
VLN
数据集
模拟器
VLN
综述
Awesome Vision–Language–Action Models for Autonomous Driving
VLN-VER
似乎没有使用大模型
https://github.com/DefaultRui/VLN-VER
cvpr 2024
https://arxiv.org/pdf/2403.14158
https://blog.csdn.net/qq_35831906/article/details/135881625

VER能够预测3D占用、房间布局和3D框。
SG-Nav
https://zhuanlan.zhihu.com/p/909651478
分层 3D 场景图
增量式更新与剪枝
分层链式思维提示
基于图的重感知机制
UniGoal
https://github.com/bagh2178/UniGoal

VLMaps
https://github.com/vlmaps/vlmaps
https://zhuanlan.zhihu.com/p/1899511479981548204
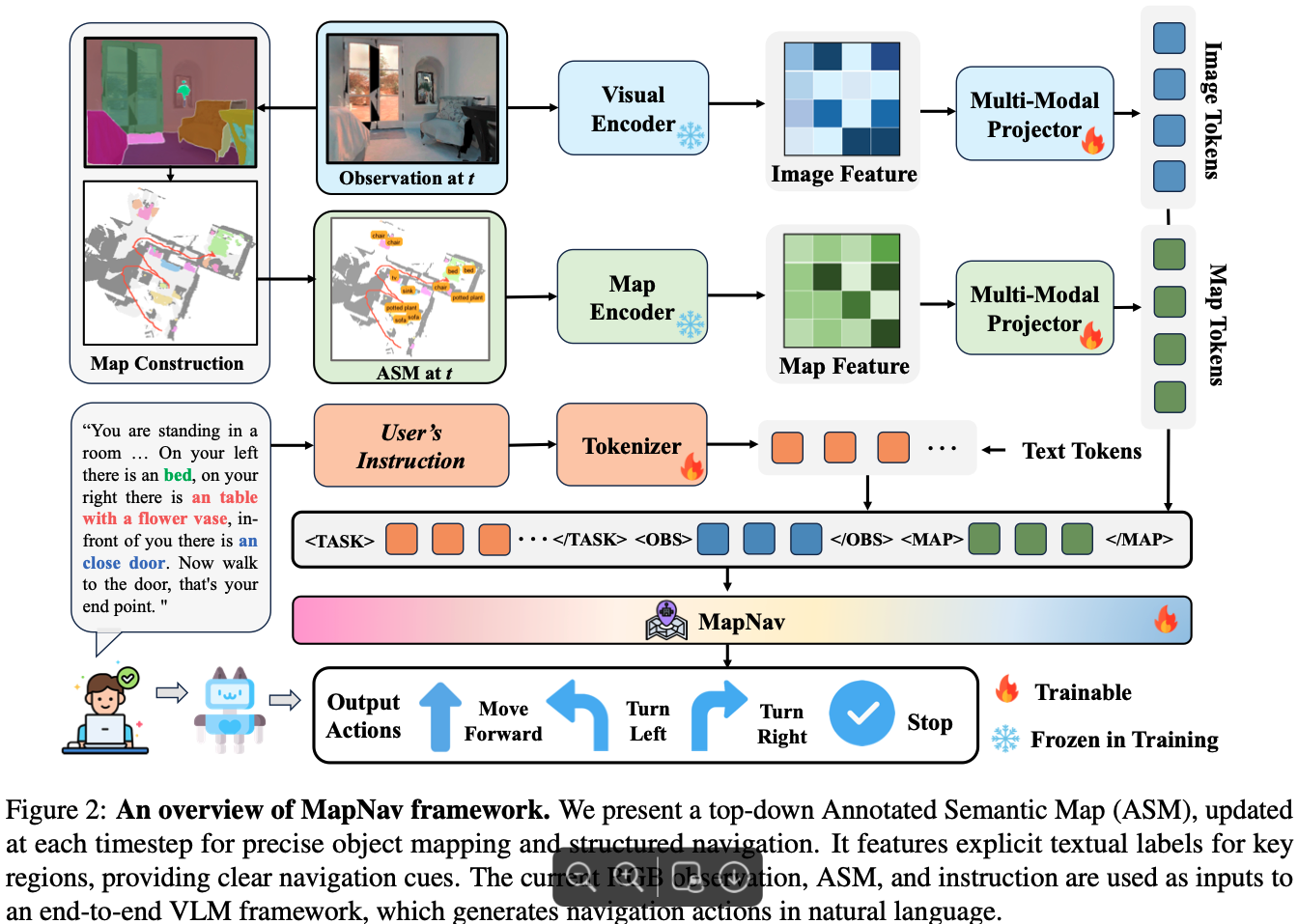
Mapnav
https://zhuanlan.zhihu.com/p/28340277990
https://arxiv.org/pdf/2502.13451
https://zhuanlan.zhihu.com/p/26160636617
设计一种新颖的内存表征方法来有效替代传统的历史帧变得非常重要
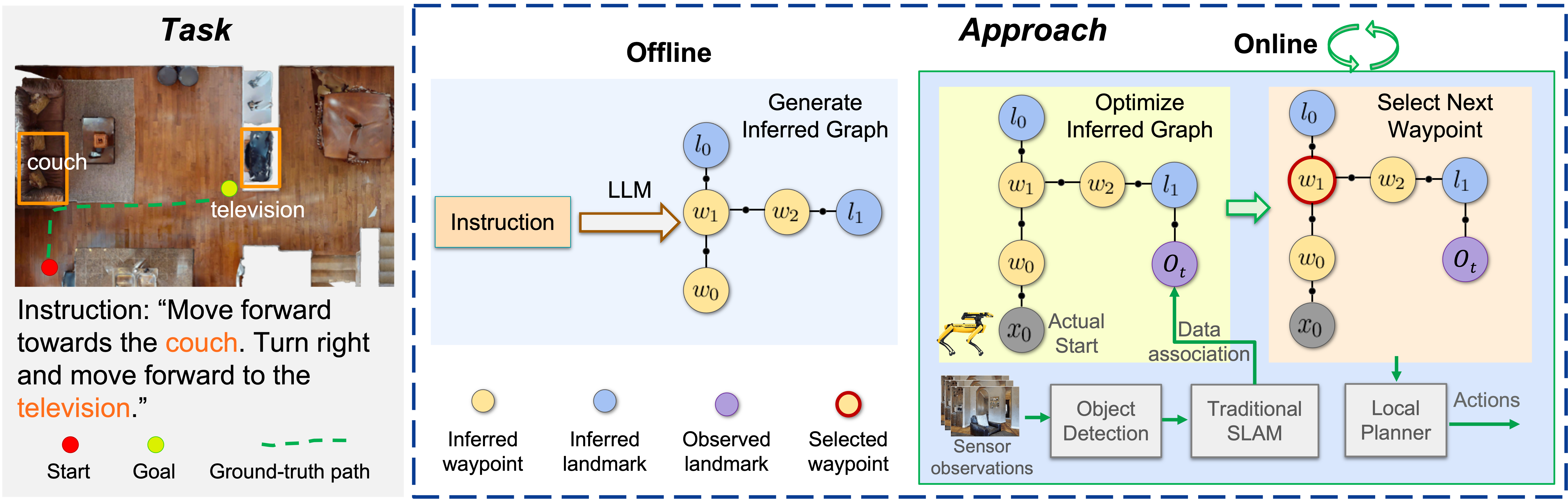
Zero-shot Object-Centric Instruction Following: Integrating Foundation Models with Traditional Navigation
https://sonia-raychaudhuri.github.io/nlslam/
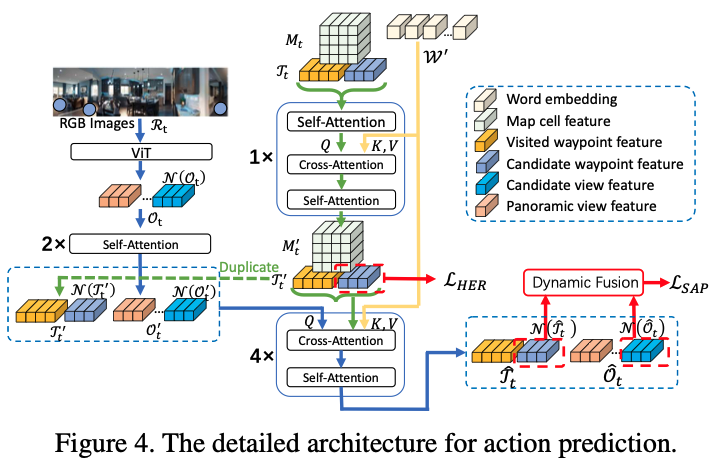
GridMM: Grid Memory Map for Vision-and-Language Navigation
Navid
Semantic Map
Semantic Map 综述
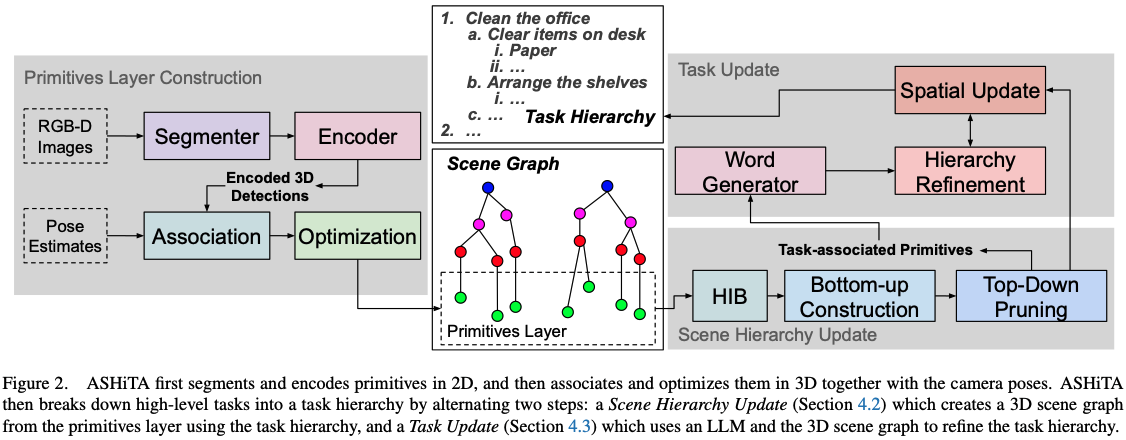
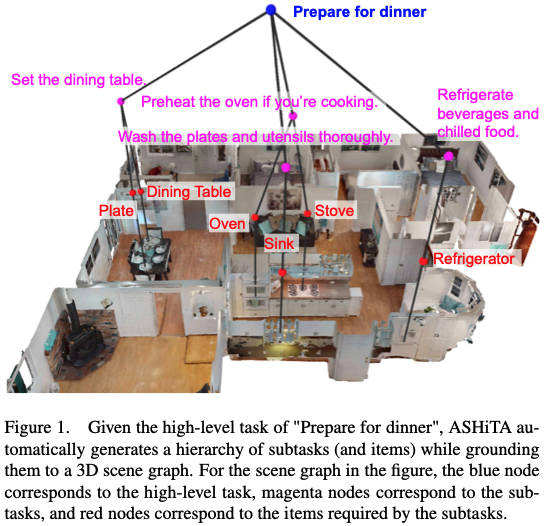
ASHiTA
Automatic Scene-grounded HIerarchical Task Analysis
https://arxiv.org/pdf/2504.06553
S-Graphs+: Real-time Localization and Mapping leveraging Hierarchical Representations
https://github.com/snt-arg/s_graphs_docker
https://arxiv.org/pdf/2212.11770


CURB-SG
https://github.com/robot-learning-freiburg/CURB-SG/tree/main
https://arxiv.org/pdf/2309.06635
https://github.com/koide3/hdl_graph_slam

HOV-SG (RSS 2024)
https://github.com/hovsg/HOV-SG
https://blog.csdn.net/qq_41204464/article/details/149445104
