
扩散模型与受控图像生成
扩散模型与受控图像生成-脉络梳理 - 知乎 (zhihu.com)
扩散模型与受控图像生成
基于迭代去噪过程的图像编辑
IVLR:Conditioning Method for Denoising Diffusion Probabilistic Models
ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models - 知乎 (zhihu.com)
这篇论文是直接基于DDPM的工作上展开的受控图像生成。其主要针对的痛点是DDPM的随机性太高无法确定性的生成,导致我们很难控制模型生成带有我们想要的语义信息的图片。
其核心思想非常地简洁但精巧:
- 我们的前向和后向是一个等长的过程。其中前向时原数据的信息逐渐丢失(先丢失高频信息再丢失低频信息)而后向时信息逐渐从纯噪声中补全(先补全低频信息再到高频信息)。
- 如果我们记录下前向过程里每一步的噪声图像,将其与后向过程中的噪声图像混合,我们就可以影响后向过程的生成结果(考虑极端情况完全替换后向过程的噪声图像的话则一定可以轻易地回到原图)。
- 而我们通过影响混合时注入的前向信息的多少,或者后向时注入信息的时间步的多少,可以控制所生成的图与原图的相似程度。具体来说,其算法如下:其中 是一个低通滤波器加上一系列降维再升维保持图像维度不变的过程。
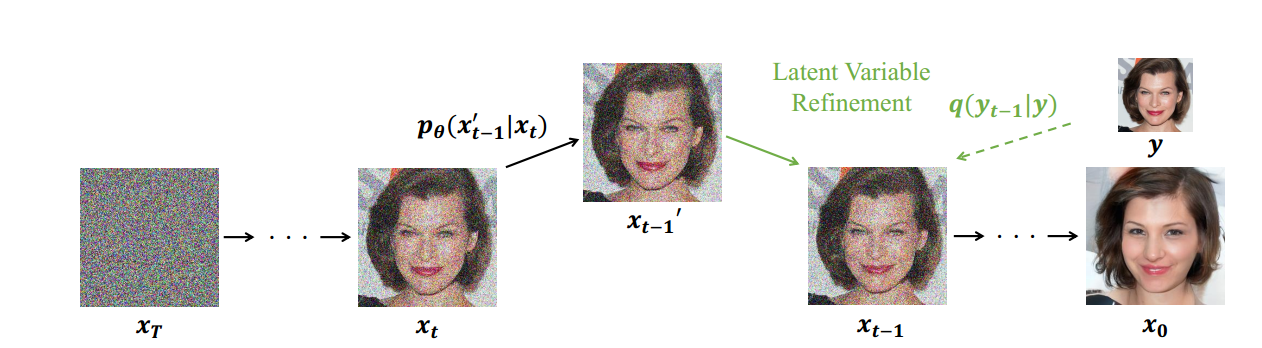
很明显,我们可以通过控制降维再升维的倍数来控制信息的留存比例。也可以通过噪声在后向过程里添加的时间步多寡来调整控制的强弱。通过原论文里的两张图可以看到,随着压缩倍数的增加,其细节信息的缺失会导致最终生成的结果与原图的语义差别加大。同样的趋势可以在后向去噪时施加影响的终止步数上看到。越早终止施加,则语义差别越大。
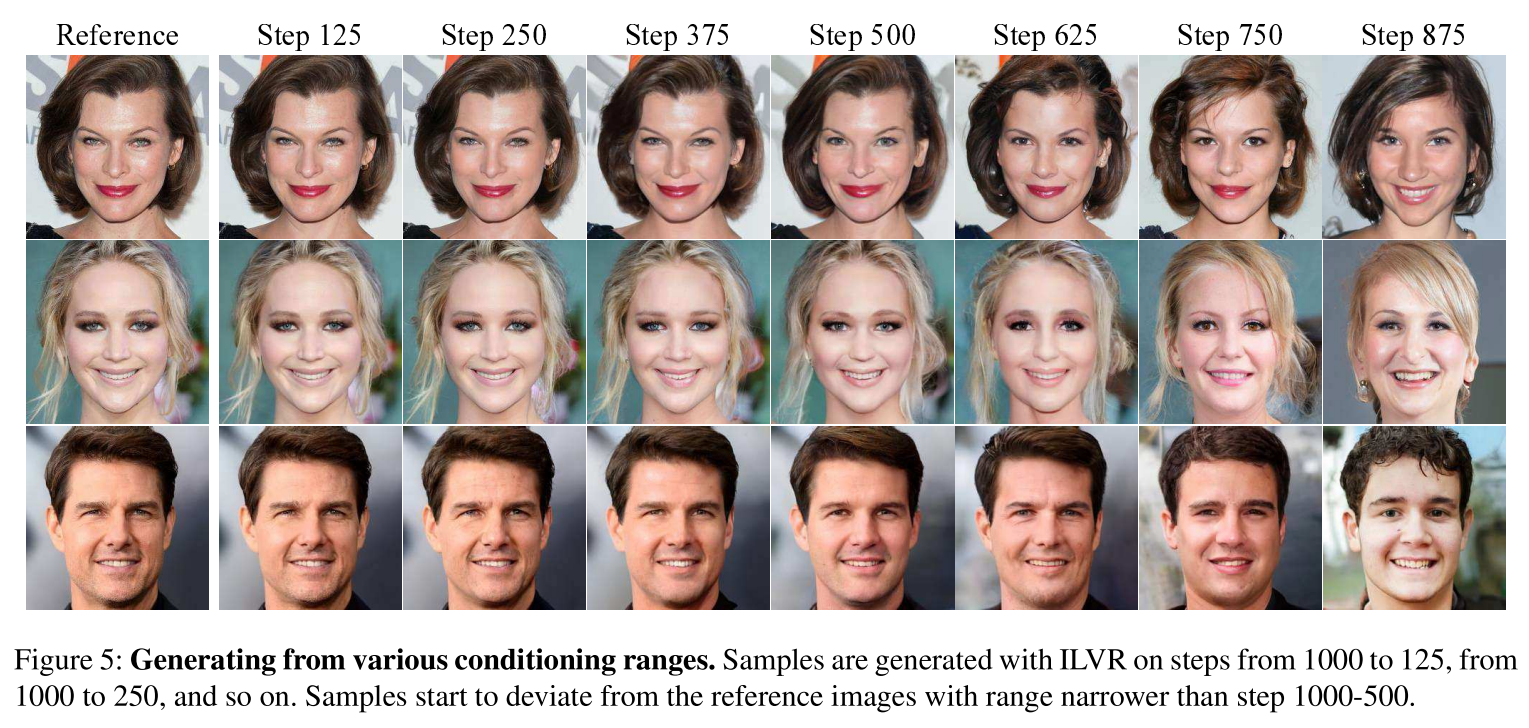

优点
无需额外训练,需要调控的超参不多,并且直观易懂。
缺点
但适用场景也比较局限无法局部调整只能全局修改,并且只能保留原有图像的空间布局,无法做到改变姿势角度等变化,且无法精细化地控制生成的图像的性质。
SDEdit
ICLR 2022
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations | Papers With Code
核心思想
扩散的前向过程实际是个图像语义信息不断被噪声掩盖的过程,并且总是从高频信息开始到低频信息。IVLR里实际用了低通滤波和下上采样来抽取出低频信息来影响后向去噪过程。
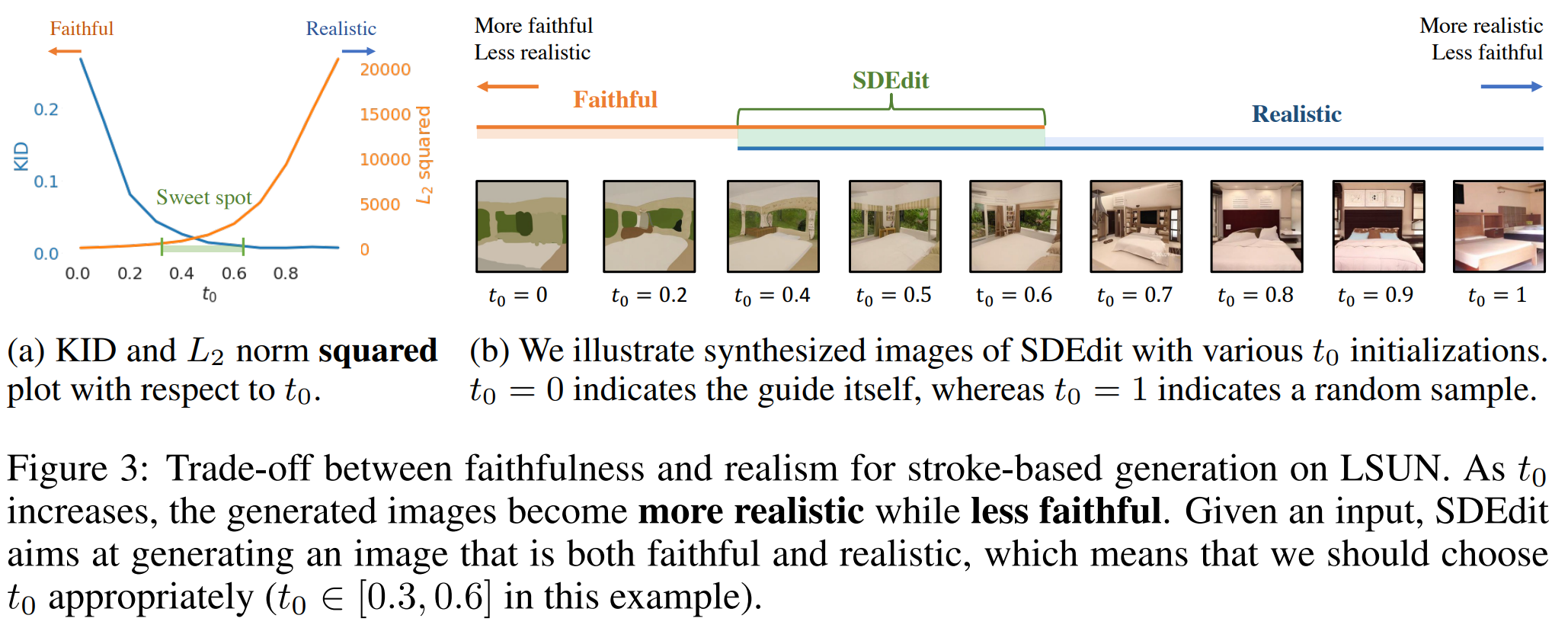
那么我们是否可以直接省略这一步直接让前向过程不要加噪到纯噪声,而是加噪到中间过程使其保留一些低频信息
下图直观地体现了这个过程,其中t0就是前向加噪的比例。通过调控信息保留的多少,我们也同样调控了生成与原图之间的相似程度。
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
CVPR 2022
RePaint: Inpainting using Denoising Diffusion Probabilistic Models | Papers With Code
这篇工作略晚于以上两篇工作,核心思想也非常接近,但略有不同的是针对其只能全局修改的痛点增添了对图像的MASK操作,将任务转变为了图像补全任务,使得局部修改成为可能。
具体来说,
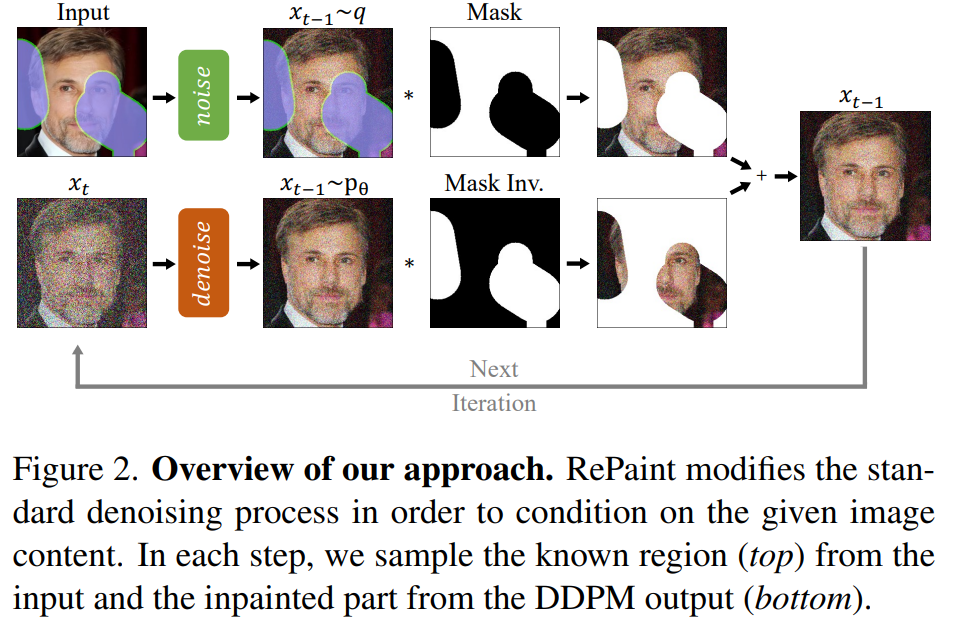
- 在前向扩散时,依然记录每一步的噪声图像。
- 在后向去噪时,我们将未被掩码的区域从前向的记录里抽取出来,而被掩码的区域则由噪声填充,拼合成一张完整的图后我们开始迭代去噪。
- 之后每一步都更新未掩码区域为前向的记录部分,而掩码区域更新为后向去噪的结果。做法如下图所示

但是这个简单的做法会有一个很大的弊端就是掩码的区域里所有的信息实质上是被全部丢弃的,重新生成的结果往往在局部语义上是自洽的但是没有考虑到全局语义。比如以下这个例子,对比最左边的原图与我们朴素的做法产生的结果我们可以看到,尽管掩码部分重新生成的结果与周围的材质和颜色接近,但在全局语义上这张图明显是不自洽的。

我们在后向去噪时,考虑的拼合图像里包含了原图前向扩散的静态输出,即使我们在后向去噪时不断地试图生成语义一致的内容,但图像里的未掩码区域都会在下一步被替换成没有考虑后向生成过程的前向扩散输出。导致了语义的不一致性。此外随着去噪过程的逐渐深入,我们的方差也在逐渐减小( setp),使得更正语义变得更为困难。
换句话说,模型需要更多的步骤来更正语义的不一致性。而作者具体的做法则是结合了以上两点洞见。
- 首先我们在每一步去噪的时候,我们重新将去噪后的拼合结果加一次噪声至 再重复同样的后向去噪步骤。
- 将以上这个过程重复次,我们就得到了上图里语义一致的输出结果。
- 这个做法分别对应了未掩码区域没有考虑后向生成结果的问题和需要更多步骤生成的问题。
限于其框架依然是基于迭代去噪过程的无条件生成的DDPM模型(即不条件于文本图像或类别等信息的生成),其对掩码区域所能做的调控依然非常有限,只能借助于随机性重新生成。
基于显式分类器的图像引导生成
扩散模型的优化目标本质上是在数据空间拟合一个前往目标数据分布的最优梯度方向 。那么很自然地,如果我们想要做引导生成,我们可以用贝叶斯定理将基于条件生成的梯度拆解成一个基于显式分类器的梯度和一个常规的无条件生成的梯度。
换句话来说,我们依然可以使用之前DDPM的方式继续训练一个无条件生成模型,我们现在只需要额外训练一个新的基于噪声输入的分类器就可以了。

Diffusion Models Beat GANs on Image Synthesis
The score function learned under Classifier Guidance can then be summarized as:
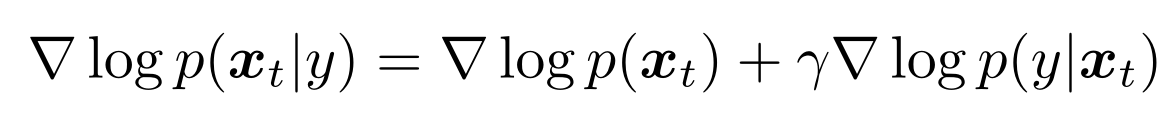
基于CLIP模型的多模态图像引导生成
More Control for Free! Image Synthesis with Semantic Diffusion Guidance
More Control for Free! Image Synthesis with Semantic Diffusion Guidance | Papers With Code
**扩大化了P(y|x)的定义。实际上我们完全可以把分类引导的定义拓展为文字,图像或者多模态的引导。**具体来说,我们可以将分类器重新写成方程 。
有了以上的定义,现在我们可以借助CLIP模型里文本和图像之间对齐的表征来做一些损失计算了。具体来说,想要使用一个文本来引导图像生成,我们可以每一步都计算现在的图像表征和文本表征的距离,使用方程的梯度来计算缩小这个距离的方向。最简单的方式莫过于余弦距离
Blended Diffusion for Text-driven Editing of Natural Images
CVPR 2022
Blended Diffusion for Text-driven Editing of Natural Images | Papers With Code
同样是在DDPM生成的时候做额外的梯度引导,只是额外添加了MASK的操作,使得文本引导可以只针对具体的某个区域更改。
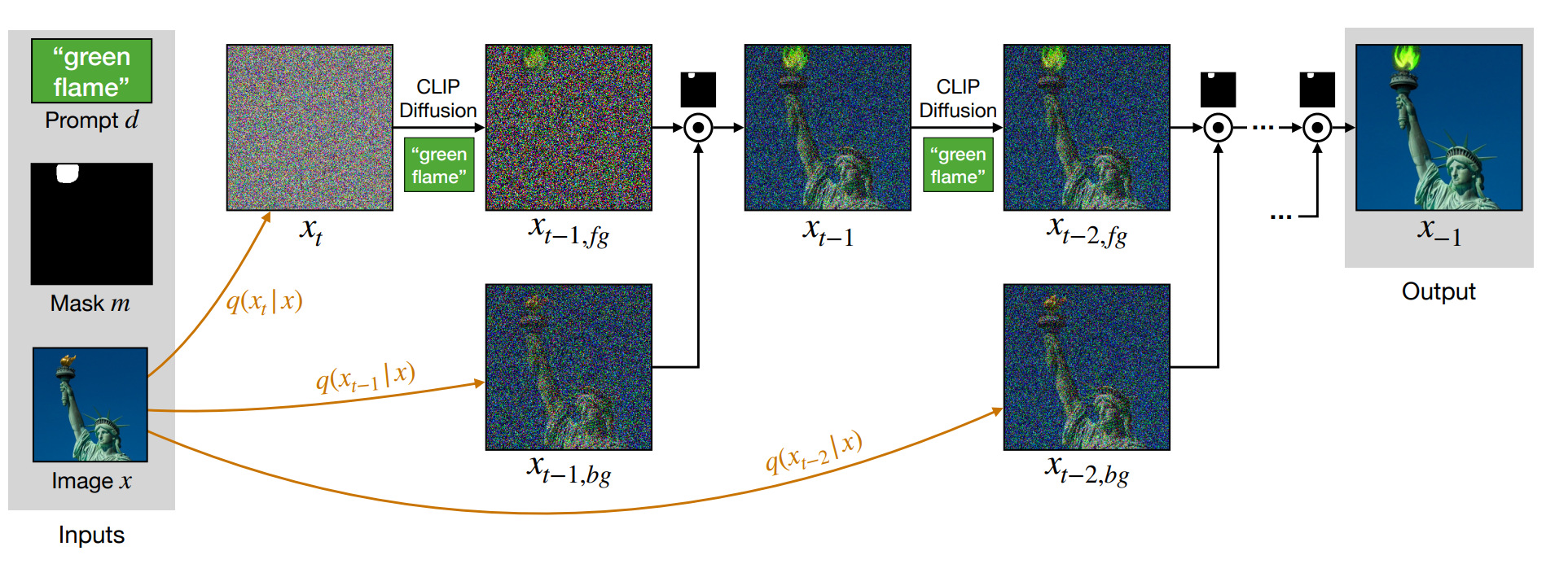
Text-driven blended diffusion. Given input image x, input mask m, and a text prompt d, we leverage the diffusion process to edit the image locally and coherently. We denote with ⊙ the element-wise blending of two images using the input mask m.
基于隐式分类器的文生图大模型
Classifier-Free Diffusion Guidance
将前面的 classifier diffusion guidance 带入
即我们可以用贝叶斯将显式分类器的梯度引导再拆解为两项其中一个是无条件生成的梯度预估模型(例如常规的DDPM),另一个是基于条件生成的梯度预估模型(条件生成可以建模为UNet+cross-attention)。而我们甚至可以使用同一个模型同时表示两者,区别只在于生成时是否将条件向量置为零即可。