
Deblurring-via-Stochastic-Refinement
(cvpr 2022')Deblurring via Stochastic Refinement
Deblurring via Stochastic Refinement | Papers With Code
未开源
related work
- cvpr 18‘ the preception-distortion tradeoff
- pd 曲线
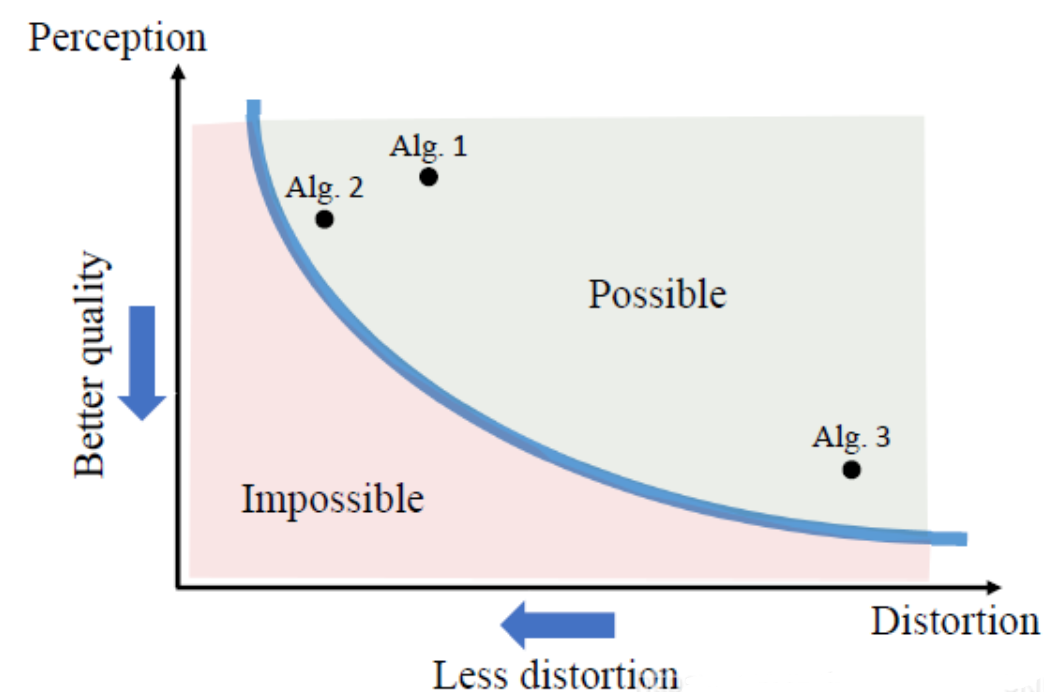
论文阅读笔记之——《The Perception-Distortion Tradeoff》_gwpscut的博客-CSDN博客
method
- predict & refine,扩散模型的 x0 不再是原图,而是原图和 predictor 的残差
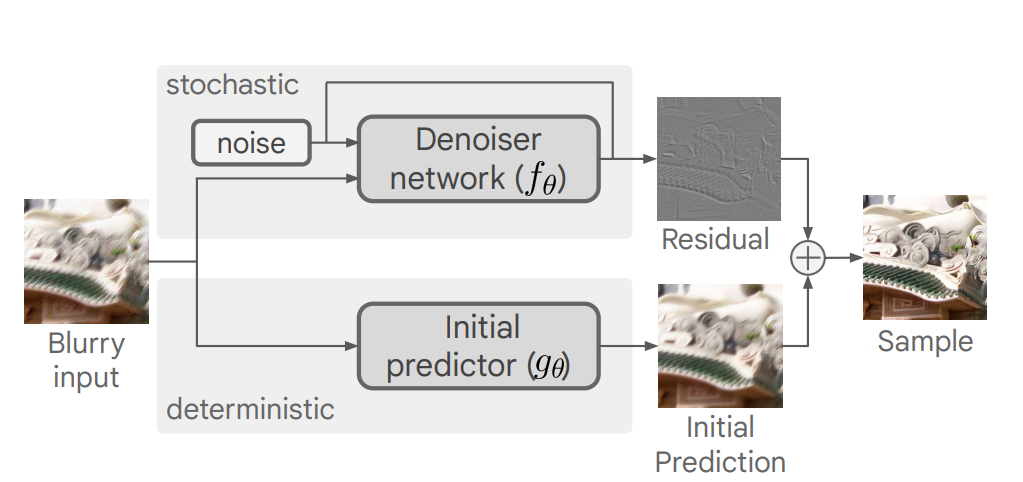
- sample averaging:由于每一次采样的随机性,可以多重建几次,取平均
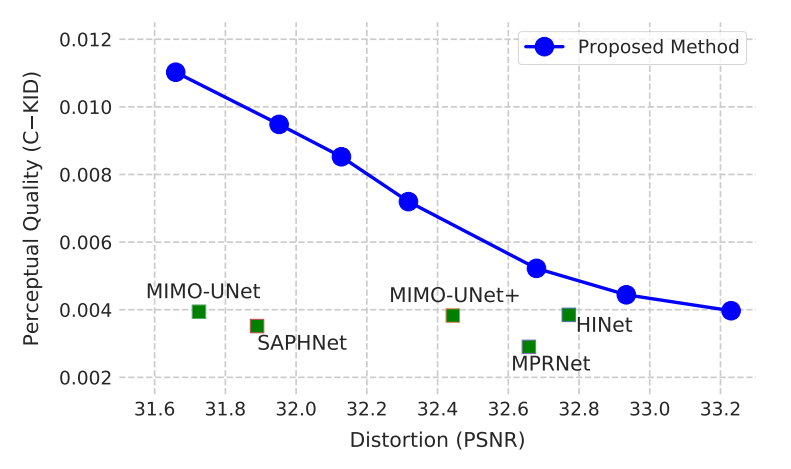
- 采样步数越多,主观质量越好,反之客观质量越好
- 训练的时候用小patch,测试的时候用整张图————low level task
网络架构
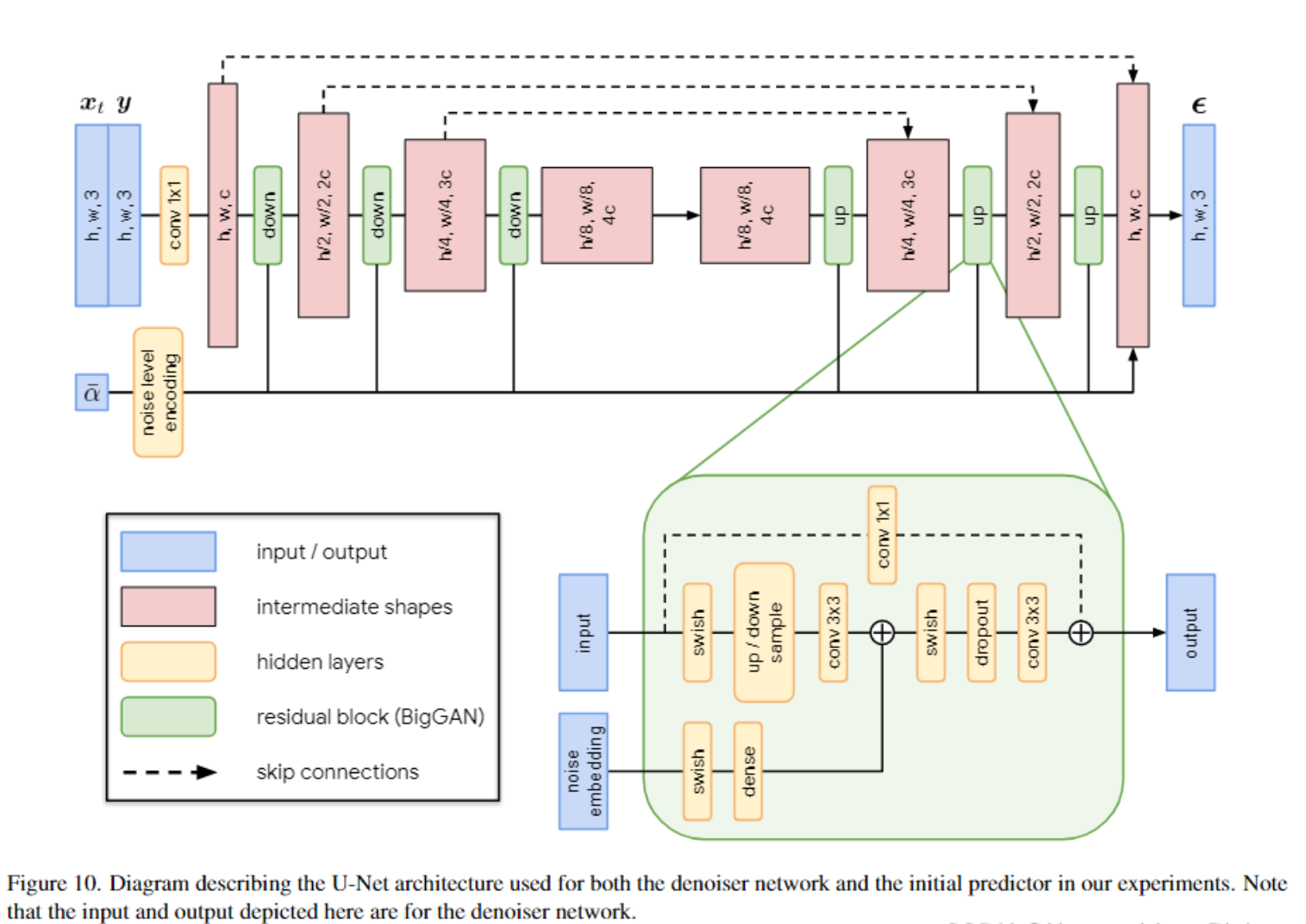
- 未开源
- initial predictor 和 denoiser 是一样的,base channel 前者64,后者32
- 参数量前者 26m,后者7m
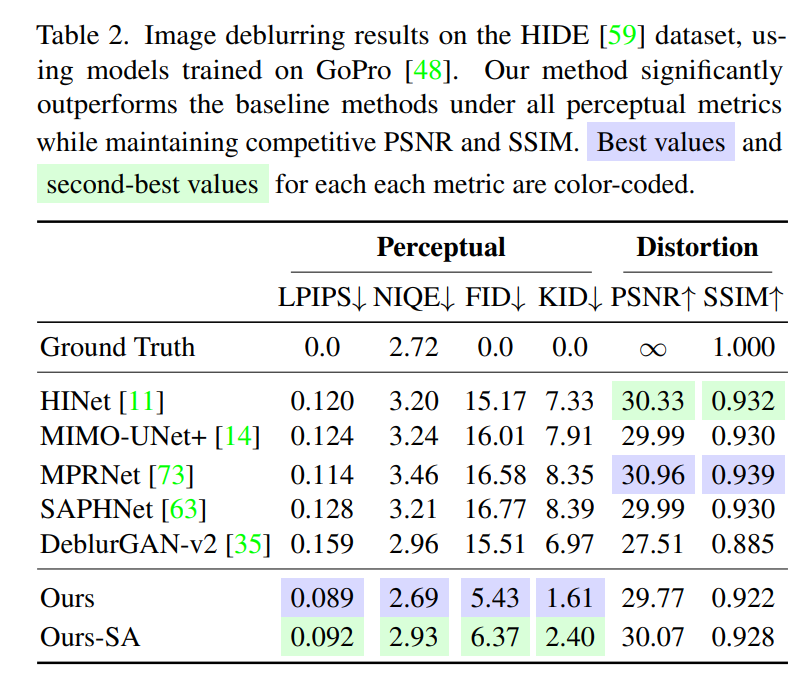
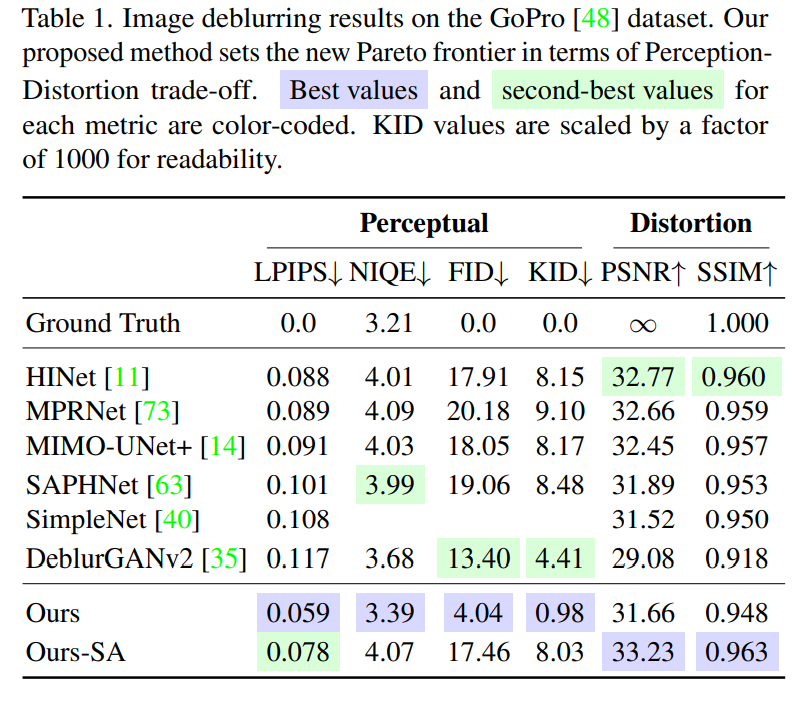
result

Low-level任务:常见的包括 Super-Resolution,denoise, deblur, dehze, low-light enhancement, deartifacts等。简单来说,是把特定降质下的图片还原成好看的图像,现在基本上用end-to-end的模型来学习这类 ill-posed问题的求解过程,客观指标主要是PSNR,SSIM,大家指标都刷的很高。目前面临以下几点问题:
- 泛化性差,换个数据集,同种任务变现就很差
- 客观指标与主观感受存在,GAP,指标刷很高,人眼观感不佳,用GAN可缓解 落地的问题,SOTA模型运算量很(上百G Flops),但实际不可能这么用
- 主要是为人眼服务,缺乏与High-level之间的联系
High-level任务:分类,检测,分割等。一般公开训练数据都是高品质的图像,当送入降质图像时,性能会有下降,即使网络已经经过大量的数据增强(形状,亮度,色度等变换)
真实应用场景是不可能像训练集那样完美的,采集图像的过程中会面临各种降质问题,需要两者来结合。简单来说,结合的方式分为以下几种
- 直接在降质图像上fine-tuning
- 先经过low-level的增强网络,再送入High-level的模型,两者分开训练
- 将增强网络和高层模型(如分类)联合训练 ———————————————— 版权声明:本文为CSDN博主「WTHunt」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_20880415/article/details/117225213