条件扩散
unconditional DDPM
根据郎之万动力方程的推导,最终的生成表达式中依赖神经网络对噪声的预测可以生成图像,但是这种生成是没有任何约束的,也就是说给定纯高斯噪声,我们就能生成图片。好处是我们的输入不受任何控制,只要是高斯噪声就可以,坏处是我们无法监督这一过程,最终生成的结果不受控制。
Guided Diffusion/Diffusion Models Beat GANs on Image Synthesis
https://proceedings.neurips.cc/paper/2021/file/49ad23d1ec9fa4bd8d77d02681df5cfa-Paper.pdf
第一次,classifier guidance
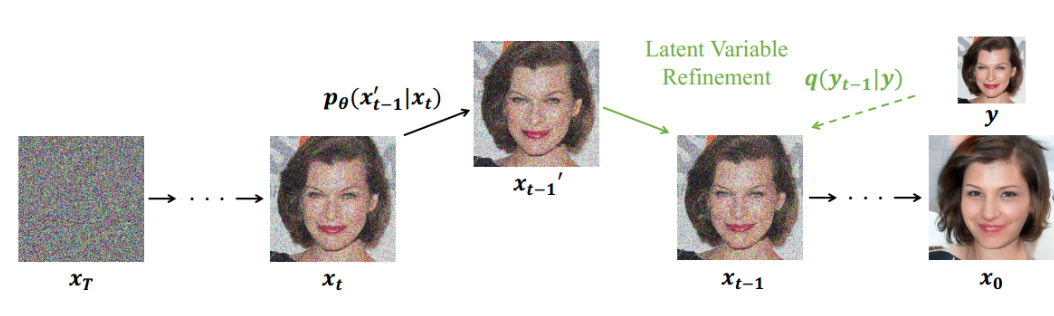
ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models
sample全程加入参考图片
ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models - 知乎 (zhihu.com)
这篇论文是直接基于DDPM的工作上展开的受控图像生成。其主要针对的痛点是DDPM的随机性太高无法确定性的生成,导致我们很难控制模型生成带有我们想要的语义信息的图片。
其核心思想非常地简洁但精巧:
- 我们的前向和后向是一个等长的过程。其中前向时原数据的信息逐渐丢失(先丢失高频信息再丢失低频信息)而后向时信息逐渐从纯噪声中补全(先补全低频信息再到高频信息)。
- 如果我们记录下前向过程里每一步的噪声图像,将其与后向过程中的噪声图像混合,我们就可以影响后向过程的生成结果(考虑极端情况完全替换后向过程的噪声图像的话则一定可以轻易地回到原图)。
- 而我们通过影响混合时注入的前向信息的多少,或者后向时注入信息的时间步的多少,可以控制所生成的图与原图的相似程度。具体来说,其算法如下:其中 是一个低通滤波器加上一系列降维再升维保持图像维度不变的过程。

创新点
DDPM模型已经在无条件生成方面取得了显著的成就,然而,由于其生成过程的随机性,对该模型做可控生成十分具有挑战性。
- 本文提出了一个Iterative Latent Variable Refinement(ILVR)来指导DDPM在给定reference image的条件下能够生成高质量的图片样本。
- 同时,这样控制的方法可以让一个DDPM模型在无需额外模型或学习过程参与的情况下适用于multi-domain image translation,editing with scribbles等应用任务。
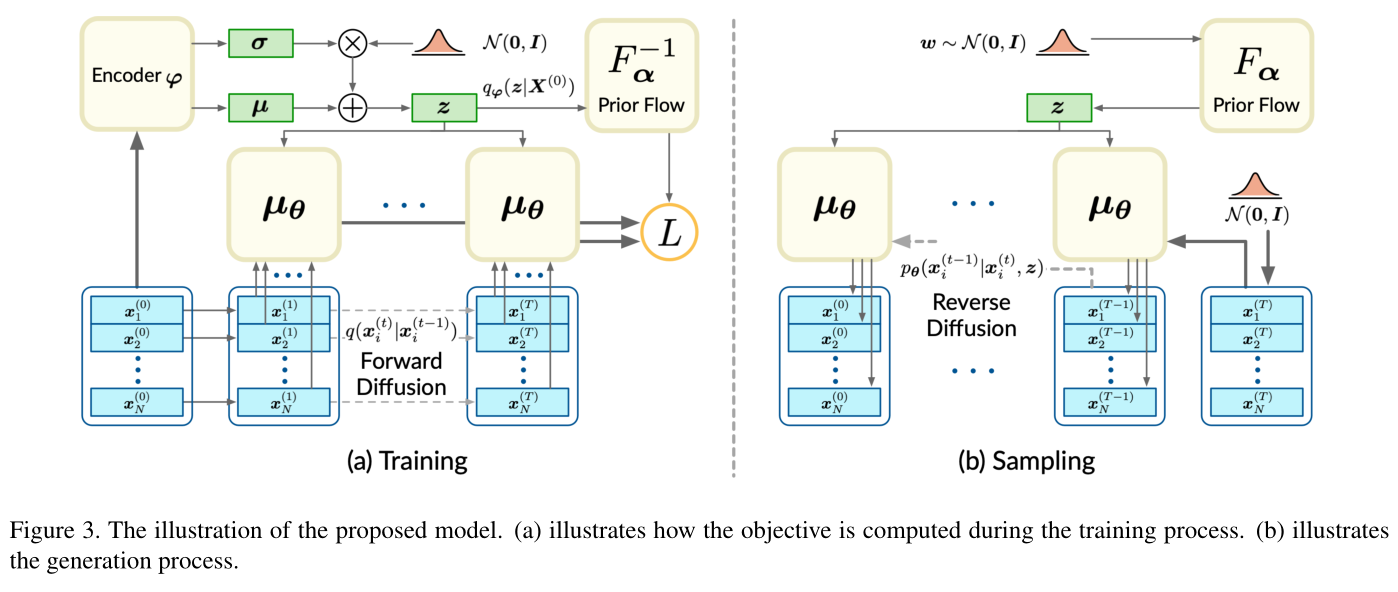
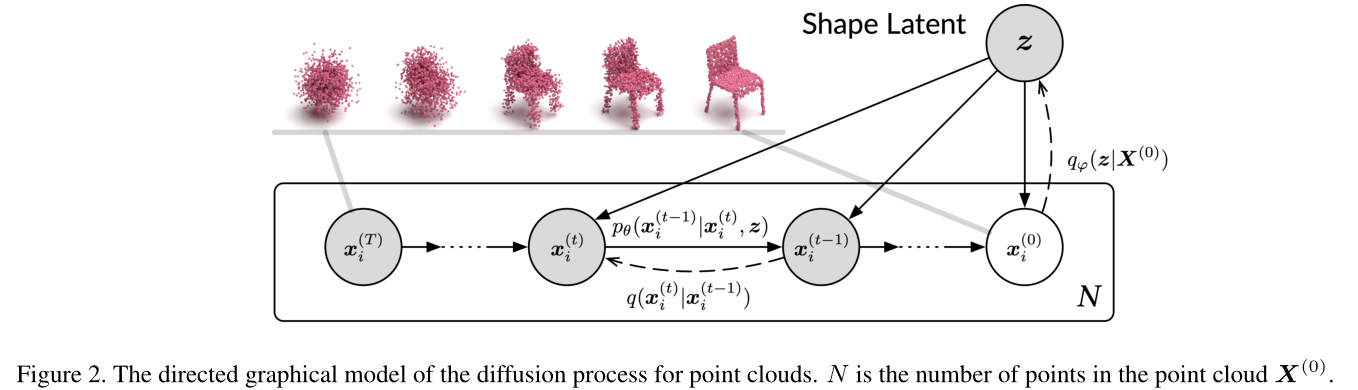
Diffusion Probabilistic Models for 3D Point Cloud Generation
点云生成:Diffusion Probabilistic Models for 3D Point Cloud Generation_
使用学习到的潜变量 Z 控制点云形状
由于马尔可夫链的目的是对点分布进行建模,因此仅靠马尔可夫链无法生成各种形状的点云。为此,我们引入了一个潜在的形状作为过渡内核的条件。在生成设置中,潜在形状遵循先验分布,我们通过归一化流 [5、6] 对其进行参数化,以获得强大的模型表现力。
在自动编码的设置中,潜在的形状是端到端学习的。最后,我们将训练目标制定为最大化以潜在形状为条件的点云似然的变分下界,进一步将其制定为封闭形式的易处理表达式。我们将我们的模型应用于点云生成、自动编码和无监督表示学习,结果表明我们的模型在点云生成和自动编码方面取得了有竞争力的性能,并且在无监督表示学习方面取得了可比的结果。