
DiffSeg
Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion

Aug.23.2023
相关工作
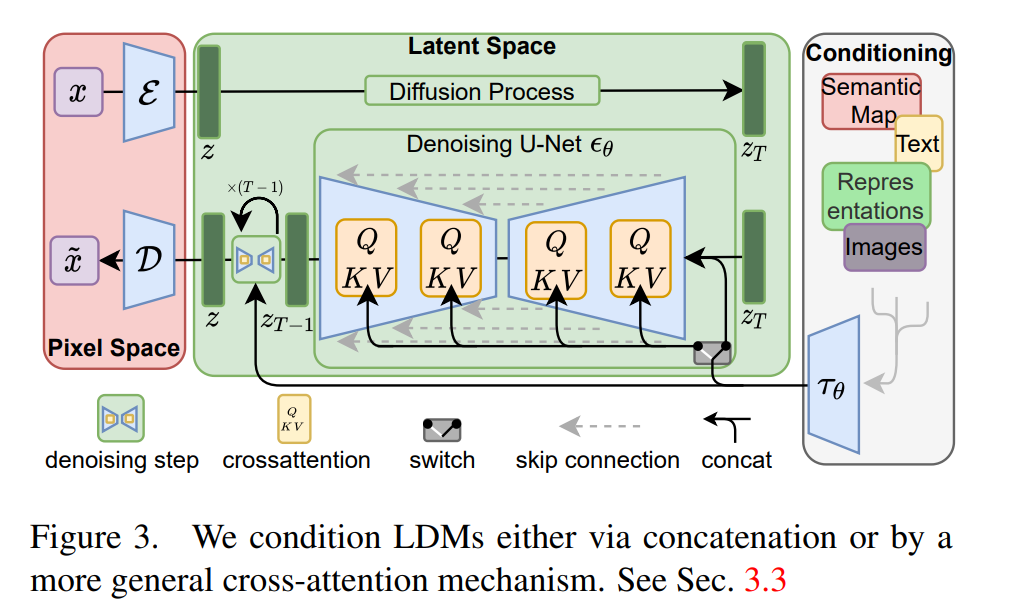
Transformer Decoder
https://github.com/CompVis/latent-diffusion/blob/a506df5756472e2ebaf9078affdde2c4f1502cd4/ldm/modules/attention.py#L196C40-L196C40
class BasicTransformerBlock(nn.Module):
def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True, checkpoint=True):
super().__init__()
self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout) # is a self-attention
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
self.attn2 = CrossAttention(query_dim=dim, context_dim=context_dim,
heads=n_heads, dim_head=d_head, dropout=dropout) # is self-attn if context is none
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.norm3 = nn.LayerNorm(dim)
self.checkpoint = checkpoint
def forward(self, x, context=None):
return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
def _forward(self, x, context=None):
x = self.attn1(self.norm1(x)) + x
x = self.attn2(self.norm2(x), context=context) + x
x = self.ff(self.norm3(x)) + x
return x方法
理论依据
Intra-Attention Similarity
一张 attn map 中,同一个 object group 附近相似。
Inter-Attention Similarity
同一个 object group 具有相似 attn map 。

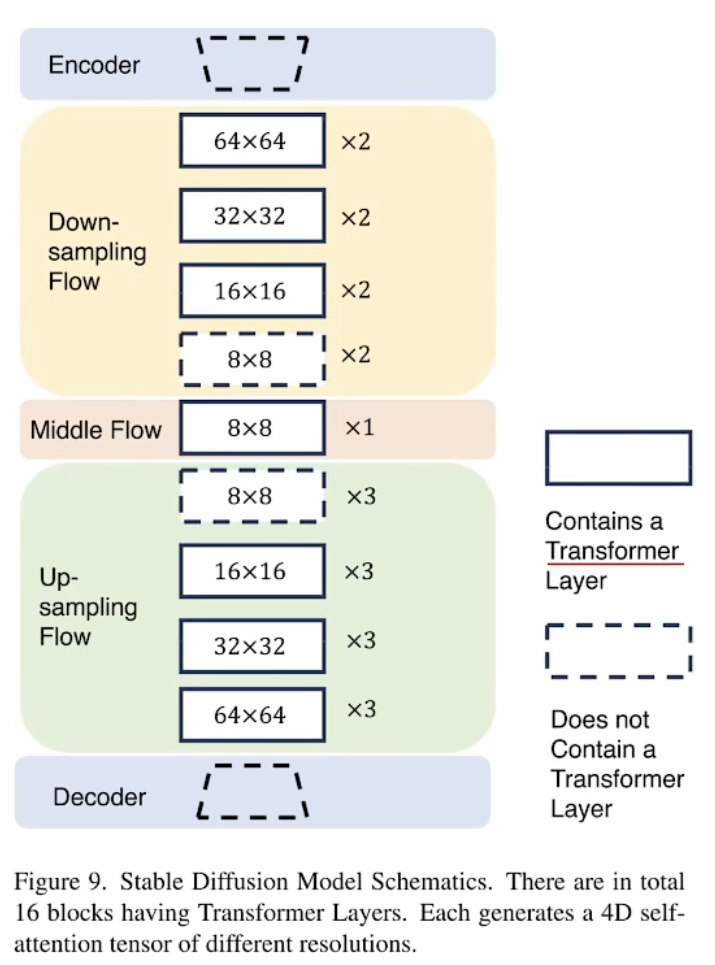
attention map
总共16个注意力层
- 使用无条件的 latent
- 仅运行一次SD
- t = 300,近似无噪音输入
如何处理多头注意力
由于多头注意力机制,存在第五个维度。
每个注意力层都有 8 个多头输出。我们沿着多头轴平均注意力张量以减少到 4 个维度,因为它们在这个维度上非常相似。
实验中,多头之间的差异远小于不同map之间kl散度的阈值,即使不平均在后面也会被合并。
Attention Aggregation
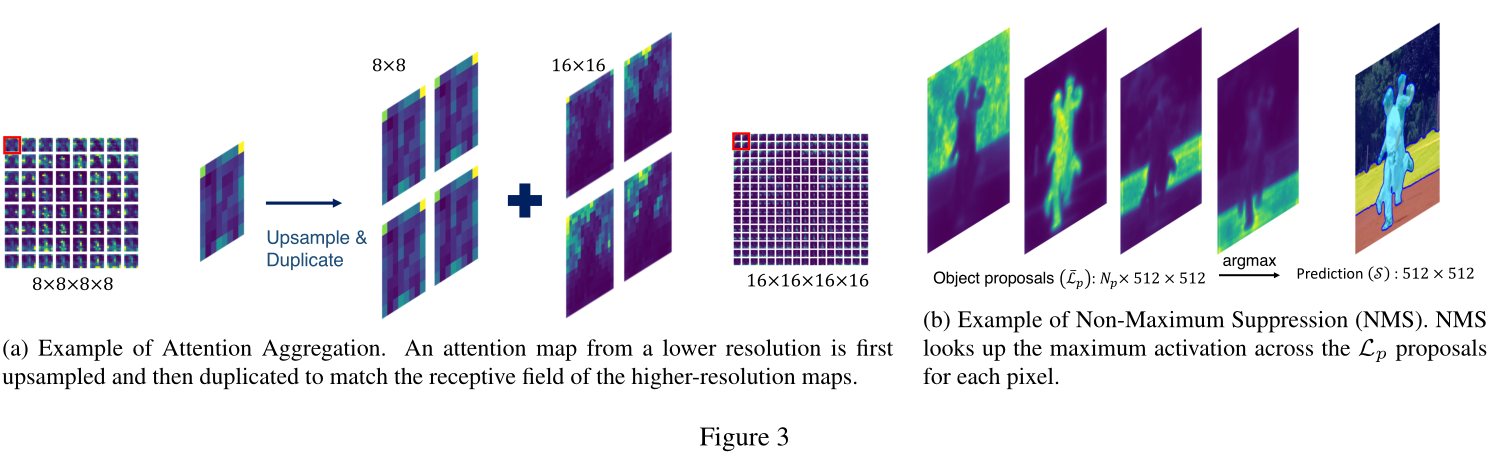
对齐张量
- 不同大小的map使用双线性插值扩大
- 归一化,保持和为1
- 不同数量的map进行复制
- 不同大小的map使用双线性插值扩大
相加,聚合成
- 聚合权重,正比于map分辨率
Iterative Attention Merging
- 采样 64 个点(anchors)
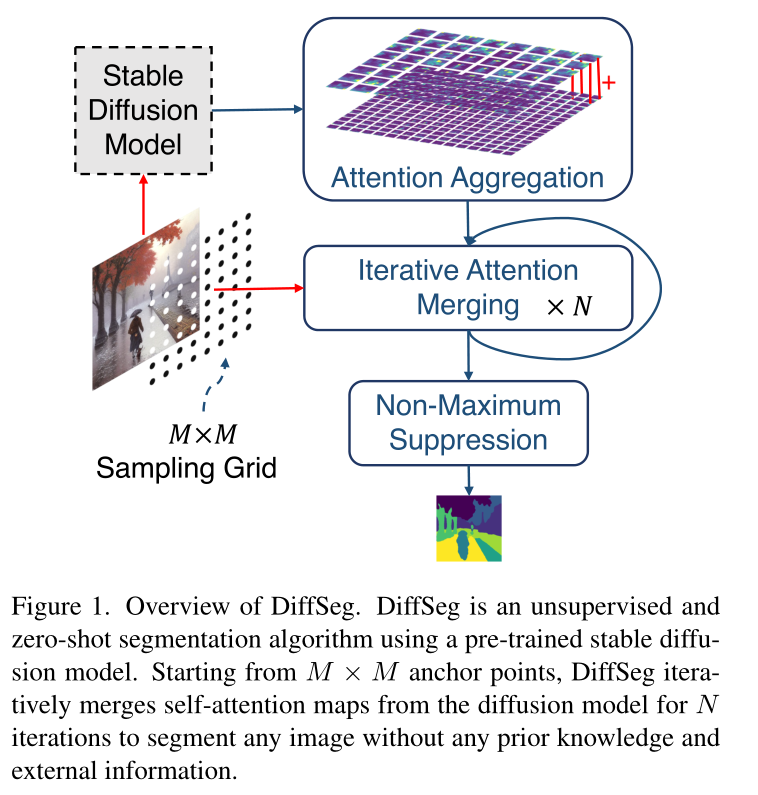

,sample grid,从 中采样
, attn maps,
N, iterations,
, threshold
第一次迭代
- 根据相似程度,将不同的maps聚类到不同的anchors上
- KL散度,
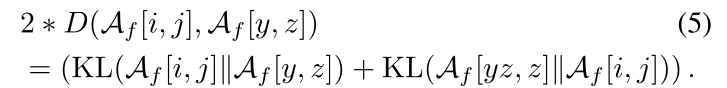
- KL散度具有方向,取正反两个方向相加
- KL散度,
- 对每个聚类的anchors中的maps进行平均,得到这个anchor的attn map
- 根据相似程度,将不同的maps聚类到不同的anchors上
后续
- 与第一次迭代类似,不同的是对anchor进行聚类和平均,减少anchor数量
- 类似 mean shift
- 与第一次迭代类似,不同的是对anchor进行聚类和平均,减少anchor数量
双线性插值
非极大抑制
提示
KL 散度不是距离指标,没有对称性
用其他方式衡量相似的?
Wasserstein Distance
【数学】Wasserstein Distance - 知乎 (zhihu.com)
Covariance
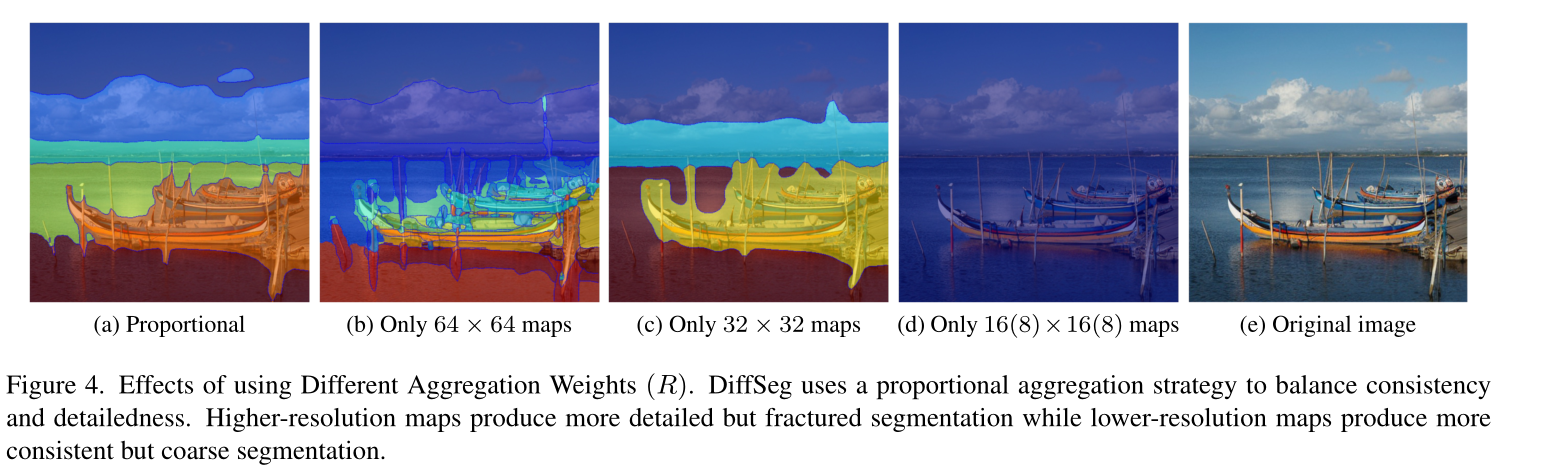
结果
类似工作
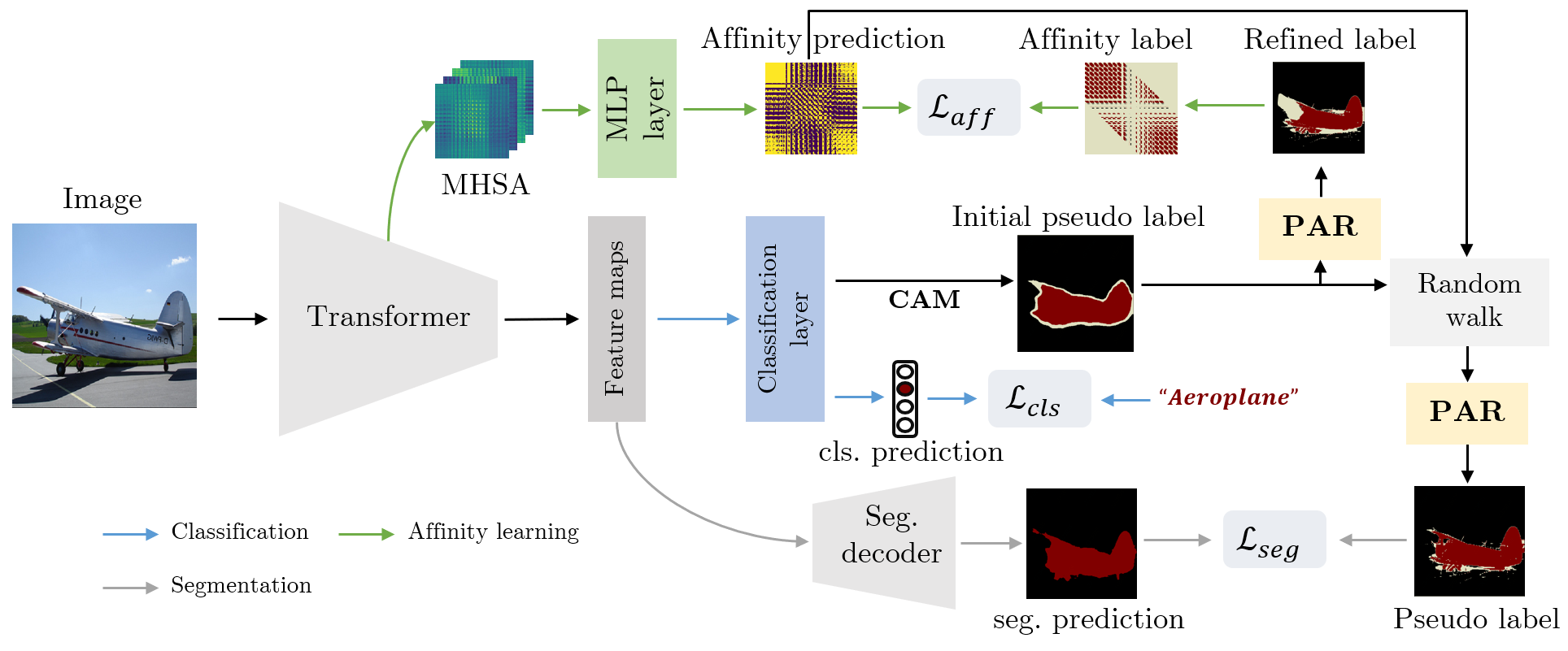
AffinityNet
论文笔记]AffinityNet_动如脱兔((≡ຶ̑ꀬ≡ຶ̑))静如脱兔的博客-CSDN博客
输入:原始图像
输出:图像中相邻坐标像素对的语义相似度
仅通过图像级标签预测像素级别的语义相似度
根据给定的图像和生成的CAM,首先建立一个邻域图,其中每个像素都在一定半径内与其邻域相连,通过AffinityNet估计图中连通像素对的语义相似度。
针对每一个类别,CAM中稀疏的激活区域通过随机游走策略传播到周围语义相同的区域,并对传播到其他语义类别的区域进行处罚。这种语义扩散对CAMs区域起到了很大的修正作用。
本文利用这个过程来进行训练,通过获取的每个像素位置与CAM对应类标签的关联性合成像素级的分割标签。生成的分割标签用于训练分割模型。
类似文章,把cnn的feature 换成了 transform 的feature
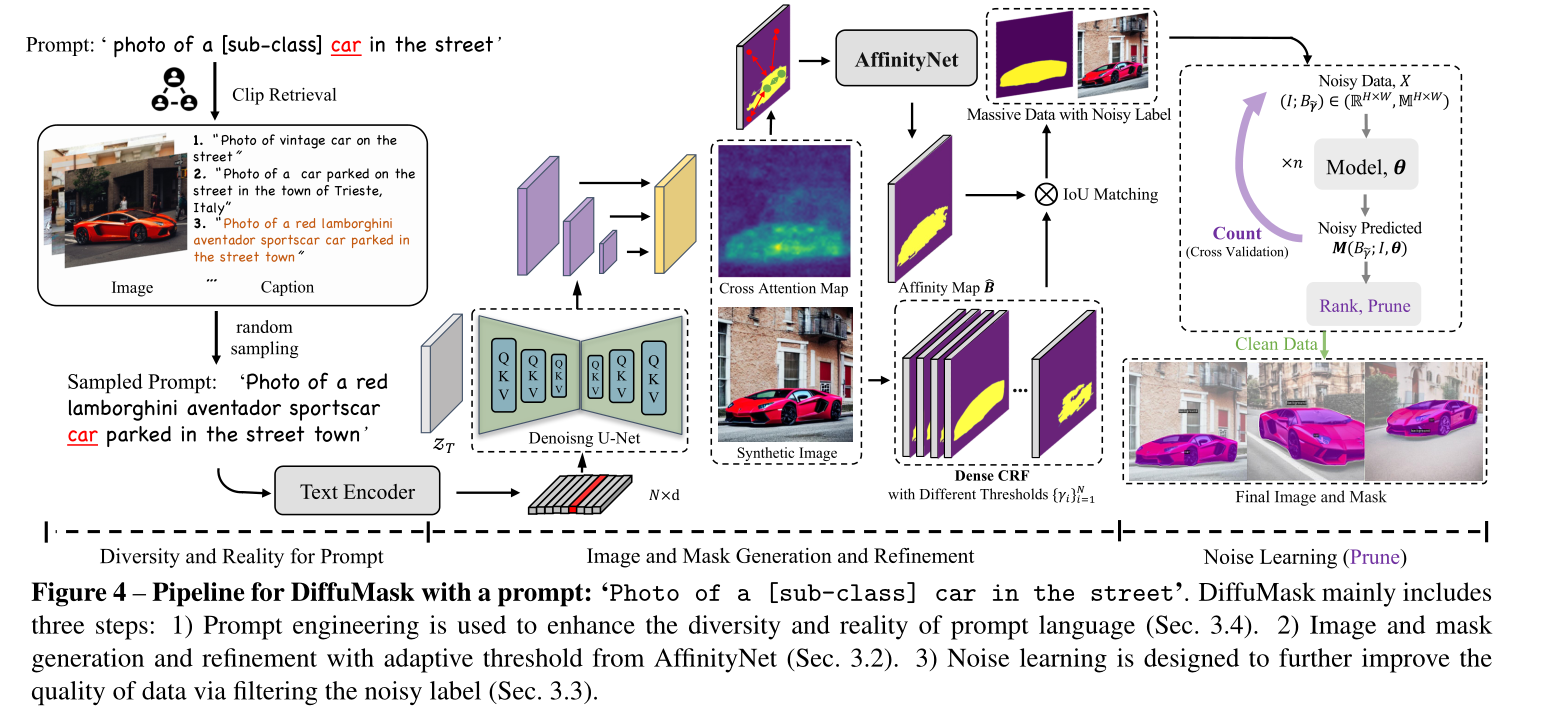
DiffuMasks
ICCV 2023
生成图片的同时生成mask,跨模态,文本监督
ReCo
Reco: Retrieve and co-segment for zero-shot transfer.
NeurIPS'22 ReCo: Retrieve and Co-segment for Zero-shot Transfer (github.com)
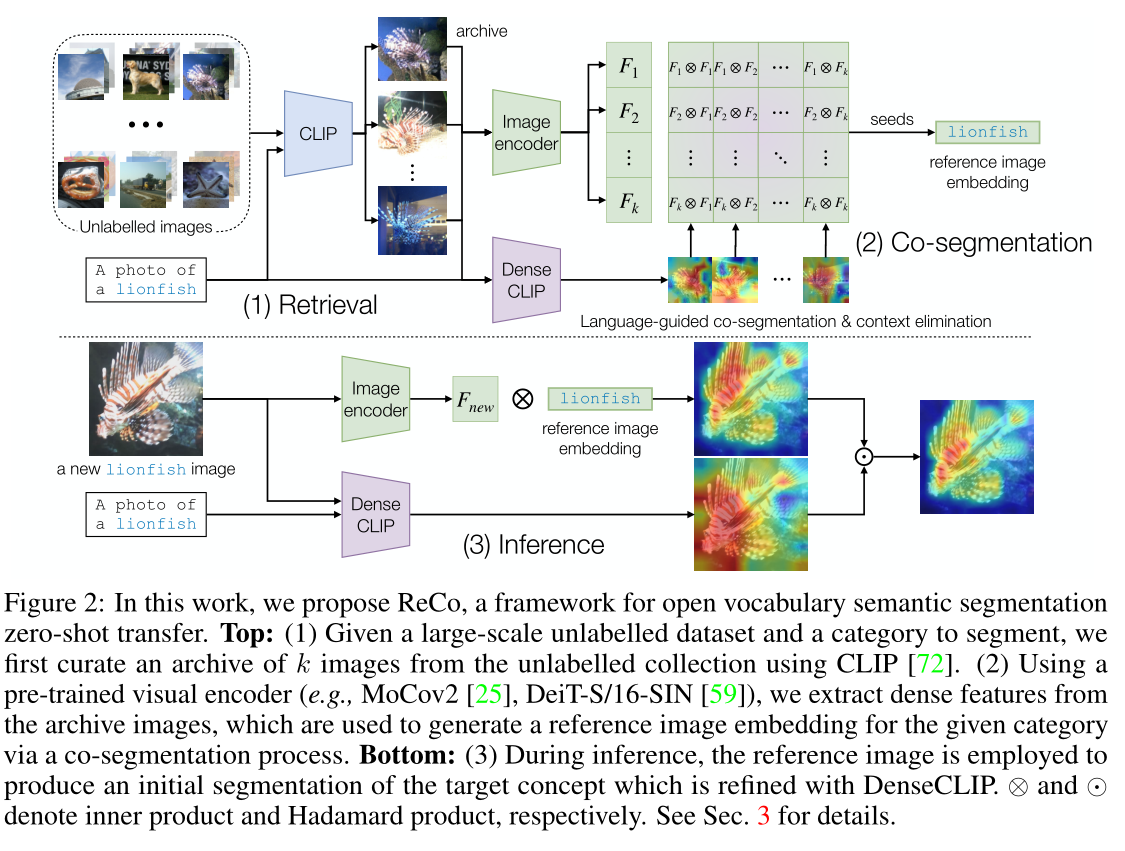
不懂
ReCo 的输入是未标记图像的集合以及要分割的概念的文本描述列表。通过将图像检索和图像集合中的联合分割相结合,ReCo 可以动态地为给定的概念构建分割器。在推理过程中,应用该分割器时无需对感兴趣的目标分布中的图像进行微调,从而支持零样本传输。
Dense Clip
将 clip 的 text - image 工作进一步拓展到 text - pixel ,以实现分割
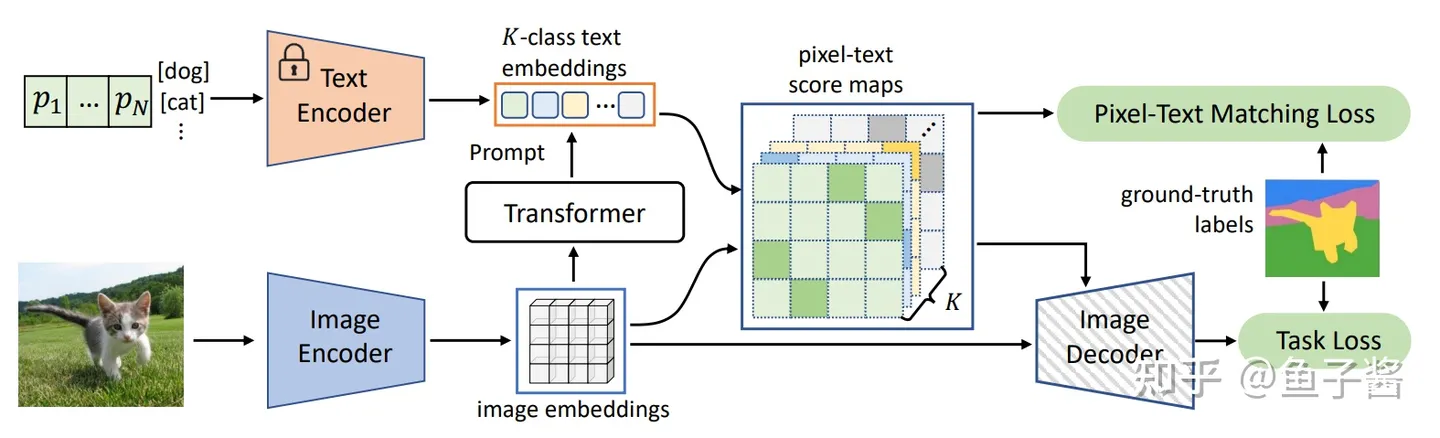
Network-free
cvpr‘2023
Network-Free, Unsupervised Semantic Segmentation With Synthetic Images | Papers With Code
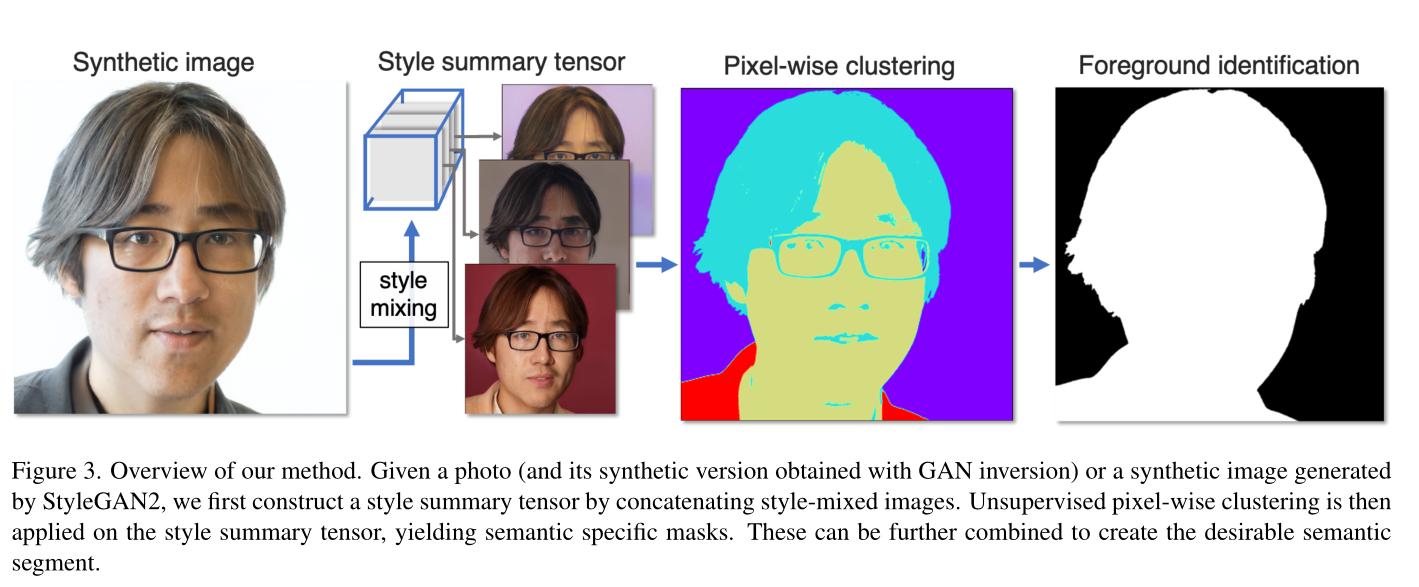
核心idea
当使用 GAN 中的风格混合方法生成图像的合成变体时,属于同一语义段的一组像素的相关性不会改变。
ToCo
CVPR 2023 Token Contrast for Weakly-Supervised Semantic Segmentation (github.com)
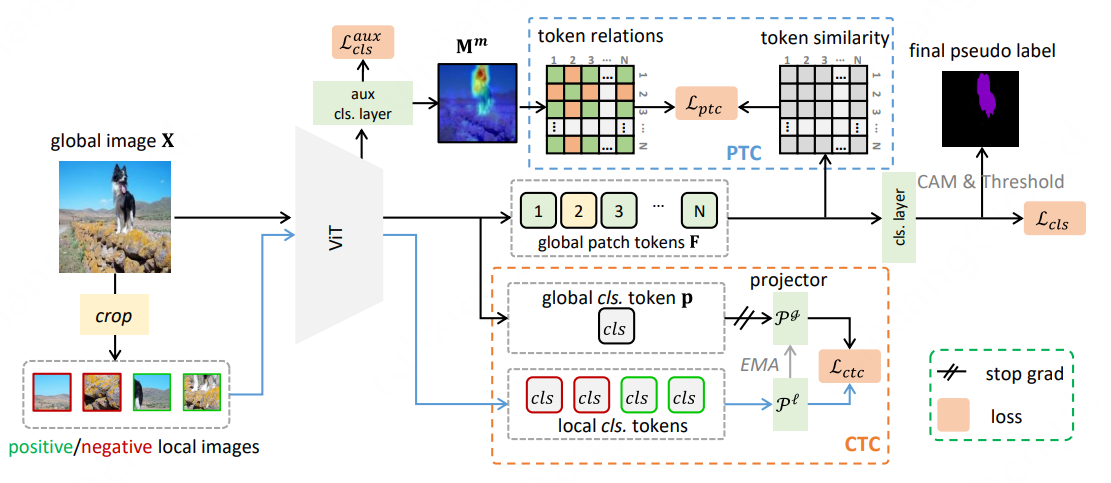
CAM: Class Activation Map, 分类网络预测图像时的激活区域。
EMA: 指数移动平均(Exponential Moving Average)也叫权重移动平均(Weighted Moving Average),是一种给予近期数据更高权重的平均方法。
- vit存在的过度平滑问题,feature map
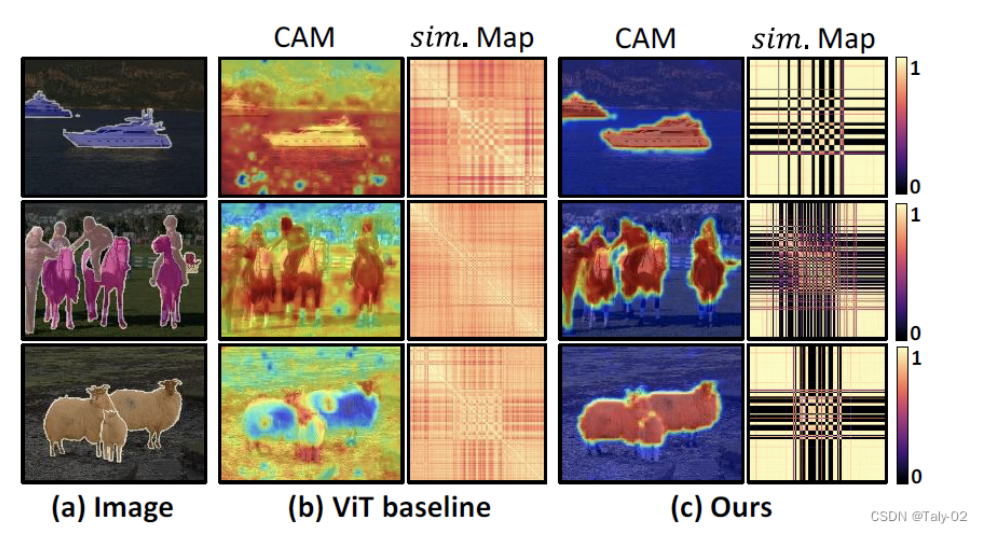
PTC:Patch Token Contrast
利用中间层(第十个encoder)的输出外接辅助分类层得到Mm,主要是因为中间层仍然可以保持语义多样性,由它生成的token relations Y作为global patch tokens F的监督,可以解决vit存在的过度平滑问题。
CTC:ClassTokenContrast
PTC解决了vit存在的过度平滑问题,生成效果不错的辅助cam。然而,仍然存在一些识别能力较弱的难以区分的对象区域。
受ViT中class token 可以聚合高级语义的特性,设计了(class Token Contrast, CTC)模块,提高伪标签质量。
从辅助CAM Mm指定的不确定区域和背景区域对原始图像进行随机裁剪得到局部图像,将其分配为正样本(来自不确定区域)或负样本(来自背景区域)。
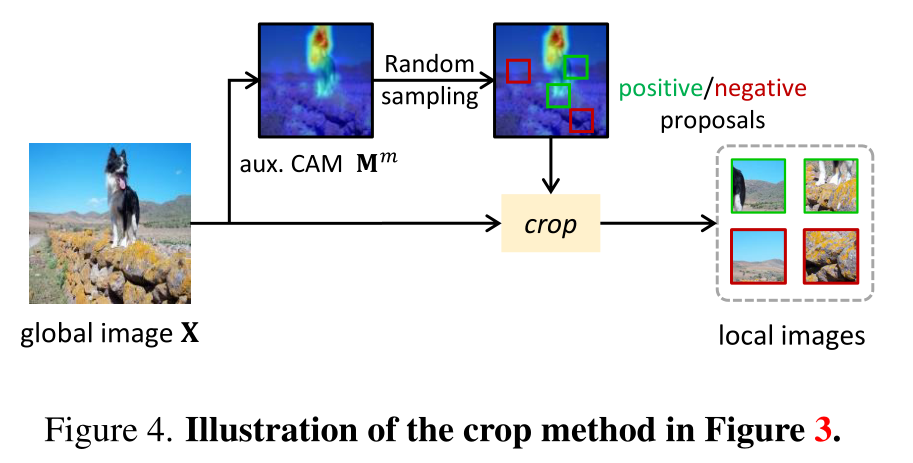
通过最小化全局class token P和正样本之间的差异(在不确定区域中激活出更多的前景区域),最大化全局class token P和负样本之间的差异(加大前景和背景的差异),
整个ctc loss 通过最小化全局class token 和局部class token 来促进局部非显著区域与全局对象之间表示的一致性,从而进一步强制从CAM中激活更多的对象区域。