
StableDiffusion
CompVis/stable-diffusion: A latent text-to-image diffusion model (github.com)
CVPR 2022
Intro
Disco-Diffusion:diffusion + clip,在全图像素上进行扩散,训练一个这样的模型需要数百个V100卡满载天数,而且下游推理同样费时费力。
扩散模型最大的问题是它的时间成本和经济成本都极其“昂贵”。Stable Diffusion的出现就是为了解决上述问题。如果我们想要生成一张 1024 × 1024 尺寸的图像,U-Net 会使用 1024 × 1024尺寸的噪声,然后从中生成图像。这里做一步扩散的计算量就很大,更别说要循环迭代多次直到100%。一个解决方法是将大图片拆分为若干小分辨率的图片进行训练,然后再使用一个额外的神经网络来产生更大分辨率的图像(超分辨率扩散)。
基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势。文生图模型往往参数量比较大,基于pixel的方法往往限于算力只生成64x64大小的图像,
- 比如OpenAI的DALL-E2和谷歌的Imagen,然后再通过超分辨模型将图像分辨率提升至256x256和1024x1024;
- 而基于latent的SD是在latent空间操作的,它可以直接生成256x256和512x512甚至更高分辨率的图像。
2021年发布的Latent Diffusion模型给出了不一样的方法。 Latent Diffusion模型不直接在操作图像,而是在潜在空间中进行操作。通过将原始数据编码到更小的空间中,让U-Net可以在低维表示上添加和删除噪声。 [2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models (arxiv.org)
潜在空间(Lantent Space)
潜在空间简单的说是对压缩数据的表示。
所谓压缩指的是用比原始表示更小的数位来编码信息的过程。
比如我们用一个颜色通道(黑白灰)来表示原来由RGB三原色构成的图片,此时每个像素点的颜色向量由3维变成了1维度。
维度降低会丢失一部分信息,然而在某些情况下,降维不是件坏事。通过降维我们可以过滤掉一些不太重要的信息,只保留最重要的信息。
Latent Diffusion
“潜在扩散模型”(Latent Diffusion Model)将GAN的感知能力、扩散模型的细节保存能力和Transformer的语义能力三者结合,创造出比上述所有模型更稳健和高效的生成模型。与其他方法相比,Latent Diffusion不仅节省了内存,而且生成的图像保持了多样性和高细节度,同时图像还保留了数据的语义结构。
感知压缩
在感知压缩学习阶段,学习方法必须去除高频细节将数据封装到抽象表示中。此步骤对构建一个稳定、鲁棒的环境表示是必要的。GAN 擅长感知压缩,通过将高维冗余数据从像素空间投影到潜在空间的超空间来实现这一点。潜在空间中的潜在向量是原始像素图像的压缩形式,可以有效地代替原始图像。
更具体地说,用自动编码器 (Auto Encoder) 结构捕获感知压缩。 自动编码器中的编码器将高维数据投影到潜在空间,解码器从潜在空间恢复图像。
语义压缩
在学习的第二阶段,图像生成方法必须能够捕获数据中存在的语义结构。 这种概念和语义结构提供了图像中各种对象的上下文和相互关系的保存。 Transformer擅长捕捉文本和图像中的语义结构。 Transformer的泛化能力和扩散模型的细节保存能力相结合,提供了两全其美的方法,并提供了一种生成细粒度的高度细节图像的方法,同时保留图像中的语义结构。
.
Method
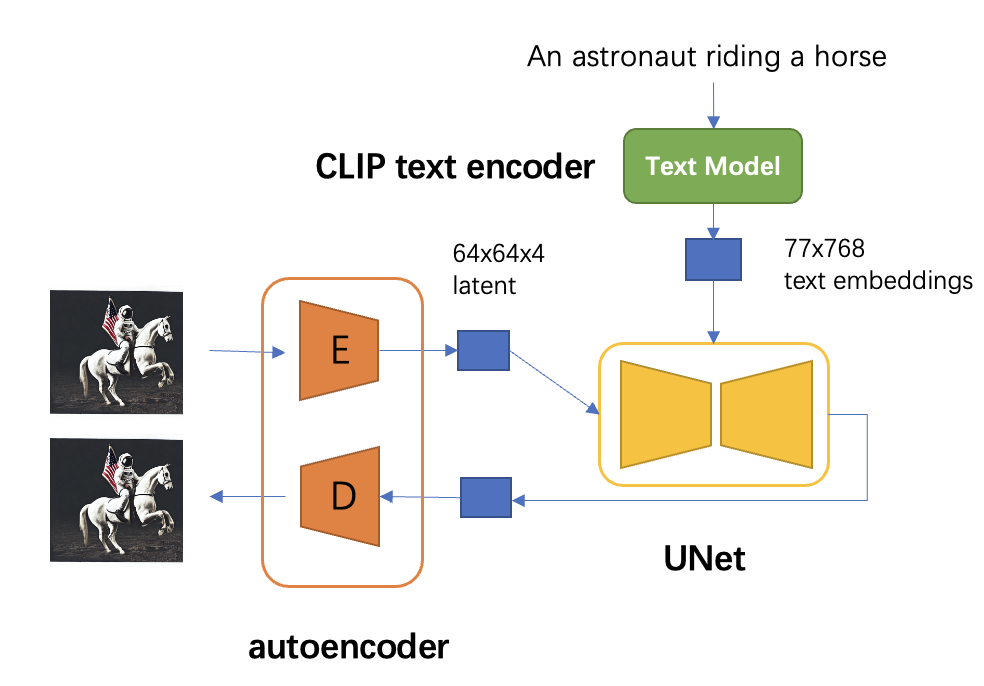
对于SD模型,其autoencoder模型参数大小为84M,CLIP text encoder模型大小为123M,而UNet参数大小为860M,所以SD模型的总参数量约为1B。
autoencoder
是一个基于encoder-decoder架构的图像压缩模型,对于一个大小为的输入图像,encoder模块将其编码为一个大小为 的latent,其中 为下采样率(downsampling factor)。
在训练autoencoder过程中,除了采用L1重建损失外,还增加了感知损失(perceptual loss,
即LPIPS,具体见论文The Unreasonable Effectiveness of Deep Features as a Perceptual Metric)
以及基于patch的对抗训练。
辅助loss主要是为了确保重建的图像局部真实性以及避免模糊
同时为了防止得到的latent的标准差过大,采用了两种正则化方法:
- 第一种是KL-reg,类似VAE增加一个latent和标准正态分布的KL loss,不过这里为了保证重建效果,采用比较小的权重(~10e-6);
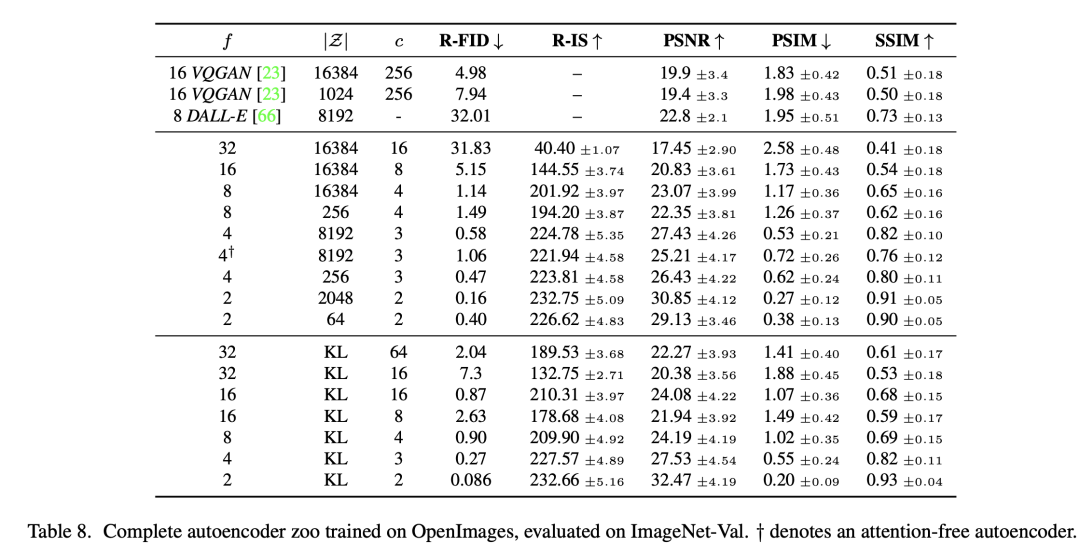
- 第二种是VQ-reg,引入一个VQ (vector quantization)layer,此时的模型可以看成是一个VQ-GAN,不过VQ层是在decoder模块中,这里VQ的codebook采样较高的维度(8192)来降低正则化对重建效果的影响。latent diffusion论文中实验了不同参数下的autoencoder模型,如下表所示,可以看到当 较小和 较大时,重建效果越好(PSNR越大)(此时压缩率小)。
论文进一步将不同的autoencoder在扩散模型上进行实验,在ImageNet数据集上训练同样的步数(2M steps),其训练过程的生成质量如下所示,
- 可以看到过小的(比如1和2)下收敛速度慢,此时图像的感知压缩率较小,扩散模型需要较长的学习;
- 而过大的其生成质量较差,此时压缩损失过大。
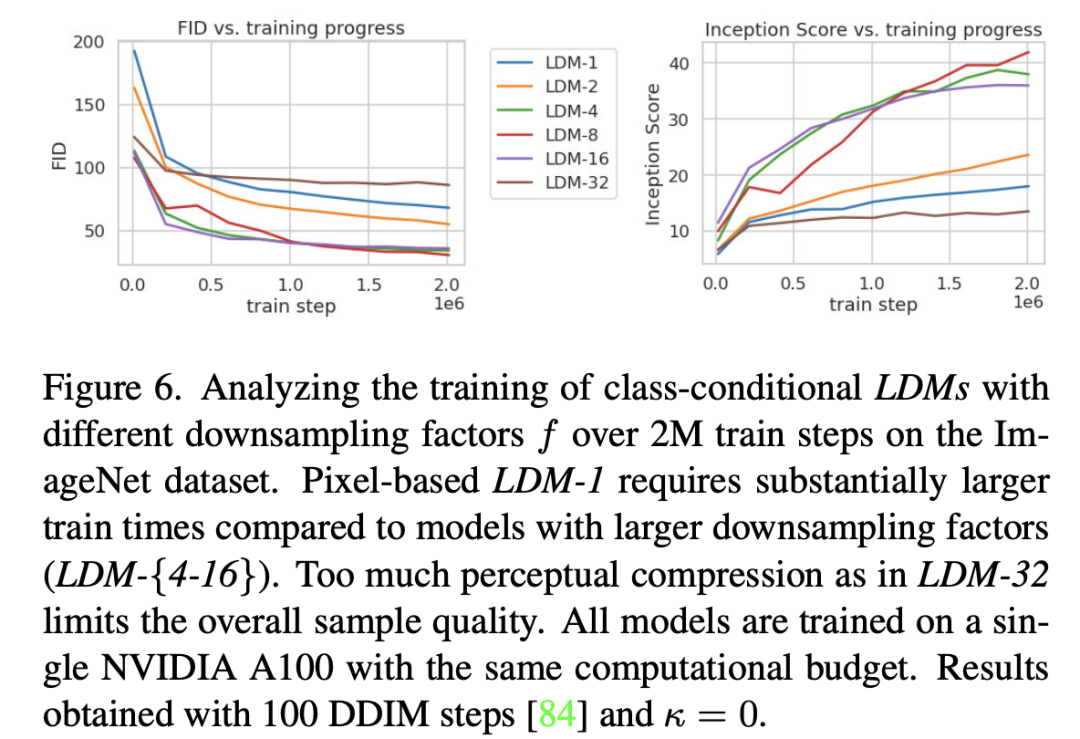
当在4~16时,可以取得相对好的效果。
SD采用基于KL-reg的autoencoder,其中下采样率 ,特征维度为,当输入图像为512x512大小时将得到64x64x4大小的latent。autoencoder模型时在OpenImages数据集上基于256x256大小训练的,但是由于autoencoder的模型是全卷积结构的(基于ResnetBlock),所以它可以扩展应用在尺寸>256的图像上。
CLIP text encder
SD采用CLIP text encoder来对输入text提取text embeddings,具体的是采用目前OpenAI所开源的最大CLIP模型:clip-vit-large-patch14,这个CLIP的text encoder是一个transformer模型(只有encoder模块):层数为12,特征维度为768,模型参数大小是123M。对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。
from transformers import CLIPTextModel, CLIPTokenizer
text_encoder = CLIPTextModel.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="text_encoder").to("cuda")
# text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14").to("cuda")
tokenizer = CLIPTokenizer.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="tokenizer")
# tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
# 对输入的text进行tokenize,得到对应的token ids
prompt = "a photograph of an astronaut riding a horse"
text_input_ids = text_tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt"
).input_ids
# 将token ids送入text model得到77x768的特征
text_embeddings = text_encoder(text_input_ids.to("cuda"))[0]值得注意的是,这里的tokenizer最大长度为77(CLIP训练时所采用的设置),当输入text的tokens数量超过77后,将进行截断,如果不足则进行paddings,这样将保证无论输入任何长度的文本(甚至是空文本)都得到77x768大小的特征。
在训练SD的过程中,CLIP text encoder模型是冻结的。
在早期的工作中,比如OpenAI的GLIDE和latent diffusion中的LDM均采用一个随机初始化的tranformer模型来提取text的特征,但是最新的工作都是采用预训练好的text model。比如谷歌的Imagen采用纯文本模型T5 encoder来提出文本特征,而SD则采用CLIP text encoder,预训练好的模型往往已经在大规模数据集上进行了训练,它们要比直接采用一个从零训练好的模型要好。
UNet
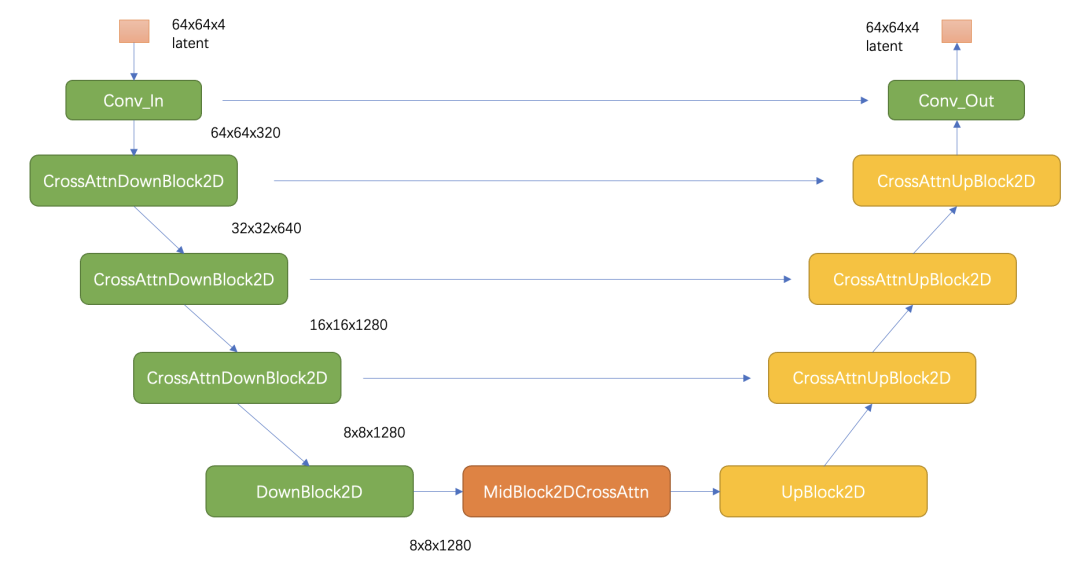
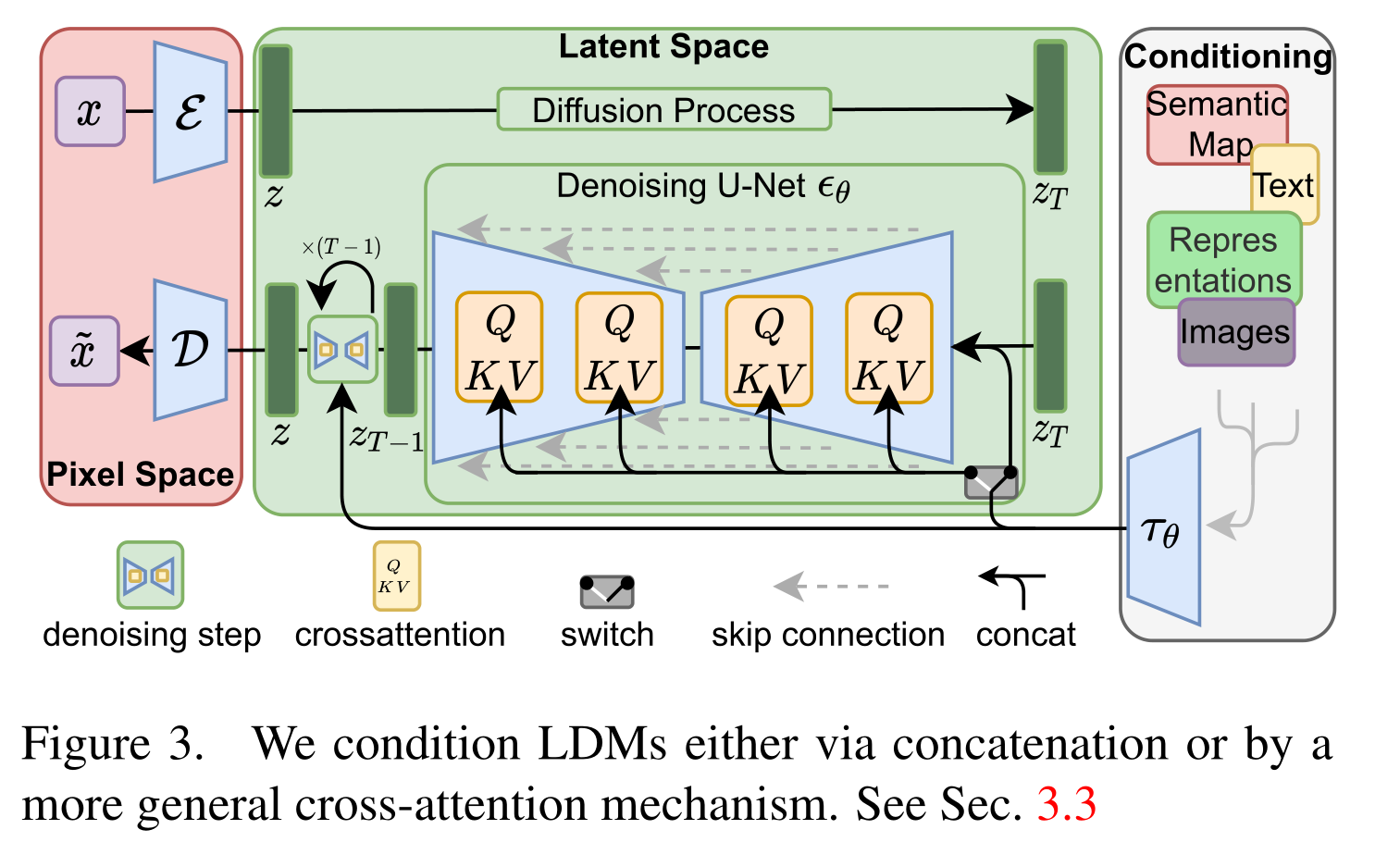
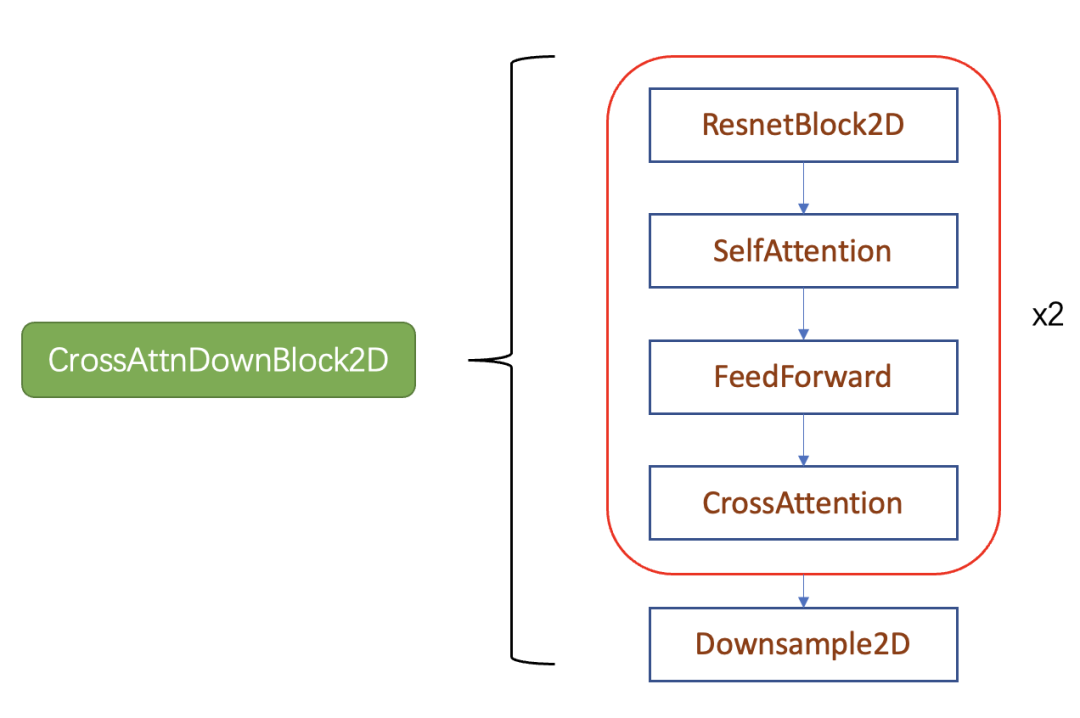
text condition将通过CrossAttention模块嵌入进来,此时Attention的query是UNet的中间特征,而key和value则是text embeddings。
SD和DDPM一样采用预测noise的方法来训练UNet,其训练损失也和DDPM一样
应用
text2image
image2image
image inpainting
总结
最本质来说,SD相当于VQGAN里的Transformer被替换成了diffusion model。
论文的另一个核心贡献是探索了使用cross-attention做多模态的条件扩散生成。
总之,我们的工作做出了以下贡献:
(i) 与纯粹基于transformer的方法 [23、64] 相比,我们的方法可以更优雅地扩展到更高维的数据,因此可以 (a) 在压缩级别上工作,提供更多比以前的工作(见图 1)和(b)忠实和详细的重建可以有效地应用于百万像素图像的高分辨率合成。
(ii) 我们在多项任务(无条件图像合成、修复、随机超分辨率)和数据集上实现了有竞争力的性能,同时显着降低了计算成本。与基于像素的扩散方法相比,我们还显着降低了推理成本。
(iii) 我们表明,与同时学习编码器/解码器架构和基于分数的先验的先前工作 [90] 相比,我们的方法不需要对重建和生成能力进行微妙的加权。这确保了极其忠实的重建,并且几乎不需要对潜在空间进行正则化。
(iv) 我们发现,对于超分辨率、修复和语义合成等密集条件任务,我们的模型可以以卷积方式应用,并渲染 ∼ 10242 像素的大而一致的图像。
(v) 此外,我们设计了一种基于交叉注意力的通用调节机制,支持多模态训练。我们用它来训练类条件、文本到图像和布局到图像模型。
(vi) 最后, 发布预训练的潜在扩散和自动编码模型,除了训练 DM 之外,它可能可重复用于各种任务