
Score based Diffusion model
[ 生成模型新方向]: score-based generative models_sooner高的博客-CSDN博客
Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song (yang-song.net)
生成模型分类:
- likelihood based models
- 直接队数据分布进行你和
- VAE
- normalizing flow models
- 缺点:对于网络结构设计有很大限制
- 直接队数据分布进行你和
- implicit generative models
- 间接对数据分布进行拟合
- GANs
- 缺点:往往需要对抗学习,不容易训练
- 间接对数据分布进行拟合
方法
score based model 不是直接学习概率分布,而是学习 score.
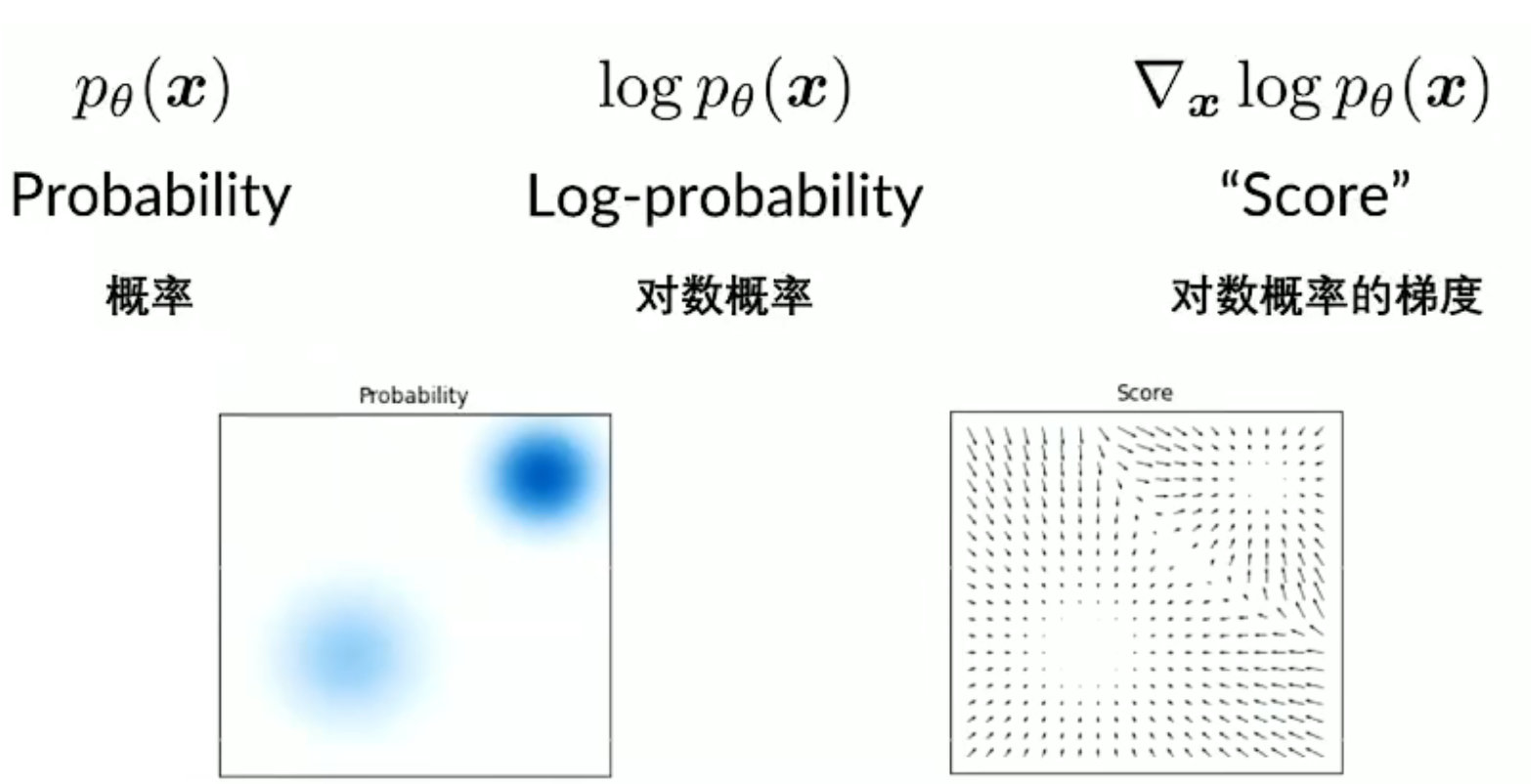
假设我们通过某种方法(score match)得到了 score 模型:
通过郎之万动力学的迭代过程从任意一个分布走到目标分布:
上式给出了一种从随机采样噪声出发一步步逼近目标数据的方法
- 步长
问题
在数据密度较低的位置,score的估计往往是不准确的
导致在推理的早期,模型容易根据错误的梯度二脱轨
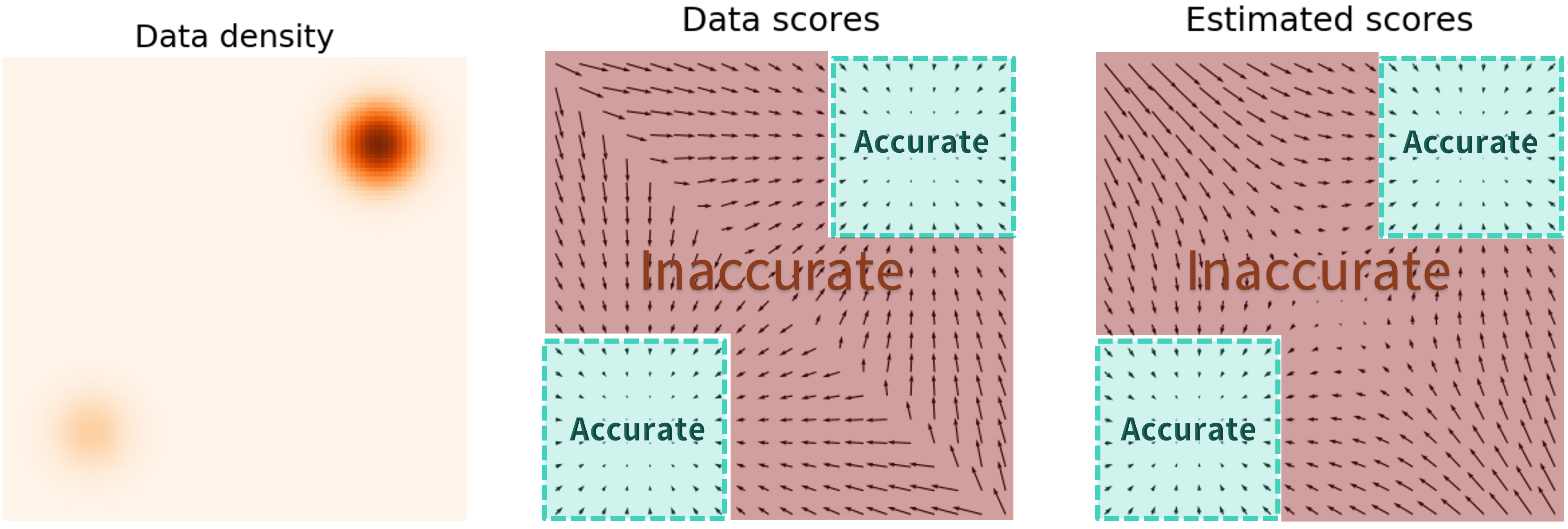
解决方法
对数据加噪声,扩大数据范围,增加可以准确估计score的区域

要加少强度的噪声?
较弱的噪声——避免损害原本的数据分布——无法在大多数区域准确估计score
较强的噪声——损害原本的数据分布——更多区域可以准确估计score
解决方法:
- 在推理的不同阶段加不同强度的噪声,从大到小

求 score
DDPM的噪声假设:
密度分布函数:
score:
推导:
score 和加在原图上的噪声仅仅相差一个系数的关系,可以用一个噪声估计网络来估计
目标函数:
- 不同噪声尺度的加权结果
image inpainting


总结
为什么要加噪声:
增加扰动,扩大数据范围,增加可以准确估计score的区域
为什么要估计噪声:
估计噪声就是估计score,也就是估计数据分布的对数梯度