StyleGAN
StyleGAN 和 StyleGAN2 的深度理解 - 知乎 (zhihu.com)
StyleGAN中的“**Style”**是指数据集中人脸的主要属性,比如人物的姿态等信息,而不是风格转换中的图像风格,这里Style是指人脸的风格,包括了脸型上面的表情、人脸朝向、发型等等,还包括纹理细节上的人脸肤色、人脸光照等方方面面。
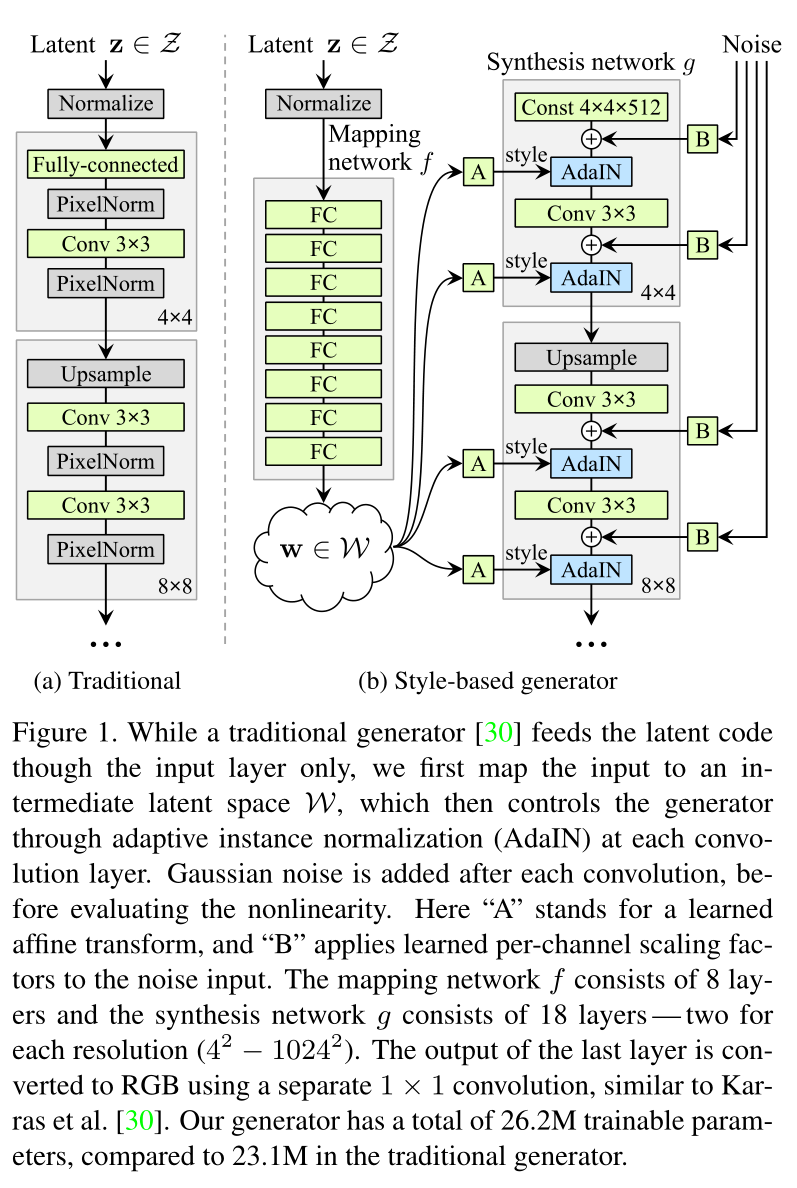
StyleGAN 的网络结构包含两个部分,
- Mapping network,图 (b)中的左部分,由隐藏变量 z 生成 中间隐藏变量 w的过程,这个 w 就是用来控制生成图像的style,即风格,为什么要多此一举将 z 变成 w 呢,后面会详细讲到。
- Synthesis network,它的作用是生成图像,创新之处在于给每一层子网络都喂了 A 和 B,A 是由 w 转换得到的仿射变换,用于控制生成图像的风格,B 是转换后的随机噪声,用于丰富生成图像的细节,即每个卷积层都能根据输入的A来调整**"style"**。
传统的GAN网络输入是一个随机变量或者隐藏变量 z,但是StyleGAN 将 z 单独用 mapping网络将z变换成w,再将w投喂给 Synthesis network的每一层,因此Synthesis network中最开始的输入变成了常数张量
Mapping Network
Understanding Latent Space in Machine Learning | by Ekin Tiu | Towards Data Science
Mapping network 要做的事就是对隐藏空间(latent space)进行解耦。
为了更好的对数据进行分类或生成,需要对数据的特征进行表示,但是数据有很多特征,这些特征之间相互关联,耦合性较高,导致模型很难弄清楚它们之间的关联,使得学习效率低下,因此需要寻找到这些表面特征之下隐藏的深层次的关系,将这些关系进行解耦,得到的隐藏特征,即latent code。由 latent code组成的空间就是 latent space。
Mapping network由8个全连接层组成,通过一系列仿射变换,由 z 得到 w,这个 w 转换成风格 ,结合 AdaIN (adaptive instance normalization) 风格变换方法:
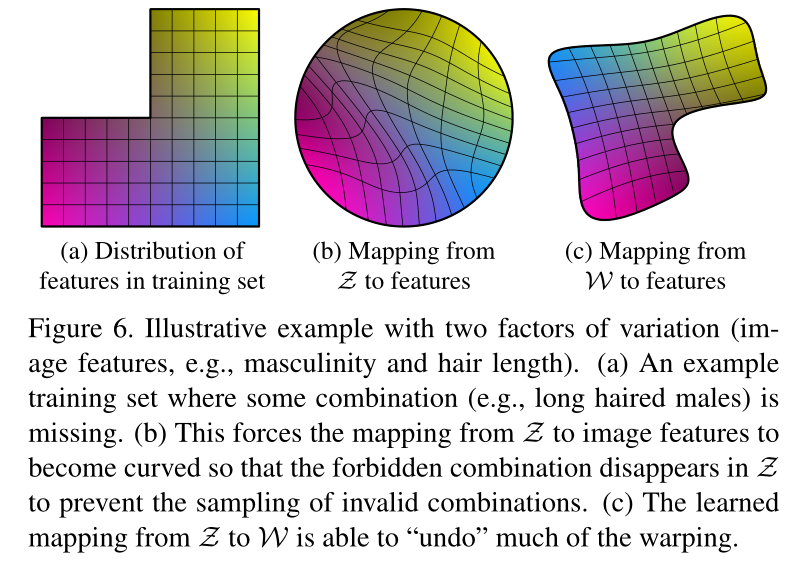
一般 z 是符合均匀分布或者高斯分布的随机向量,但在实际情况中,并不是这样,比如特征:头发的长度 和 男子气概,下图(a)中就是这两个特征的组合,左上角缺失的部分代表头发越长,男子气概越强,如果直接用 均匀分布或者高斯分布对特征变量头发长度和男子气概进行采样,得到的结果都不准确,因此在(b)中将分布(a)warp 成连续的分布函数 f(z),这个 f(z) 的密度是非均匀的,图 (c) 是 w 的分布。
Latent space interpolations
latent space interpolations 不是StyleGAN提到的,但在多篇paper中有提到,如下图的椅子,左边是比较宽的椅子,右边是比较窄的椅子,中间的椅子是这两种椅子特征的线性组合。

Style Mixing
第一行是 source B, 第一列是source A,source A 和 source B的每张图片由各自相应的latent code 生成,剩余的图片是对 source A 和 souce B 风格的组合。 Style mixing 的本意是去找到控制不同style的latent code的区域位置,具体做法是
- 将两个不同的latent code 和 输入到 mapping network 中,分别得到 和 ,分别代表两种不同的 style,
- 然后在 synthesis network 中随机选一个中间的交叉点,交叉点之前的部分使用 ,交叉点之后的部分使用 ,生成的图像应该同时具有 source A 和 source B 的特征,称为 style mixing。
根据交叉点选取位置的不同,style组合的结果也不同。
下图中分为三个部分,
- 第一部分是 Coarse styles from source B,分辨率(4x4 - 8x8)的网络部分使用B的style,其余使用A的style, 可以看到图像的身份特征随souce B,但是肤色等细节随source A;
- 第二部分是 Middle styles from source B,分辨率(16x16 - 32x32)的网络部分使用B的style,这个时候生成图像不再具有B的身份特性,发型、姿态等都发生改变,但是肤色依然随A;
- 第三部分 Fine from B,分辨率(64x64 - 1024x1024)的网络部分使用B的style,此时身份特征随A,肤色随B。
由此可以大致推断,低分辨率的style 控制姿态、脸型、配件 比如眼镜、发型等style,高分辨率的style控制肤色、头发颜色、背景色等style。

Stochastic variation
让生成的人脸的细节部分更随机、更自然
实现这种 Stochastic variation 的方法就是引入噪声,StyleGAN的做法是在每一次卷积操作后都加入噪声

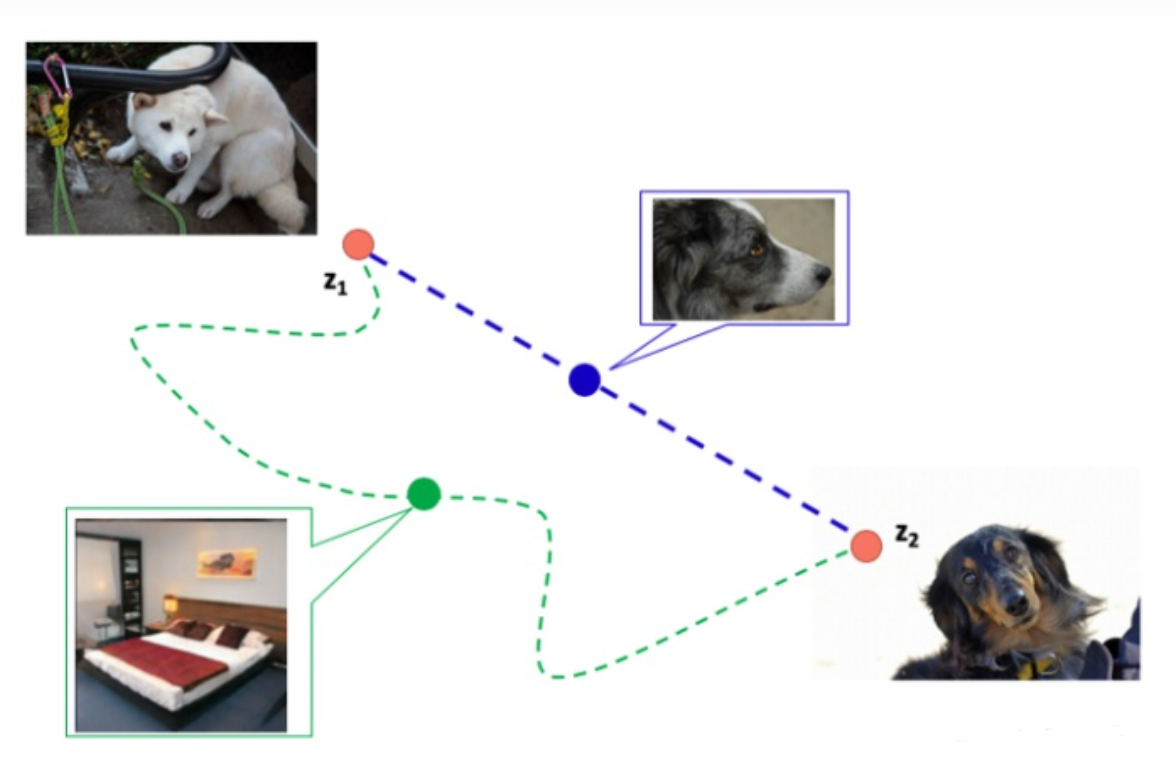
Perceptual path length
Perceptual path length 是一个指标,用于判断生成器是否选择了最近的路线(比如上图蓝色虚线),用训练过程中相邻时间节点上的两个生成图像的距离来表示
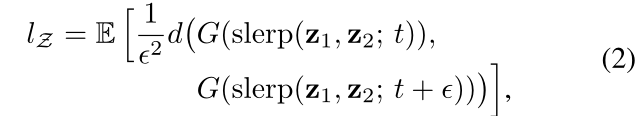
g 表示生成器,d 表示判别器, 表示mapping netwrok, 表示由latent code 得到的中间隐藏码 , , 表示某一个时间点, , $t+\varepsilon $ 表示下一个时间点,$lerp $表示线性插值 (linear interpolation),即在 latent space上进行插值。