论此主题。
投影
构建空间网格地图时,必须将 2D 观测投影到 3D 空间。通常需要深度信息及已知的相机参数,将 2D 像素坐标转换为 3D 世界坐标。具体步骤如下:
- 从相机中心出发,通过像素 pᵢⱼ 发射光线,到达对应深度 dᵢⱼ,得到相机坐标系下的 3D 点;
- 将相机坐标转换到世界坐标 (X, Y, Z)。
对于标准针孔相机,已知相机姿态(3D 旋转 R 与平移 t)及内参 K,可表示为:
⎡X Y Z⎤ᵀ = dᵢⱼ R⁻¹ K⁻¹ ⎡i j 1⎤ᵀ − t (6)
正交投影则可写为:
⎡x y 0 1⎤ᵀ = Pᵥ ⎡X Y Z 1⎤ᵀ (7)
其中 Pᵥ 为将 3D 世界坐标映射到 2D 网格索引的正交投影矩阵。若多个点落在同一网格单元,则通过聚合函数(如平均、投票、最大值等)合并其特征或预测。
累积(Accumulation)。在地图更新时,把当前观测的特征或预测融合进已有地图,常见做法有三类:
- 直接覆盖:mₜ ← mₜ′;
- 数学运算:如取最大值 mₜ ← max(mₜ, mₜ′) 或平均值 mₜ ← mean(mₜ, mₜ′);
- 学习式聚合:使用可学习的神经网络,例如用 GRU mₜ ← GRU(mₜ, mₜ′) 或 LSTM 进行融合。
建图过程中还需考虑其他关键维度:
自我中心 vs 全局中心(egocentric vs allocentric)
可选择以自我为中心的坐标系(如 +y 总是智能体前方),或采用全局坐标系(世界坐标)。已访问区域追踪
为保证地图完整,需要记录哪些位置已到访、哪些尚未探索。不过,某些具体任务无需完整地图即可完成。视角选择
具身场景下,智能体只能按顺序在有限视角下观测并累积信息;而非具身系统可先收集全部观测再统一处理。在线 vs 离线建图
• 离线:先探索环境、建好完整地图,再执行任务。节省任务阶段计算,但需额外探索时间;若环境变化,静态地图与实际状态可能失配,导致任务失败。
• 在线:在任务过程中实时建图或更新地图,始终保持最新状态,适用于首次进入、无法预先探索的场景(如搜救)。
真实世界中的建图
在具身智能任务里,仿真环境中构建的地图往往因过于理想化的假设而噪声大,难以直接迁移到真实场景。目前社区多将建图视作解决高层推理任务的一个子模块,因而研究者更关注“什么地图对什么任务有用”。为此,他们把“传感器噪声”问题从建图流程中剥离出来单独处理。最突出的假设包括:
- 无噪声传感器
• 完美定位:假设智能体在导航全程都能精确知道自己的位置和朝向——这在室内往往无法依赖 GPS,而罗盘也噪声大。
• 完美执行:假设“前进 25 cm”就能精确到位,实际地面摩擦差异会导致漂移。
SLAM 系统则根本不依赖 GPS,而是凭借机载传感器实时估计位姿,并显式建模不确定性。其中“回环检测”子算法可识别曾到访的位置,从而纠正累积误差。总体而言,SLAM 在真实环境中的建图更为一致、准确,远胜于当前具身智能中常用的建图技术。
4 地图结构
本节将深入探讨先前工作中采用的各种地图结构(详见表 1)。语义地图可按以下四种方式组织:空间网格地图、拓扑地图、稠密几何地图以及它们的混合形式。
• 空间网格地图(spatial grid map)
是一种度量地图,其维度与真实环境对齐,可构建为 2D 或 3D 网格。
• 拓扑地图(topological map)
用图结构表示环境:节点对应关键地标,边表示相邻地标之间的关系。
• 稠密几何地图(dense geometric map)
是最稠密的 3D 形式,三个维度均与实际 3D 空间对齐,场景中每一个 3D 点都被记录。
• 混合地图(hybrid map)
将上述两种或多种结构组合,以兼顾各自优势。
4.1 空间网格地图
空间网格地图 mₜ 可表示为形状 (M × N × K) 的三维张量,其中 M、N 为地图的平面尺寸,K 为存储该位置语义信息的通道数。每个单元格对应现实世界中一块固定大小的区域。当前室内具身智能研究普遍采用 Matterport3D(MP3D)(Chang et al., 2017)和 Habitat-Matterport3D(HM3D)(Ramakrishnan et al., 2021)这类真实场景的 3D 重建数据集;HM3D 场景数量约为 MP3D 的 10 倍,视觉保真度更高、重建伪影更少,场景多为总面积 ≤1000 m² 的住宅或办公空间。经验表明,单元格边长 20–30 cm(400–900 cm²)即可充分描述这类环境(Wani et al., 2020;Raychaudhuri et al., 2023)。每回合开始时,空间地图初始化为空张量 (M × N × K),随着智能体移动逐步填充。大多数方法采用 2D 俯视图(Gupta et al., 2017;Henriques & Vedaldi, 2018;Narasimhan et al., 2020;Cartillier et al., 2021),前两维对应环境平面尺寸;少数工作为捕捉高度信息而构建 3D 网格,此时 mₜ 为四维张量 (M × N × P × K)。
根据是否先做语义分割,空间地图可有不同构建方式(见图 7)。
• 直接投影法:如 CMP(Gupta et al., 2017)将图像经 ResNet 等编码器提取特征后,学习一个以自我为中心的投影,把特征直接映射到 egocentric map。该映射无需显式监督,而是与规划器一起端到端训练。
• 局限性:egocentric map 无法保留全局结构,且“遗忘”历史观测,在长时程任务中效率明显不足。
为了维护一张全局(allocentric)地图,必须将每一时刻的以自我为中心(egocentric)信息逐步累加到全局坐标系中。最常见的做法是:
- 先把图像特征投影成 egocentric 的俯视图;
- 通过“配准(registration)”将其对齐到全局栅格。
配准决定新观测落在哪些栅格单元;若单元已占用,则用聚合函数(取最新、平均或学习网络,见 3.4 节)与旧信息融合。
MapNet(Henriques & Vedaldi, 2018)按此流程实现:
• 用深度和相机内参把 egocentric 图像特征投影到 2D 俯视栅格,得到相机邻域的局部地图;
• 将该局部地图旋转 r 次,形成 r 张 egocentric 特征图;
• 用卷积实现与上一步 allocentric 地图的稠密匹配,从而估计当前位姿;
• 用 LSTM 把按当前位姿旋转后的观测与上一时刻的 allocentric 地图聚合。除 LSTM 外,也可使用其他网络结构(表 3 汇总了不同工作的聚合方式)。
另一种做法:
• 先用内参把像素反投影到相机坐标系 3D 点;
• 再用相机位姿转到世界坐标系;
• 最后体素化并沿高度求和投影到 2D 栅格。
Semantic MapNet(Cartillier et al., 2021)和 MOPA(Raychaudhuri et al., 2023)采用此策略。由于传感器噪声,如此生成的地图可能含噪:Semantic MapNet 用可学习的去噪网络,MOPA 则用启发式(取聚类中心)得到干净地图。进一步,Semantic MapNet 指出:先编码图像→投影到地面→在 2D 地图做分割,可减少噪声,省去额外去噪步骤。
无论哪种方法,多个图像特征可能落在同一栅格。常见聚合策略有:取最大(Henriques & Vedaldi, 2018; Wani et al., 2020; Cartillier et al., 2021)、平均(Huang et al., 2023a)或求和(Chaplot et al., 2020a)。
小结
空间网格地图能捕获环境的稠密信息,便于智能体推理空间结构。但其需要预设固定宽高,环境尺寸变化时难以扩展;且占用内存大,可能影响任务性能。
4.2 拓扑地图
与高精度网格地图相比,拓扑地图采用图状结构:节点代表关键区域,边代表区域间的可通行路径。它将大尺度环境抽象为“局部可决策的小区域 + 区域间的全局连接”,使智能体可在节点内局部规划、沿边全局搜索,模拟人类在陌生环境中“记住地标—找路”的导航方式(Janzen & Van Turennout, 2004;Foo et al., 2005;Chan et al., 2012;Epstein & Vass, 2014)。在指令跟随任务中,语言指令常被表示为初始不确定的图,机器人通过移动观测、用概率模型更新此图,从而提升任务表现(Tucker et al., 2019;Patki et al., 2019;Arkin et al., 2020a;Raychaudhuri et al., 2025)。因此,拓扑地图在传统机器人(SLAM:Thrun & Montemerlo, 2006;Rosinol et al., 2020b;Campos et al., 2021;操作:Arkin et al., 2020b;Patki et al., 2020;目标搜索:Aydemir et al., 2011, 2013;Lorbach et al., 2014;语言接地:MacMahon et al., 2006;Chen & Mooney, 2011;Tellex et al., 2011a;Matuszek et al., 2013;Duvallet et al., 2013;Gong & Zhang, 2018;Paul et al., 2018)及具身智能研究(Savinov et al., 2018;Chen et al., 2021;Chaplot et al., 2020b;Kwon et al., 2021;Gu et al., 2024;Mehan et al., 2024;Garg et al., 2024;An et al., 2024;Yang et al., 2024;Tang et al., 2025)中均得到广泛使用。
拓扑地图设计的关键在于“节点”与“边”的选取。
• 节点一般编码可供智能体决策的位置语义信息,常见形式包括:环境中的物体、门口/交叉口(Fredriksson et al., 2023)、已访问位置(Chaplot et al., 2020b)或其他兴趣区域(Kim et al., 2023;Shah et al., 2023;Garg et al., 2024)。
• 边表示节点间的可达关系;若两节点间可导航,则建立一条边。有些方法还在边中存储节点间的空间关系,以支持更精细的推理(Gu et al., 2024)。
一种构建拓扑地图的方式(见图 7)是在正式任务前进行“预探索”阶段,然后利用该图规划到最相似目标节点的路径,例如半参数化拓扑记忆(SPTM)(Savinov et al., 2018)。在探索阶段,智能体在每个环境中沿多条随机轨迹行走:每到一个新位置就创建节点,并与上一个节点连边,以编码可达性。后续通常会剪枝冗余节点与边,得到稀疏图(Chen et al., 2021)。若同一环境由多条轨迹生成多个子图,则需合并成一张大图。然而,这种离线生成的拓扑图依旧稀疏,可能遗漏部分观测,影响下游任务表现;且需要预探索,难以应对未见环境。
为解决这一问题,一些方法改为 在线构建拓扑图,即在执行任务的同时逐步扩建图,如 Neural Topological SLAM(NTS)(Chaplot et al., 2020b)。NTS 包含三大模块:
- “图更新(Graph Update)”:根据当前观测与位姿实时增删节点与边。
- “全局策略(Global Policy)”:在图上采样子目标节点。
- “局部策略(Local Policy)”:输出离散导航动作,前往子目标。
“图更新”流程如下:
• 先尝试将当前帧定位到上一时刻的图中节点。
– 若定位成功,则在当前节点与上一节点之间添加边,并记录相对位姿 (r, θ),r 为相对距离,θ 为相对方向。
– 若定位失败,则在图中新增一个节点。
在拓扑地图的构建过程中,一个关键环节是判定“何时把两次观测视为同一节点”——即判断两张 RGB 图像是否足够相似。若相似,则映射到同一节点;否则新建节点。传统上,这属于 SLAM 中的数据关联(data association)问题:当新观测到达时,需在众多地标(节点)中找到最佳匹配,或创建新地标(Bowman et al., 2017;Dellaert et al., 2000)。
在具身智能中,常见做法如下:
监督分类网络
NTS 训练一个 MLP,用交叉熵损失判断两张图像是否来自同一区域,但需要人工标注的正负样本对。可达性距离阈值
CMTP(Chen et al., 2021)用“可达性估计器”先计算两张图像对应位置在 3D 网格上的测地距离;若距离小于阈值,则视为同一节点,无需人工标注。无监督嵌入聚类
VGM(Kwon et al., 2021)先学习观测的无监督表示,再将其投影到嵌入空间,使邻近位置的嵌入聚集;训练数据仅为随机采样图像,无需人工标签。语义/CLIP 相似度
Kim et al. (2023) 用预训练网络(Li et al., 2021a)计算两张图像的语义相似度;LM-Nav(Shah et al., 2023)则用 CLIP 计算图像特征的余弦相似度。
表 4 对比了不同拓扑地图构建方法的具体实现。
小结
拓扑地图以节点-边形式压缩环境,构建与维护都更简洁、内存开销低,且环境扩大时只需增加节点即可扩展。然而,它们仅保存稀疏地标,缺少稠密的全局信息,在杂乱室内场景中可能遗漏对空间推理至关重要的视觉线索。
4.3 稠密几何地图(Dense Geometric Map)
语义信息也可以直接累积在场景的 3D 几何之上,常见载体包括三角网格(Valentin et al., 2013)、Surfel(Stückler & Behnke, 2014)或点云(Jatavallabhula et al., 2023)。其中,点云因实现简单、易于使用而最为普及。尽管这些表征在传统意义上不一定被视作“地图”,它们通过把几何结构与语义内容耦合在一起,实际上起到了语义地图的作用。
稠密几何表征——尤其是点云——早已在机器人学的建图、定位、导航以及更广泛的 3D 场景理解任务中被广泛采用(Peng et al., 2023;Xu et al., 2024)。近年来,研究者开始将这些表征引入具身智能,以支持下游的推理与决策(Gu et al., 2024)。
我们进一步把稠密几何语义地图划分为两大类:
• 4.3.1 点云地图:存储带有语义标签的 3D 点;
• 4.3.2 神经场:用神经网络将场景表示为连续函数。
表 5 汇总了相关先前工作。
4.3.1 点云地图
近年来,点云因其易用性而大受欢迎。给定一个 3D 点云后,可为每个点附加语义标签,从而将几何结构与语义内容紧密结合,形成稠密的语义地图。此外,还可以把每个点扩展为一个带有协方差矩阵的 3D 高斯——即所谓的高斯泼溅(Gaussian splats),实现可微渲染。点云(以及最近的高斯泼溅)已被广泛运用于各类机器人任务和 3D 场景理解任务,并在具身智能社区迅速流行。
在机器人领域,基于点云的建图技术随着传感器、计算能力与 SLAM 算法的进步而持续演进。早期工作(Nüchter et al., 2007;May et al., 2009)利用 3D 传感器扫描构建大规模环境的几何一致表示,强调精度与回环闭合。随着实时视觉 SLAM 的成熟,RGB-D 传感器的稠密点云生成变得可行,从而实现了细致的室内重建(Whelan et al., 2015;Dai et al., 2017;Schops et al., 2019;Min & Dunn, 2021)。近年来,以 Droid-SLAM(Teed & Deng, 2021)为代表的学习式 SLAM 系统,通过深度特征提取与端到端优化进一步提升了 SLAM 性能。CoFusion(Rünz & Agapito, 2017)等系统率先将语义融合引入稠密 SLAM,使地图不仅几何准确,也富含语义。最近,ConceptFusion(Jatavallabhula et al., 2023)将开放词汇视觉特征(如 CLIP)与 3D 重建对齐,生成任务无关、可查询的语义地图,标志着从纯几何地图向稠密、开放词汇、语义丰富的表征转变。
此外,高斯泼溅(Gaussian splatting)近期成为传统点云的强有力替代,在机器人中可用于高保真场景重建及可微 3D 表征,支持视觉定位、SLAM 与操作等任务。SGS-SLAM(Li et al., 2024a)将语义标签嵌入高斯泼溅以执行 SLAM;GaussianGrasper(Zheng et al., 2024b)则把语义与高斯表征融合,实现开放词汇抓取。
在具身智能中,维护稠密点云地图往往内存开销大、实时性差。为此,Zhang et al. (2023a) 提出基于在线点云构建算法的 3D 语义场景表示,借助树形动态数据结构显著降低内存占用并加速 ObjectNav 任务。Lei et al. (2025) 则利用高斯泼溅在 ImageNav 任务上取得当前最优性能。
在 3D 场景理解领域,点云因其灵活性和精细空间分辨率成为核心表征。早期的 PointNet(Qi et al., 2017a)和 PointNet++(Qi et al., 2017b)可直接处理无序点集,完成语义分割与物体分类;随后 KPConv(Thomas et al., 2019)引入可学习卷积,Point Transformer(Zhao et al., 2021)利用注意力捕获长程依赖。最新研究将多模态与语言监督融入点云理解(Peng et al., 2023;Xu et al., 2024),实现细粒度推断,如语义分割、可供性预测与 3D 物体搜索。OpenScene(Peng et al., 2023)预测稠密 3D 特征,使其与对应文本和图像在 CLIP 嵌入空间共嵌,从而可用文本查询场景中的物理属性、可供性等。CLIP2Scene(Chen et al., 2023c)同样利用 CLIP 在室外场景进行 3D 点云分割,服务自动驾驶。然而,这些方法大多按场景优化,计算开销高,难以满足具身应用的实时需求。
总结
点云地图因简洁、高保真且与传感器数据直接对应,在研究界仍广泛使用,但面临噪声处理、大规模环境扩展、动态场景下一致语义维护等挑战。未来工作需在保持效率的同时,融合多模态特征并提升对动态场景的鲁棒性。
4.3.2 神经场
神经场(Neural Fields)是一类连续函数,它们将空间坐标(有时还包含视角方向)映射到颜色、占用率或语义特征等信号。与以离散形式存储信息的点云不同,神经场把整个 3D 场景编码为紧凑、连续的函数。通常的做法是用一个神经网络(常见为 MLP)接收位置 (x, y, z) 并输出对应特征(Mildenhall et al., 2021;Mescheder et al., 2019)。训练神经场主要有两条思路:
- 蒸馏(distillation):让网络输出与预训练 2D 骨干(如 CLIP,Radford et al., 2021)特征相近的结果(Kerr et al., 2023;Qiu et al., 2024);
- 可微渲染:在渲染颜色的同时,也渲染语义,并用可微光栅化进行监督(Zhi et al., 2021;Vora et al., 2021)。
在机器人领域,近期研究(Sucar et al., 2021;Zhu et al., 2022;Rosinol et al., 2023)把神经场集成进 SLAM 系统,实现实时建图。它们能产生紧凑、高保真的 3D 重建和视图合成,但计算开销大、可解释性低,训练速度、内存需求及动态场景处理仍是挑战。相比之下,神经符号距离场(Neural SDFs)是一类专门编码“到最近表面带符号距离”的神经场,可精确表示几何,并为建图、碰撞检测和路径规划提供可微距离度量(Ortiz et al., 2022;Camps et al., 2022;Talha Bukhari et al., 2025)。
在具身智能中,代表性工作 CLIP-Fields(Shafiullah et al., 2023)利用体渲染将 CLIP 的 2D 特征与 3D 点对齐,学习场景的连续隐式表达,从而构建开放词汇、可自然语言查询的 3D 地图,无需任务专用监督。
在 3D 场景理解方面,从 NeRF(Mildenhall et al., 2021)开始,神经场逐步融入语义,支持 3D 语义分割、物体发现与场景解析(Fu et al., 2022)。近期进展(Wang et al., 2022;Kerr et al., 2023)进一步用 CLIP 特征实现语言监督的神经场,支持开放词汇语义推理与文本驱动查询。
总结:神经场因其连续、紧凑的几何-语义统一表达,正被机器人与具身智能社区广泛采纳;但在实时训练、动态环境部署方面仍存瓶颈。未来需着力提升效率、适应性,并与基础模型深度融合,以支撑开放世界的语义推理。
4.4 混合地图(Hybrid Map)
至此,我们已看到先前工作将地图结构化为空间网格、基于地标的场景图,或更稠密的几何地图。最新趋势则是把多种结构融合成单一表征,以便在不同粒度捕获信息,并支持多样化的环境推理。
将网格地图的度量信息与拓扑地图相结合,即所谓的 topometric 地图(Thrun et al., 1998b;Tomatis et al., 2001;Blanco et al., 2008b;Konolige et al., 2011;Ko et al., 2013;An et al., 2023;Mozos et al., 2007;Vasudevan & Siegwart, 2008;Zender et al., 2008;Pronobis et al., 2010;Hemachandra et al., 2011;Walter et al., 2013, 2014;Hemachandra et al., 2015;Duvallet et al., 2016;Walter et al., 2022)。Thrun et al. (1998b) 提出一种统一统计建图算法:先用粗粒度拓扑地图校正全局里程计误差,再在拓扑节点内生成高分辨率网格地图,分别解决全局对齐与局部分辨率问题。Tomatis et al. (2001) 则构建紧凑的环境模型:走廊与拐角用拓扑节点表示,房间用局部网格表示,两者在同一框架内无缝切换。机器人走廊行走时维护全局拓扑图,进入房间即新建局部度量图;作者认为只有在房间内才需高精度(如操作物体),而走廊仅需拓扑保持全局一致性。更近的 BEVBert(An et al., 2023)先离线构建混合地图,再学习多模态表征,以提升语言引导导航中的空间推理能力。
还有研究进一步融合网格、稠密几何与拓扑三种结构。StructNav(Chen et al., 2023b)构建的混合地图包含:
• 空间网格:存储占用信息,负责避障与低级路径规划;
• 场景图:节点为地标,边为关系,支持高层地标间推理;
• 3D 语义点云:每点带语义标签,实现更稠密的语义-几何匹配。
此外,研究者也在构建能够按不同抽象层级捕捉场景语义层次结构的地图(Galindo et al., 2005;Pronobis & Jensfelt, 2012;Hemachandra et al., 2014;Werby et al., 2024),从而支持多层次的推理。Armeni et al. (2019) 将静态场景表示为多级层次结构(建筑—房间—物体),把实体作为层次图中的节点,并用边存储坐标系之间的变换关系。Tang et al. (2025)(OpenIn)构建类似的层次化场景图,以跟踪动态变化的室内环境中的物体。Rosinol et al. (2020a)(Dynamic Scene Graphs)同样构建分层场景图,用于追踪移动的物体与智能体,并通过建模物体与智能体之间的时空关系,同步生成稠密的 3D 度量空间地图。Hughes et al. (2024) 证明,在大规模环境中,层次化场景表征比扁平表征更具可扩展性,并提出了 Hydra 系统,可实时地从传感器数据增量式构建 3D 场景图。Fischer et al. (2024) 则提出一种多层次场景图,用于表示由行驶车辆采集图像生成的大规模动态城市场景,并为城市驾驶场景建立了新的视角合成基准。
总结
不同地图结构各有优劣:粗粒度拓扑地图擅长刻画环境中的显著地标;细粒度度量地图能够精确描述几何;稠密几何地图则可更细腻地表现场景中物体的 3D 结构。因此,将两种或多种结构结合,并在不同语义抽象层级上呈现环境,是构建更优表征的关键。尽管混合地图在机器人领域已有探索,但在具身智能中仍属空白。然而,在组合前必须审慎考虑各结构的弱点:例如,拓扑与稠密几何地图在大规模环境中的可扩展性优于网格地图;存储需求方面,稠密几何地图最大,拓扑地图最小。
5 地图编码(Map Encoding)
本节讨论语义地图如何“编码”并存储信息。无论地图采用何种结构,其内部数值的编码方式都可以归为两大类:显式编码与隐式编码。显式编码中,每个存储值的含义明确可辨;隐式编码则使用特征嵌入,其具体语义通常不可直接解读。下文将结合图示(图 8)对这两类编码的代表性工作进行归纳。
5.1 显式编码(Explicit Encoding)
许多早期工作采用显式编码,将可直接解释的信息存入地图。最典型的是占用(occupancy)信息:地图中的每个单元格保存二进制值 1 或 0,指示该物理位置是否被物体占据,从而支持避障(Elfes, 1989;May et al., 2009;Chaplot et al., 2019;Georgakis et al., 2022a)。
• 探索任务
在要求“最大化探索面积”的场景中,除占用外,再记录“已探索”位同样重要。Active Neural SLAM(Chaplot et al., 2019)用 Neural SLAM 模块以 BCE 损失学习预测占用与已探索两张二值图,并与其他模块联合训练。VLMNav(Goetting et al., 2024)也在俯视体素图中存储已探索信息,以验证其下游导航泛化能力。
• 目标导航(ObjectNav)及更长周期任务
仅靠占用与已探索不足以定位语义目标,还需存储物体语义类别。
– SemExp(Chaplot et al., 2020a)用 Mask R-CNN 获取类别,经深度投影后,占用/已探索用逐元素 max 聚合,类别则取最新值,再经去噪网络输出最终语义图,实验表明该图能显著提升长程目标搜索效率。
– MOPA(Raychaudhuri et al., 2023)在多目标导航中维护“所见物体”记忆,证明对任务至关重要。
– 但先分割后投影易出现“标签飞溅”(label splattering)。Semantic MapNet(Cartillier et al., 2021)改为先投影编码特征再分割,显著降噪,可离线建图后供多任务使用。
– GOAT(Chang et al., 2023;Khanna et al., 2024)维护实例级地图,通过存储原始图像并在查询时用 CLIP 做文本-图像匹配、SuperGlue 做图像-图像匹配,实现语言/图像/类别三种目标的统一导航。
– MapNav(Zhang et al., 2025)在地图上保存分割后物体的文本标签,帮助 VLM 更好地实现语言接地。
• 其他模态
– 音频-视觉导航中,Chen et al. (2020b) 在地图单元格存储平均音频强度。
– 交互问答任务里,Gordon et al. (2018) 把物体检测置信度存入空间图,并用 GRU 循环记忆随时间聚合,提升任务表现。
综上,显式编码通过存储占用、已探索、类别、实例、文本标签或音频强度等可直接解释的量,为不同任务提供了清晰、可用的语义线索。
除上述显式空间地图外,部分工作也构建了显式的拓扑地图(Choset & Nagatani, 2001;Blochliger et al., 2018;Chen et al., 2022;Salas-Moreno et al., 2013;Duvallet et al., 2013;Patki et al., 2019;Arkin et al., 2020a;Raychaudhuri et al., 2025;Chang et al., 2025)。例如,Kwon et al. (2021) 在图节点中记录“首次到达该节点的时间步”,从而在聚合时用最新时间步更新该信息,以编码节点间的时间关系。
总结
显式地图编码的优点在于可解释性强,能够直观地考察“哪类信息对下游任务最有帮助”。然而,需要预先定义类别集合,这使得地图只能覆盖有限的对象类别,限制了其对新类别或开放词汇场景的适应能力。
5.2 隐式编码(Implicit Encoding)
隐式地图(implicit maps)在语义地图中存储的是潜在特征(latent features)。早期工作大多使用在封闭词汇(closed-vocabulary)物体类别上预训练的视觉模型提取特征;而近期方法则改用大型视觉-语言预训练模型提取特征,从而获得可开放词汇(open-vocabulary)查询的灵活地图。此外,也可以存储并不一定支持语言查询、但能保留该位置视觉信息的特征。例如,RNR-Map(Kwon et al., 2023)使用网格地图存储与神经场对应的潜码(latent codes),进而可用于在该位置渲染可能的视角。
5.2.1 Closed-vocabulary encoding
这些隐式特征既可以从零开始学习,也可以直接取自预训练视觉模型。
• 从零学习
Wani et al. (2020) 用若干 CNN 块在 MultiON 任务中联合训练,端到端地生成图像特征并构建全局空间地图。由于特征与策略同步优化,无需额外监督。
• 使用 ImageNet 预训练的 ResNet
– CMP(Gupta et al., 2017)用 ResNet-50 编码 egocentric RGB 图像,随后通过可微映射模块投影到地图;地图编码无需显式监督,而是与可微规划器共同学习,使网络自动存储对任务最有用的信息,并用可微 warp 逐帧累积。
– MapNet(Henriques & Vedaldi, 2018)同样用 ResNet-50 提取特征,却构建 allocentric 全局地图:先将特征地面投影,再配准进全局坐标系,并在每一步更新;整个网络用 RGB-D 序列及对应位姿端到端训练,用于定位任务。
• 在拓扑节点中存储隐式特征
一些方法将观测的编码特征存放在拓扑图的节点内。此时仍普遍采用预训练 ResNet 来提取 RGB 特征(Chaplot et al., 2020b;Chen et al., 2021)。
总结
相较于从零训练,使用预训练 ResNet 能复用已学到的通用表征,样本效率高;缺点是受限于 ImageNet 的封闭类别,难以泛化到未见类别。
5.2.2 Open-vocabulary encoding
封闭词汇编码的局限,可借助从大规模视觉-语言模型(LVLM)提取的特征来缓解。这类模型(如 CLIP,Radford et al., 2021)在巨量互联网图文对上联合训练,使地图能够存储“任意”对象的信息,并支持开放词汇的文本查询(Wen et al., 2025),而不再受预定义类别限制。例如,当指令要求“在儿童房找一只红蓝条纹的斑马玩具”时,即使训练阶段未见该具体物体,智能体仍可借助 LVLM 对斑马、颜色、房间等先验知识进行推理。此外,近期的大语言模型(LLM,如 GPT-4,OpenAI, 2023)已展现出复杂任务规划能力。因此,基于 LVLM 构建的开放词汇地图与 LLM 规划器(Taioli et al., 2023;Huang et al., 2023b;Long et al., 2024)相结合,已在具身智能领域催生出一系列新工作(表 6,图 9)。
预训练的 CLIP 模型可以计算输入图像与一段自然语言描述之间的相似度分数,其中得分最高的图像-文本对被视作最匹配。该思路已被成功应用于建图:地图中保存的是“值地图(value map)”,即智能体所见每张图像与目标物体语言指令之间的相似度分数。
• CoW(Gadre et al., 2023)在语言驱动的 ObjectNav 任务中,以零样本方式验证 2D 值地图的有效性:当某单元格内的相似度超过阈值时,规划器直接规划路径前往该处。
• VLFM(Yokoyama et al., 2023)利用 BLIP-2 生成的 2D 值地图完成同类任务。
• InstructNav(Long et al., 2024)进一步扩展,将“动作、地标、导航历史”等多源值图与语义值图融合,提升通用指令跟随能力。
• VoxPoser(Huang et al., 2023b)则构建 3D 值地图,用于高效的桌面机器人操作。
与只能存储预定义对象类别的早期编码相比,值地图显然更强大。然而,它仅对整幅图像做全局匹配,忽略了场景中各物体的空间位置,难以完成精细的空间推理。
为弥补这一缺陷,研究者们提出先在图像中定位物体,再提取对应特征:
像素级嵌入
VLMaps(Huang et al., 2023a)利用 LSeg 获得每像素嵌入,经深度投影到 2D 地图;若多像素落入同一单元格,则取平均。推理时,从语言查询抽取物体名称,与地图逐像素计算相似度。缺点:嵌入稠密且冗余,平均会丢失信息,且缺乏物体级语义与空间关系。块级嵌入
OneMap(Busch et al., 2025)改用 SED 的块级特征和分层编码器主干,比纯 Transformer 结构更好地捕获空间信息,缓解了像素级问题。物体级嵌入
NLMap(Chen et al., 2023a)先用类无关的区域提议网络(ViLD)检测所有物体,再对每个 ROI 联合 CLIP+ViLD 提取嵌入,连同 3D 位置与尺寸存入 3D 地图。推理时,只需从自然语言查询中提取物体名称,即可在地图上检索最高相似度的对象。该表征无需任务特定监督,可直接用于各类下游任务。
虽然 NLMap 构建的是 3D 空间地图,但许多工作(Shah et al., 2023;Garg et al., 2024)采用类似思路构建拓扑地图。例如,最近的 ConceptGraphs(Gu et al., 2024)先用类无关的 2D 分割模型 Segment-Anything(SAM,Kirillov et al., 2023)从输入图像中提取候选物体掩码,这些物体即成为拓扑图的节点。随后,用 CLIP 和 DINO(Oquab et al., 2023)为每个物体提取图像特征并存入对应节点。节点还可附加更多信息:ConceptGraphs 将 SAM 掩码投影得到的点云、以及由 LLaVA(Liu et al., 2023a)和 GPT-4(OpenAI, 2023)生成的物体描述一并保存。
节点间的边依据空间关系构建:当两物体点云在几何上足够接近(某比例的点落在给定距离阈值内)时,即认为二者空间相关并建立边;边还存储由 LLM 生成的关系描述。若新检测物体与已有节点相似,则更新该节点的特征(取平均)、点云(取并集)和描述(取最新);否则新增节点。实验表明,这种统一地图表示可同时用于物体定位、机器人导航与操作任务。
总结:开放词汇地图编码一次构建即可迁移至多种下游任务,支持自然语言开放查询且高度可解释;当前主要瓶颈在于大型基础模型的计算开销较大。
6 评估方法(Evaluation Methodologies)
在具身智能与机器人学的文献中,极少有人关注对已构建地图本身的评估(内在评估)。绝大多数工作把语义地图仅视为完成下游任务(如定位、导航、探索、操作等)的中间步骤,因此只通过各类指标评估智能体在下游任务中的表现(外在评估)。由于这些研究通常聚焦单一任务,直接评测任务性能已足够,无需关心地图本身的质量。
然而,我们认为,除了任务层面的外在评估,还必须对地图进行内在评估,关注其准确性、完整性、一致性与鲁棒性。接下来,我们将详细讨论这两类评估指标。
6.1 Extrinsic evaluation
本节概述了用于评估具身任务中智能体表现的外部(任务级)指标。
• 导航任务
– 成功率 SR:智能体到达目标并主动发出停止/找到信号的比例(Anderson et al., 2018a)。
– SPL (Success weighted by inverse Path Length):成功率与最短路径之比,衡量路径效率(Beeching et al., 2020;Batra et al., 2020b 等)。
– Oracle SR (OSR):到达目标但未发信号的“潜在成功”。
– Navigation Error (NE):终点与目标之间的欧氏距离。
在多步或多目标场景,常用 Progress(Wani et al., 2020)或 Goal-Condition Success(Shridhar et al., 2020)度量子目标完成比例。
指令跟随任务采用 nDTW(归一化动态时间规整)衡量轨迹与参考路径的贴合度(Ilharco et al., 2019;Raychaudhuri et al., 2025)。
• 分类/检测任务
Precision、Recall、F1、ROC 曲线 用于评估预测质量(Chen & Mooney, 2011;Tellex et al., 2011b)。
• 探索任务
Coverage 表示已观测环境的比例(Chaplot et al., 2019)。
• 操作任务(重排、桌面操作等)
以 任务成功率(抓取、放置等成功百分比)为主(Kalashnikov et al., 2018;Zeng et al., 2020)。部分工作还使用 precision(Zeng et al., 2017)或 pose error(Liu et al., 2012)衡量最终与目标位姿的偏差。
总结:外部(任务级)评估指标已在文献中得到广泛研究(Deitke et al., 2022),并随着具身任务日益复杂和多样化而持续演进。面对导航、操作、指令跟随等领域不断出现的新挑战,社区对更细致、任务专属性能指标的需求催生了更鲁棒、更全面的评估框架。尽管外部指标长期占据主导地位,我们认为现在是时候加大对内部指标的关注(下一节将专门讨论)。这一转向尤为关键:近期构建的开放词汇、灵活且通用型地图,迫切需要在“任务是否成功”之外,对地图本身的质量进行更精细的评估。
6.2 Intrinsic evaluation
本节讨论“内在评估”或“地图级评估”,即直接对地图本身进行评价。尽管大多数机器人与具身智能系统都依据下游任务的成功与否来判定好坏,仅有少量研究关注任务过程中所构建地图的质量。然而,目前尚不存在一套被广泛认可的地图表征评估指标。接下来,我们列出可用于评估地图的各个维度,并指出当前空白与未来发展方向。
准确性(Accuracy)。地图准确性衡量地图与真值在几何或语义上的吻合程度。然而,获取真值地图往往非常困难。已有研究分别从以下角度开展评估:
• 2D 占用图:用“地图准确率”度量预测区域与真值的重合比例,并用 IoU 计算交集/并集(Georgakis et al., 2022a;Ramakrishnan et al., 2020)。
• 2D 语义图:采用像素级语义分割指标,如像素准确率、像素级 F1、IoU 及基于轮廓的边界 F1(Cartillier et al., 2021;Georgakis et al., 2022b)。
但目前缺乏可跨不同地图结构(如拓扑图)统一使用的标准化指标;IoU 对拓扑图并不直接适用。此外,评估开放词汇语义地图的准确性尤为棘手:
– OpenScene(Peng et al., 2023)先在固定类别上做语义分割,再用准确率/IoU 评价。
– ConceptGraphs(Gu et al., 2024)借助 Amazon Mechanical Turk 人工评估场景图准确性。
– OpenLex3D(Kassab et al., 2025)为多粒度 3D 场景提供对象标签,供开放词汇表征评估。
这些技术均可移植到具身场景。未来挑战包括:
- 大规模真实环境真值地图的采集耗时或不现实,限制直接比较;
- 动态或杂乱场景下的准确性评估极少被研究。两者均亟待进一步探索。
完整性(Completeness)衡量生成地图对环境的覆盖程度,同时包含几何完整度与语义完整度。
• 几何完整度:已建图区域占整个环境的百分比。
• 语义完整度:地图中语义信息(物体类别、属性等)的覆盖比例。
完整性在搜救、巡检等任务中尤其关键;完整的几何与语义信息可减少对不准确数据的依赖,支持更可靠的决策。
然而,完整度高度依赖于智能体在下游任务中的探索程度,并与停止准则(何时终止探索)紧密相关。在具身智能中,探索通常“任务完成”或“时间预算耗尽”即停止,但后者并不能保证地图已完整,因此设计可靠的停止准仍是开放难题(Placed & Castellanos, 2022;Luperto et al., 2024)。
现有做法:
• 几何覆盖:在纯探索任务中会报告“环境探索比例”(Chaplot et al., 2019)。
• 语义覆盖:因缺乏带详细语义的真值地图而极少被量化,与上一节“准确性”所述困难一致。
一致性(Consistency)
几何一致性
指地图在空间结构(距离、角度、相对位置)上与真实环境的吻合程度,直接影响路径规划与避障安全。经典机器人学中,一致性是回环检测(loop closure)成功与否的关键,常用指标包括:
• Absolute Trajectory Error (ATE)——累计位姿误差;
• 回环 Precision / Recall。
然而,当前具身智能系统普遍假设无传感器/执行器噪声,因此几乎不存在漂移,也就鲜少报告几何一致性指标。未来若要应对动态障碍或噪声环境,可改用 RMSE(与真值几何的均方根误差)来衡量。语义一致性
指地图中语义标注与其物理位置的持续对齐。当视角、光照或环境动态变化时,必须保证语义信息依旧准确。可用“时序准确率”(随时间变化的语义准确率)量化,但目前尚无工作对此进行度量,值得未来深入研究。
鲁棒性(Robustness)评估旨在检验语义地图在不可预测或动态环境中的可靠性。
• 一条鲁棒的地图应对传感器噪声、误差和环境变化保持低不确定性与高置信度。
• SLAM 领域常用 Absolute Trajectory Error(ATE)与 Relative Pose Error(RPE)在噪声扰动下衡量系统鲁棒性(Prokhorov et al., 2019;Yang et al., 2025)。
• 对使用预训练模型的方法,可直接利用模型输出的置信度或预测方差:高置信度或低方差对应更鲁棒的地图。
• 具身智能中已有工作将不确定性纳入任务规划(Georgakis et al., 2022a;Raychaudhuri et al., 2025),但尚未作为正式指标,值得未来探索。
机器人学中的不确定性推理可为设计地图鲁棒性指标提供借鉴:
– 联合熵(joint entropy)量化机器人位姿与地图的总不确定度;
– 期望地图信息(expected map information,通常用互信息表示)衡量未来观测后地图不确定度的预期下降,被用于主动 SLAM 与探索(Stachniss et al., 2005;Blanco et al., 2008a;Carlone et al., 2013);
– 不确定性感知建图(uncertainty-aware mapping)使用概率占用网格、高斯过程或学习式模型显式表示并传播地图内部的不确定性,提升动态/部分可观测环境中的鲁棒性。
尽管上述量在建图和规划中广泛应用,但它们任务相关、抽象且计算复杂,因而极少作为评估指标被报告。
6.3 总结
本节对评估的关键挑战与未来方向进行总结(表 7)。
• 外部(任务级)指标已得到充分研究,并随任务复杂度提升而持续演进。
• 内部(地图级)评估在语义 SLAM 与具身智能中仍严重不足,面临两大瓶颈:
- 大规模真实环境中难以获取精确、细粒度、开放词汇的真值注释,导致无法可靠衡量地图的语义准确性、一致性与完整性;
- 目前缺乏一套可跨不同地图结构(拓扑、空间网格、稠密几何等)和跨不同编码方式(显式/隐式特征)统一使用的标准化评估指标。
这些挑战共同揭示了关键空白,也指明了未来亟需开发可扩展、可泛化的地图评估框架的重要研究方向。
7 开放挑战(Open Challenges)
尽管语义建图已取得显著进展,但仍存在诸多待解决的关键难题,本节从多个维度归纳如下。
效率(Efficiency)
随着地图纳入更细粒度的语义信息,数据量激增,给机器人受限硬件的内存与存储带来严峻挑战。
结构层面
• 空间网格:均匀覆盖、语义丰富,但分辨率高时内存爆炸,难以扩展到大场景。
• 稠密几何:点/面级别精度高,可存颜色、法线等,但冗余大、存储开销高。
• 拓扑图:轻量、可扩展,却缺乏精细几何,难以胜任操作或精确定位。
• 混合 topometric:试图折中,但需同时维护两层,更新与计算复杂度增加。编码层面
• 高维神经特征:压缩且表达力强,但查询/更新代价高,可解释性差。
综上,在语义丰富度、空间保真与可扩展性之间取得高效平衡仍是亟待突破的开放问题。
可扩展性(Scalability)。随着语义建图系统被部署到越来越庞大、动态且多样的环境中,“可扩展”成为关键挑战。它要求系统能够同时应对:
- 空间尺度扩大(如整栋楼宇、街区);
- 语义复杂度提升(物体类别、场景类型激增);
- 时间演化(长期、终身运行);
并在整个过程中保持效率、精度与鲁棒性。高分辨率、全局一致的地图需要大量计算与内存,其需求随环境规模与丰富度呈指数级增长。例如,家用机器人在多个凌乱房间中长期运行,必须持续保存精细空间布局与物体级信息,而不能耗尽机载存储或算力。动态场景(家具移动、物品增减)进一步加剧难度:地图必须实时更新。此外,随着地图扩张,回环检测、重定位、查询等核心操作在仿真与真实机器人上都愈发昂贵。因此,亟需轻量、自适应的语义建图方法,在资源受限的硬件上随环境复杂度线性或亚线性扩展。
实时处理
语义建图必须满足严苛的实时性,尤其在自动驾驶与实时人机交互中,决策延迟需控制在毫秒级。以城市自动驾驶为例,车辆需即时识别红绿灯、更新动态障碍,并在毫秒内规划安全轨迹;任何感知或地图更新延迟都可能引发事故。目前,在内存受限硬件上同时保证“语义丰富”与“处理速度”仍是开放难题。模型压缩、边缘计算与高效表征虽有进展,但在严格延迟约束下维持高保真语义理解,仍是实际部署的主要瓶颈。
噪声与不确定性
真实场景中的传感器缺陷、环境动态变化和语义歧义,使噪声与不确定性的处理成为根本挑战。
• 传感器噪声(相机、LiDAR、深度)会导致观测误差;检测/分割/分类模型的错误又会引入语义不一致。
• 例如,机器人在杂乱室内可能将凳子误判为椅子,或漏检遮挡、弱光物体;错误累积会造成语义漂移。
• 现有系统很少显式建模并传播不确定性,导致规划时对错误地图条目过度自信,危及安全。
• 尽管贝叶斯滤波或概率表征可在机器人学中量化不确定(Blanco et al., 2008a;Georgakis et al., 2022b),但计算开销大、难以扩展。
• 具身智能方法通常在仿真中假设无噪传感器,迁移到真实机器人时性能骤降。因此,显式建模并管理不确定性、构建鲁棒语义地图仍是机器人与具身智能的共同开放问题。
多模态融合
最新语义建图方法日益依赖视觉、深度、音频、自然语言、语音等多源感知来构建丰富且可解释的环境表征,但稳健的多模态融合仍是核心难题:
• 模态对齐困难——视觉提供空间与外观线索,而语言/语音往往给出高层、模糊或上下文相关的语义(如“去宝宝正在睡觉的房间”)。
• 观测噪声与缺失——音频(脚步声、对话、物体声)虽含环境信息,却瞬态且难以持续空间化。
• 下游推理与泛化——需支持复杂空间查询(如“果盘后面的杯子”“水壶与盘子之间的花瓶”)及可供性问答(“哪里可坐”“哪些物品易碎”)。
• 大模型局限——多模态基础模型(Alayrac et al., 2022;Driess et al., 2023;OpenAI, 2023)虽可跨模态对齐与推理,却未针对建图或长期记忆训练,且部署在机器人端面临计算与能耗瓶颈。
因此,如何在实时约束下实现高效、可靠且可查询的多模态融合仍是开放问题。
终身学习
真实场景要求机器人长期运行并持续适应动态环境(家具重排、物品移动、季节变化)。语义地图需:
- 持续更新——淘汰过时信息、合并新观测、区分瞬态/持久变化;
- 防灾难遗忘——跨时段、跨视角解决冲突数据;
- 时序推理——随时间演化而非一次性构建。
终身自主的核心在于无需人工重配置即可适应家庭、仓库或户外环境的长期变化,使智能体“与世界共同成长”。然而,现有系统尚缺乏稳健的连续语义学习机制,难以应对持续演化的开放世界。
标准化评估框架
语义建图领域最突出的难题之一,是缺乏一套统一、可复现的评估基准,难以在不同任务、不同环境和不同地图表征之间进行公平比较(详见第 6.2 节)。目前社区聚焦任务级外部评估,对内在地图质量的度量却进展缓慢。没有标准化的内在指标,我们无法判断下游任务提升究竟源于更优的语义理解,还是更优的控制策略。因此,亟需发展通用、可解释、任务无关的评估指标,既用于追踪研究进展,也用于促进跨领域泛化。随着开放词汇、多模态、可查询的通用语义地图日益成为具身智能与现实机器人推理的核心,构建同时衡量结构与语义保真度的统一基准,已成为推动该领域前进的关键。
小结
语义建图在多个维度仍面临关键开放问题:
• 如何构建高效、可扩展且实时的地图,同时对噪声与不确定性保持鲁棒;
• 如何打造可靠且灵活的多模态地图;
• 如何支持终身学习的地图更新机制;
• 如何建立标准化的评估框架。
这些问题亟需持续的研究与创新。
8. 未来研究方向
本节梳理了语义建图当前的挑战,并给出未来研究的潜在方向。过去数十年,该领域已取得长足进步,但仍有诸多难题与改进空间。研究正在向“同一张地图、多任务通用”的目标迈进:打造灵活、开放词汇、可查询的通用表征,使同一语义地图无需重新训练即可支撑导航、操作、问答等多样化下游任务。与此同时,为了在空间-语义层面实现高效推理,研究也聚焦于“稠密、可扩展、内存友好”的地图,既保留高分辨率与细节,又能在动态、大规模环境中保持计算效率与一致性,这对实时或资源受限场景尤为关键。
目前,评估重心仍放在“下游任务表现”,而对地图本身的品质关注不足。未来需超越任务成功指标,系统考量地图的准确性、完整性、一致性与鲁棒性,以确保其在更广泛应用中的可靠性与有效性。以下,我们深入讨论若干最具前景的未来方向。
8.1 通用型地图
要在机器人与具身智能中真正落地,必须构建“通用型”语义地图:仅用一张地图即可在多样环境中完成导航、操作、场景理解等多种任务,无需针对每个任务重新建图。实现这一目标需要:
开放词汇能力
• 支持自然语言描述的新颖物体,使机器人能在未知或杂乱场景下扩展语义理解。
• 当前依赖的类无关检测器对小、薄、遮挡物体识别不足;开放词汇检测器在未见类别上也缺乏鲁棒性。
→ 未来需研发无需大量重训练即可稳健识别新物体的开放词汇检测器。资源效率
• 通用地图需同时存储高分辨率几何与丰富语义,导致计算与内存开销巨大。
→ 需在“细节丰富”与“资源受限”之间取得平衡,实现大场景实时更新与持续维护,这是亟待突破的研究方向。
8.2 稠密而高效的地图
要完成“把手机从笔记本旁边的桌面拿给我”这类细粒度空间推理,语义地图必须保留物体之间精确的 3D 排列信息。拓扑图过于稀疏,无法提供足够细节;稠密几何图又过于冗余,把大量空白空间一并保存。俯视 2D 网格虽介于两者之间,却丢失了高度维度的关键语义,对无人机等 3D 导航场景尤为不利。因此,亟需一种“足够稠密、覆盖完整 3D 空间,又能智能剔除空白区域”的地图表征。与此同时,稠密结构必然带来内存与计算开销,因而开发可扩展、内存友好且易于增量更新的稠密地图仍是值得深耕的未来方向。
8.3 动态地图
当前室内建图普遍假设环境静态、仅智能体运动。这一假设在室内尚可成立,但在户外面对行人、车辆等移动目标时则显然不切实际。因此,亟需研究:
- 现有建图方法能否有效捕捉动态物体;
- 如何构建高效的动态地图。
核心难点包括:
• 实时持续追踪与更新——目标运动不可预测,需融合 LiDAR、相机等多传感器数据,计算密集;
• 存储与表示——动态数据既要实时更新,又要在内存与计算上可扩展;
• 下游任务集成——机器人需理解并预测物体轨迹(如绕开行人、车辆),这对实时决策提出更高要求。
综上,在动态、高流量环境中构建、更新并利用动态地图,仍是自主导航领域亟待突破的开放问题。
8.4 混合地图结构
空间地图能够捕获 3D 几何,便于推理物体与区域之间的复杂空间关系;拓扑地图虽缺乏几何细节,却能显式表示物体(节点)之间的语义关系(边)。为了兼得二者之长,研究者提出“混合”结构:在同一框架内融合空间地图的几何精度与拓扑地图的语义-关系能力,从而为复杂推理提供更全面、高效的工具。
• 在大规模室外场景,机器人可先用拓扑图做“跨楼”长途导航,再切换到局部空间图实现避障或室内精细操作。
• 拓扑图计算轻量,可承担全局引导;空间图仅在高精度需求区域启用,降低持续的全局处理开销。
• 可再引入层级结构,将动态物体单独维护,进一步减少频繁实时更新的计算量。
当前挑战:
- 如何在不牺牲各自质量的前提下高效融合两种表示;
- 如何让机器人智能决策何时、何地切换表示。
因此,混合地图的构建、扩展至大规模实时应用、以及切换算法优化仍是未来研究重点。
8.5 设计评估指标
正如第 6 节所述,具身智能领域对语义地图本身的评估远少于对下游任务表现的评估。我们认为,推动该领域需强化地图层面的评估,核心维度包括:
• 准确性——语义信息与实际环境的一致程度;
• 完整性——几何与语义覆盖是否充分;
• 一致性——在动态环境中空间与语义的持续可靠性;
• 鲁棒性——对噪声、不确定性的置信度与抗干扰能力。
建立统一、标准化的评估指标和框架仍是关键挑战,也蕴含巨大研究空间。
8.6 小结
本节总结了第 7 节指出的未来研究方向。随着领域迈向灵活、通用、可查询的地图,研究者需解决:语义丰富度与效率的平衡、动态环境中的可扩展性与鲁棒性、以及超越任务表现直接衡量地图质量的评估体系。以上开放问题为多维度研究提供了广阔前景,将共同推动语义建图向前发展。
9 结论
在这篇综述中,我们广泛回顾了语义建图的多种方法,并根据其底层地图结构(如空间网格、拓扑图、稠密几何和混合表征)以及语义编码方式(显式或隐式)进行了分类。鉴于基础模型的最新进展以及对通用性、多模态、开放词汇和可查询地图表征日益增长的需求,这种视角具有很强的时效性。这篇综述有助于识别当前语义建图范式中的关键挑战,并为未来语义建图的研究提供有前景的方向。
现有的工作主要使用空间地图来捕捉几何布局,或使用拓扑地图来模拟基于地标的关联。尽管许多机器人研究已经探索了结合空间和地标信息的混合地图,但在具身智能研究中,这种方法仍然有待进一步开发。它为未来的工作提供了一个有前景的方向,特别是在利用这样的地图来提高复杂空间推理任务的性能方面。我们也讨论了如何通过将语义信息与点云、三角网格或表面元素相关联来创建稠密几何地图,这些地图在具身智能任务中具有潜力,但仍然有待进一步开发。尽管在空间推理方面很有前景,但它们对内存的需求高、计算效率低下,以及室内环境中大部分 3D 空间是空的,这些都构成了重大挑战。此外,大多数当前的建图方法都假设环境是静态的,限制了它们在动态设置中的适用性,例如在家具重新摆放或人们走动的场景中。
我们希望这篇综述中提供的见解能够为研究界进一步推动该领域的进步提供指导和启发。
致谢:作者得到了加拿大 CIFAR AI 主席研究资助和 NSERC 发现基金的支持。我们还要感谢 Manolis Savva、Yasutaka Furukawa、Tommaso Campari、Austin T. Wang、Xingguang Yan、Bernadette Bucher、Duy Ta 和 Sachini Herath 以及匿名审稿人对我们的论文提供的宝贵反馈。