
CLIP引导生成
Learning Transferable Visual Models From Natural Language Supervision
26 Feb 2021
CLIP: Connecting text and images (openai.com)
CLIP from OpenAI: what is it and how you can try it out yourself | by Inmeta | Medium
出发点
- 传统的图像分类模型无法对类别进行拓展,想要保证准确率只能从头开始训练,费时费力。
- CLIP模型就可以用来解决这种问题,预训练后的模型就可以直接进行zero-shot
成果
- 将图像和任意的文本联系起来,只需要简单地提供包含新类别的文本描述就可以使用该模型来识别新类别。
- CLIP在完全不使用ImageNet中所有训练数据的前提下直接Zero-shot得到的结果与ResNet在128W ImageNet数据训练效果一致
- CLIP使用4亿个配对的数据和文本来进行训练,不标注直接爬取(没有解决transformer训练所需数据量大的缺点)
Train
以一个batch size为N的输入为例,
- 首先,N张图像和N个文本分别被各自模态的Encoder编码成高维向量。
- 然后,用它们的向量表示建立一个相似度矩阵(图中,I*T表示两模态向量的内积)。值得注意的是,在训练过程中,矩阵对角线上的内积是匹配图文的内积(即当前batch内,文本T1和图像I1是匹配的图文对,而文本T1和图像I2是不匹配的图文对)。我们知道内积越大,相似度越高,因此匹配的图文对的相似度(内积)必须高于同一行/列中其他图文对的相似度(内积)才合理。
- 于是,训练的目标可以看作是在进行对比,对比的目的是使同一行/列中匹配图文的内积尽可能大,不匹配图文的内积尽可能小。我们也可以用更通俗的方式来理解:每一行都是一个分类任务,给定一个输入图像I,预测匹配的那个文本是谁。同理,每一列都是一个分类任务:给定输入文本T,预测匹配的那张图像是谁。
- 在训练期间,Open AI使用了非常大规模的batch size(32768),这可以充分发挥这种对比训练的潜力。
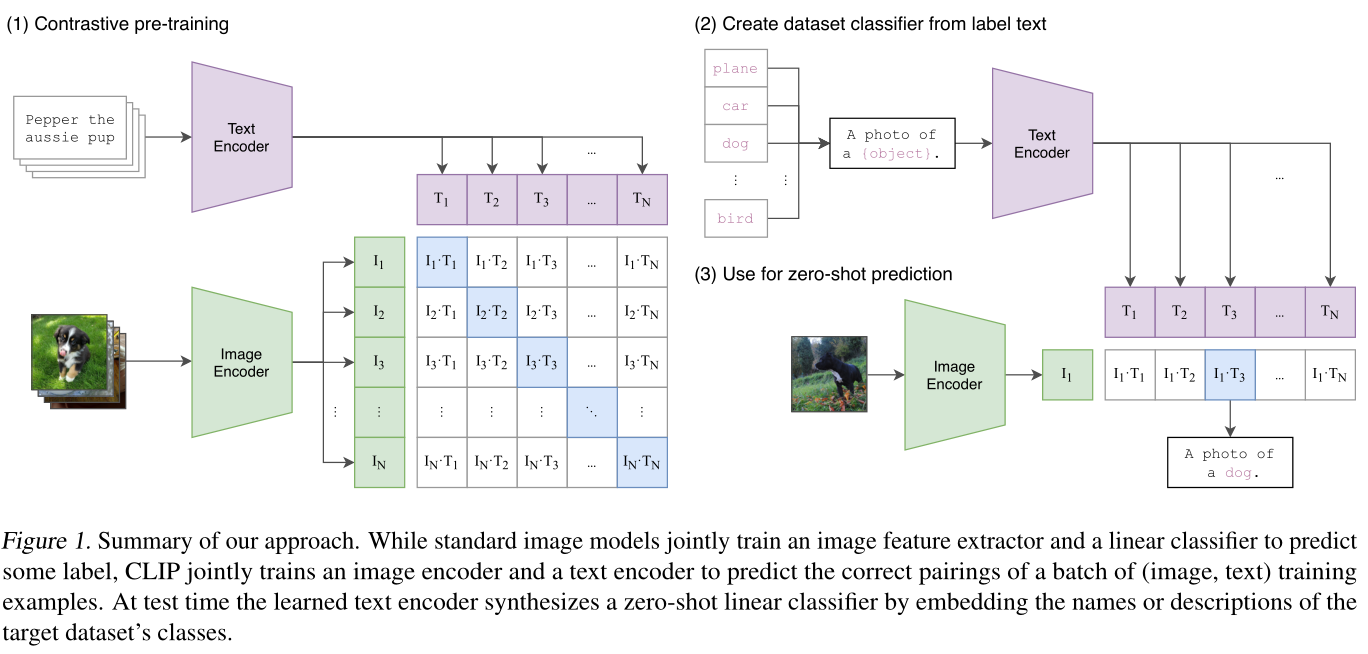
标准图像模型联合训练图像特征提取器和线性分类器来预测某些标签,而 CLIP 联合训练图像编码器和文本编码器来预测一批(图像、文本)训练示例的正确配对。在测试时,学习的文本编码器通过嵌入目标数据集类的名称或描述来合成零样本线性分类器。
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2infer
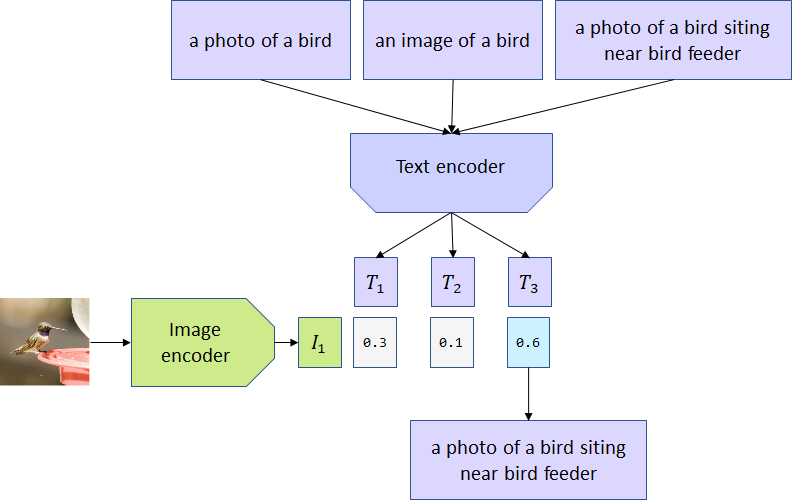
在推理过程中,使用者可以按照prompt(提示词)的格式自定义新文本。将新文本和图像送入CLIP模型后,通过内积值的大小来判断新文本和图像是否是匹配的。如下图所示,提示词是a photo of a {object}.,我们只需要将我们想判断的类别跟{object}进行替换即可。例如,我想判断这个图片是不是狗,我的新文本就是a photo of a dog.
经典的分类训练只关心模型是否可以正确预测图像的分类标签。如果模型预测成功了狗,那么它不在乎图像是一张狗的照片,还是一张狗的素描。而CLIP模型在大规模数据集上完成的训练,这使得CLIP模型还学习到了图像的各方面信息。
例如,CLIP模型对用于图像描述的单词很敏感。文本“a photo of a bird”、“a photo of a bird siting near bird feeder”或“an image of a bird”与相同的图像匹配产生的概率是不同的。
结果
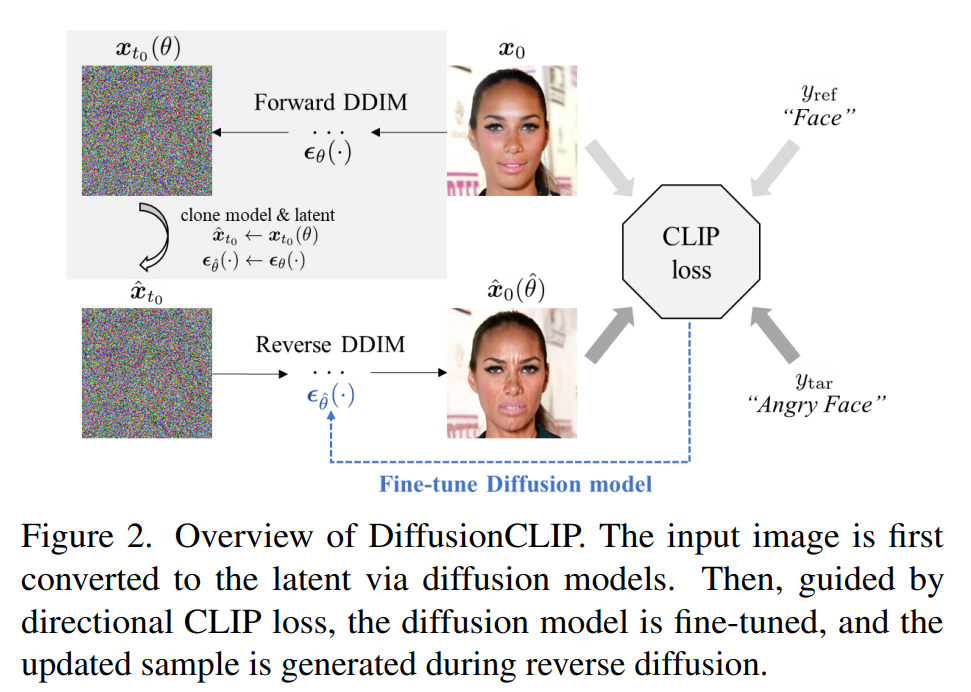
CLIP损失引导生成
DiffusionCLlP
DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation | Papers With Code
CVPR 2022
过使扩散生成时的图像和目标文本的多模态CLIP损失尽可能小。
CLIP Loss
其中 是图像编码器对生成图和原图的编码向量差,是文本编码器对目标文本和原文本的编码向量的差。
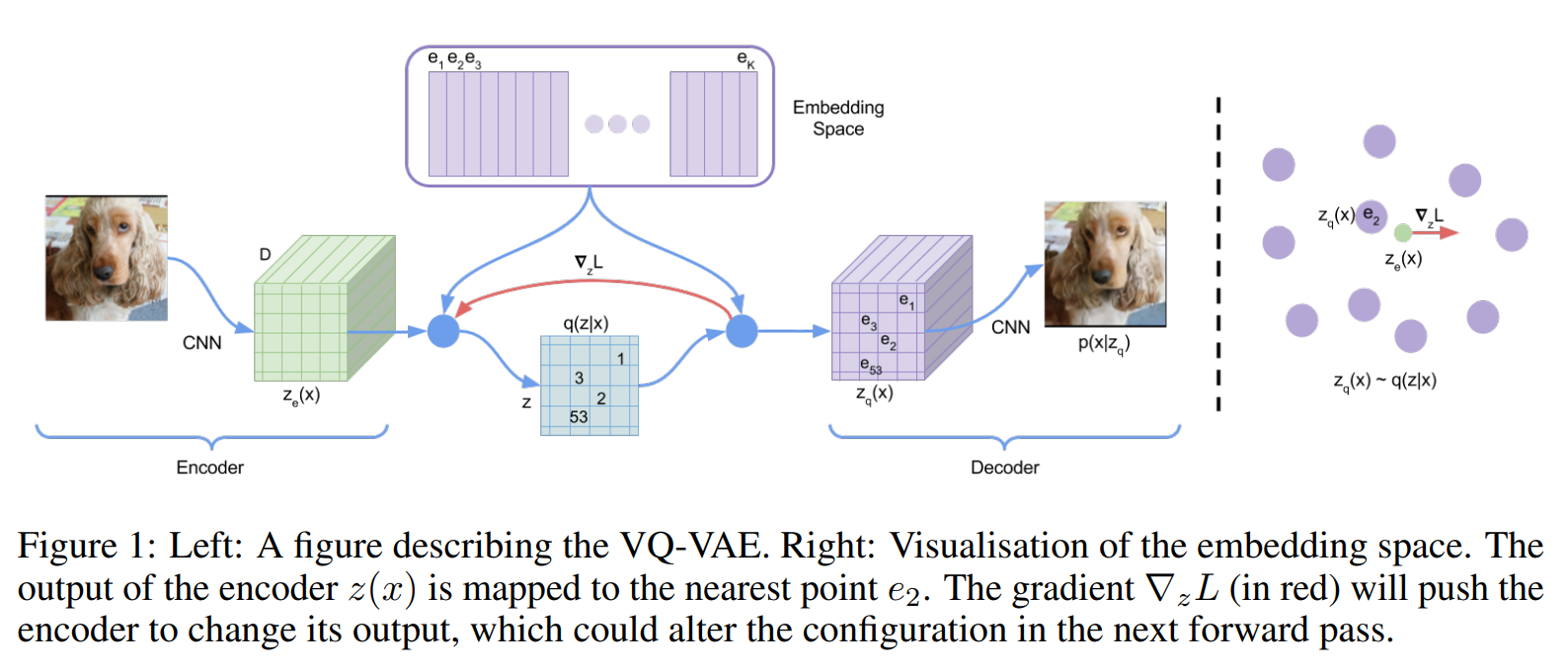
VQ-VAE
VQGAN
Taming Transformers for High-Resolution Image Synthesis
驯化transformer来生成高解析度图像
问题
图像的序列长度远比自然语言高。自然语言模型往往将生成序列的长度控制在1024或512内,但如果将自然语言模型里的transformer用来自回归式逐位生成像素的话,1024的长度只能生成32*32大小的图像。并且,attention的计算复杂度是随着序列长度的增长以平方级增长的,这样就限制了能生成图像的大小。虽然相比于CNN,transformer并不对输入进行任何先验的假设(例如平移不变性,局部性等)并且因此能够很好地拟合输入间复杂的关系,但这种普适泛化性也意味着你需要更充足的训练和更广泛的搜索范围。
**有没有办法既兼具CNN的先验偏置,又兼具transformer建模序列的泛化性?**这篇文章主要在探讨如何解决这个问题。作者提出了以下洞见:CNN的归纳偏置可以很好地概括图像的底层结构特性(例如它的局部性),但这种偏置对于语义层面(即图像的整体理解,全局把握)的建模用处不大。
方法
提出了一种CNN+GAN+Transformer的结构来生成高精度图像。
- 第一个步骤先训练一个VQVAE模型,其中CNN负责作为编码器,将图像编码成一个个具体且感知丰富(由感知损失Perceptual loss和GAN共同完成)的离散编码向量,再由解码器(也是CNN架构)还原原图像。
- 而在得到了编解码器后采样生成的第二个步骤时,训练一个transformer来学习第一步里的离散编码向量序列间的关系。
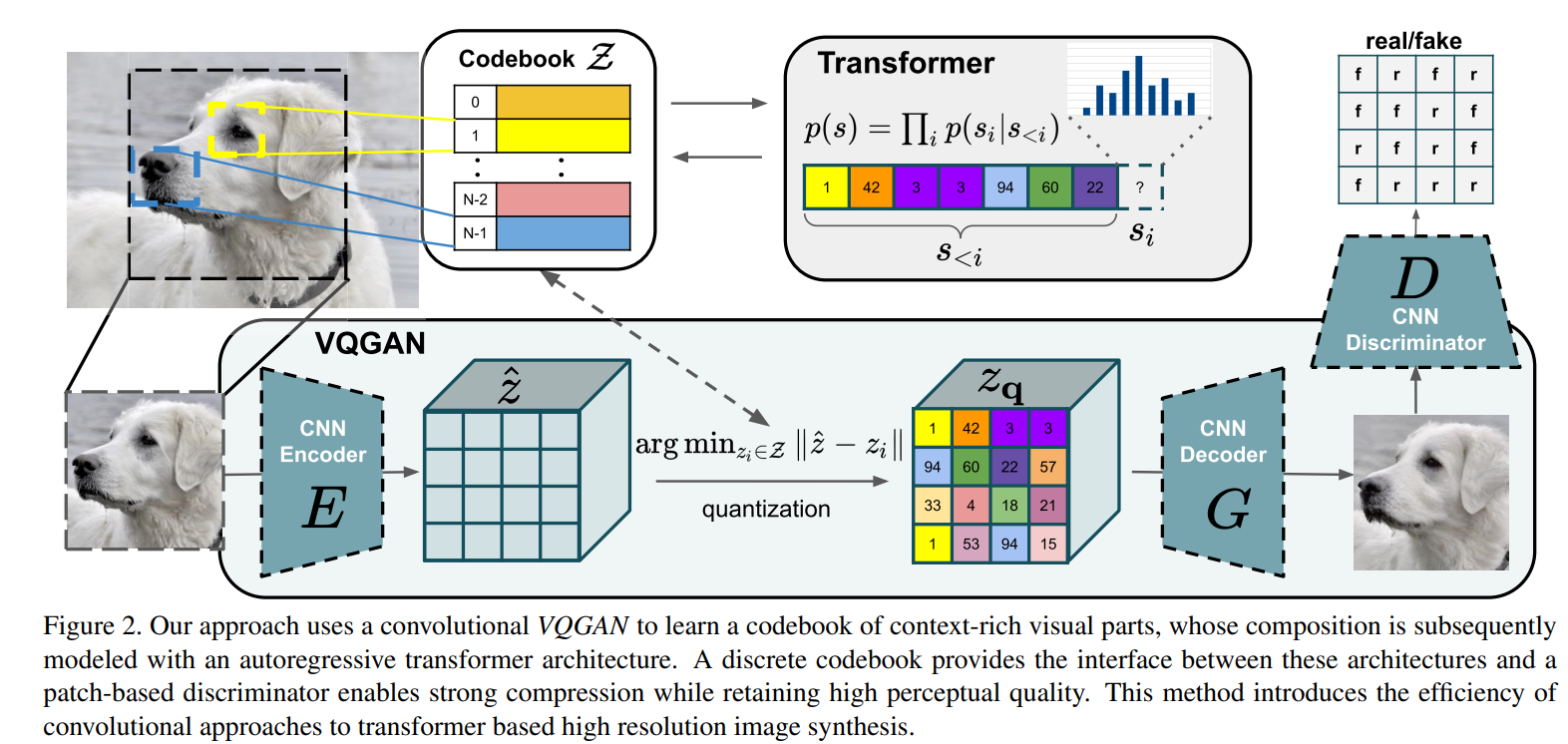
VQGAN或者DALL-E都使用了Transformer架构将潜在空间里的离散索引序列的建模问题转化为了一维的序列生成问题。 ????
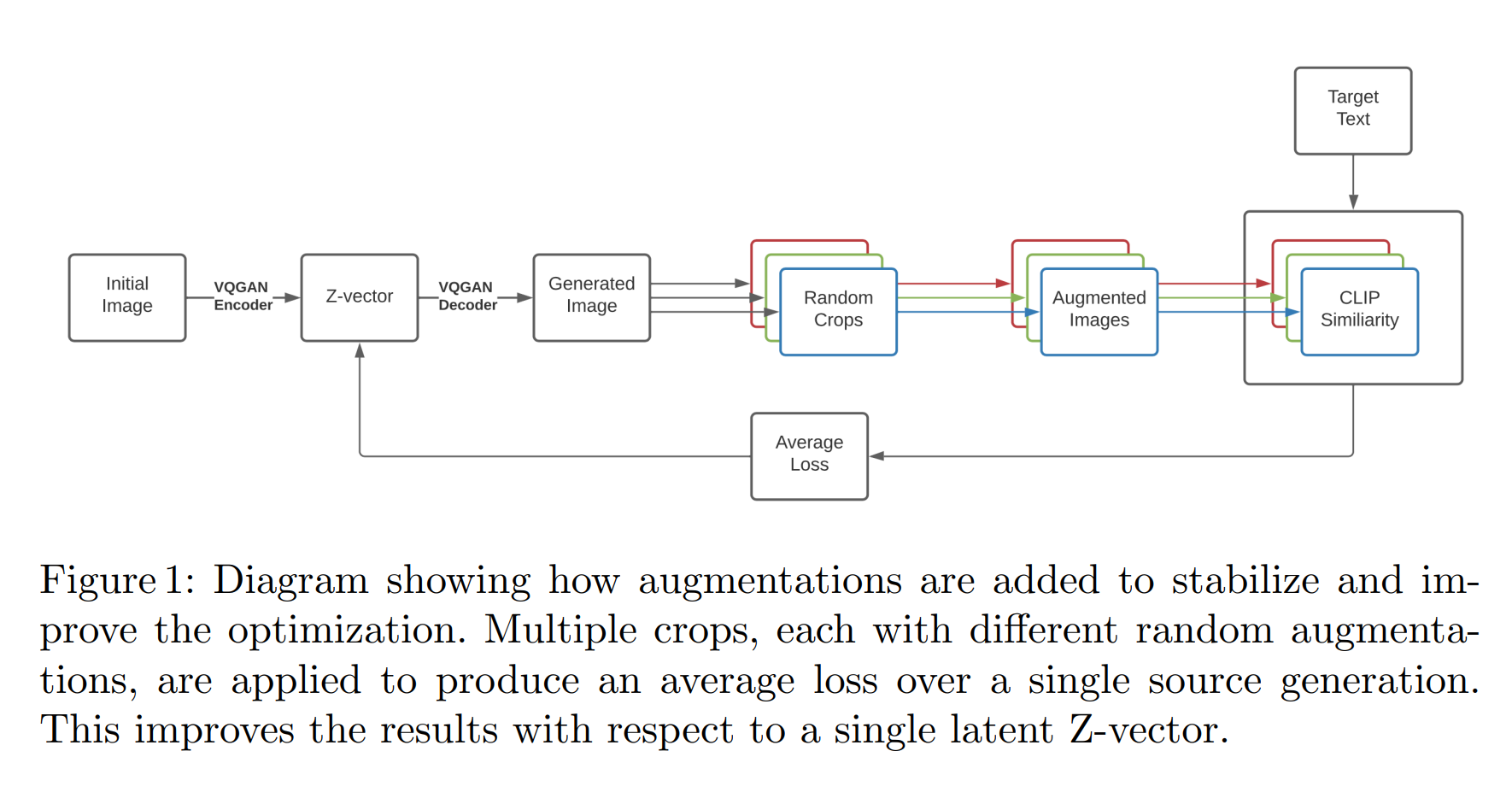
VQGAN-CLIP
用一个多模态的编码器来计算文和图的编码向量的余弦相似度,并将该相似度以损失的形式传递给图像生成器,不断迭代直到收敛。而这种流程对于用文本引导从零生成和以图生图的区别仅在于输入是随机噪声还是给定图像。
Stable-Diffusion
CompVis/stable-diffusion: A latent text-to-image diffusion model (github.com)
CVPR 2022
Disco-Diffusion:diffusion + clip,在全图像素上进行扩散,训练一个这样的模型需要数百个V100卡满载天数,而且下游推理同样费时费力。
总结
最本质来说,SD相当于VQGAN里的Transformer被替换成了diffusion model。
论文的另一个核心贡献是探索了使用cross-attention做多模态的条件扩散生成。