
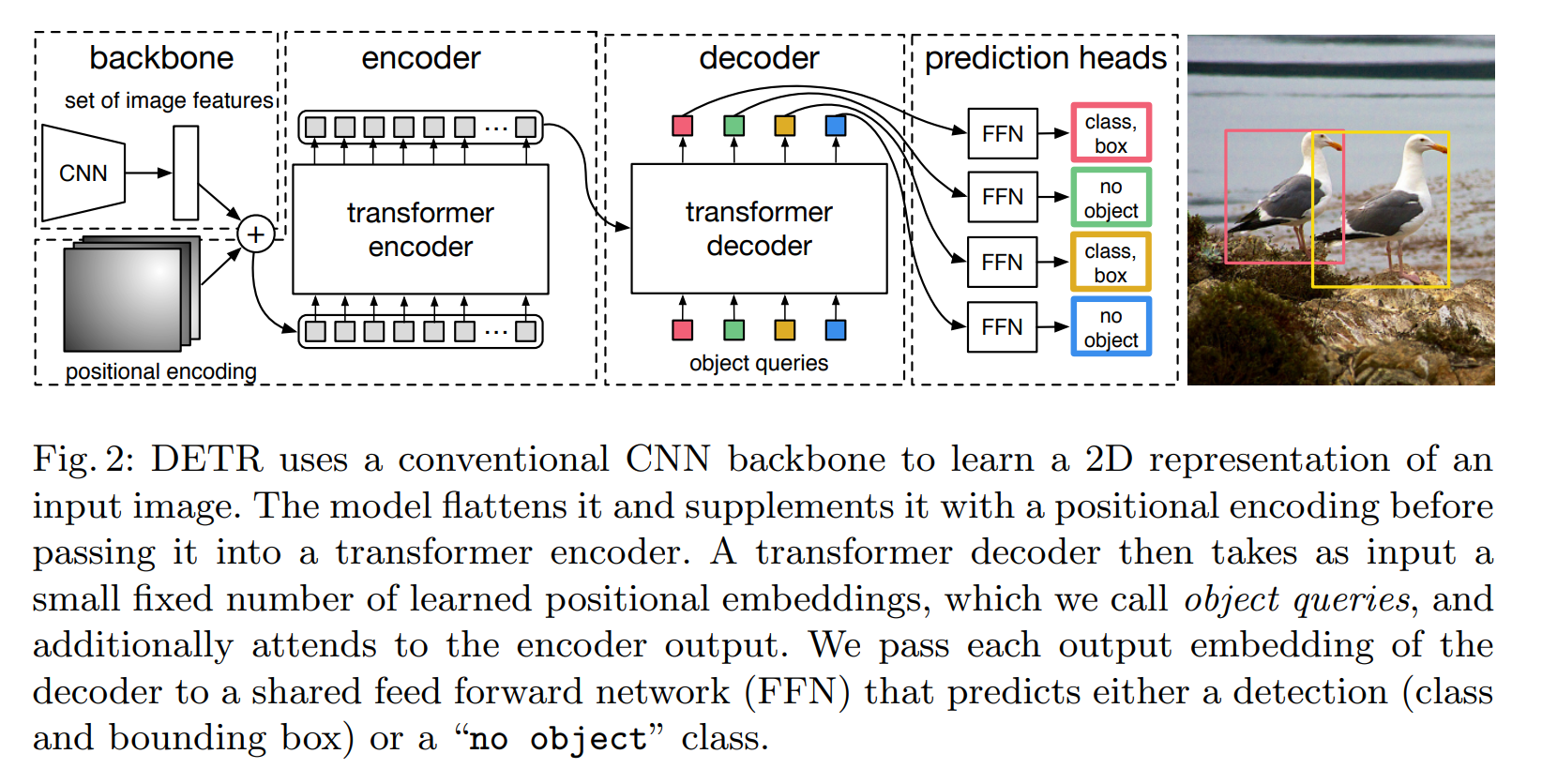
DETR
Anchor-based方法本质上是对预定义的密集anchors进行类别的分类和边框系数的回归。
DETR则是将目标检测视为一个集合预测问题(集合和anchors的作用类似)。
由于Transformer本质上是一个序列转换的作用,因此,可以将DETR视为一个从图像序列到一个集合序列的转换过程。
该集合实际上就是一个可学习的位置编码(文章中也称为object queries或者output positional encoding,代码中叫作query_embed)。
import torch
from torch import nn
from torchvision.models import resnet50, ResNet50_Weights
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads, num_encoder_layers, num_decoder_layers):
super().__init__()
# Backbone: ResNet-50 without the last two layers
self.backbone = nn.Sequential(*list(resnet50(weights=ResNet50_Weights.DEFAULT).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
# Transformer
self.transformer = nn.Transformer(d_model=hidden_dim, nhead=nheads,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers)
# Output layers
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
# Positional encoding and query embeddings
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim)) # 100 queries
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs) # Backbone output: (B, C, H, W)
h = self.conv(x) # Project to hidden_dim: (B, hidden_dim, H, W)
# Generate 2D positional encoding
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1) # (H*W, 1, hidden_dim)
# Flatten spatial dimensions and transpose for Transformer input
h = h.flatten(2).permute(2, 0, 1) # (H*W, B, hidden_dim)
h = h + pos # Add positional encoding
# Transformer expects tgt to be (sequence_length, batch_size, hidden_dim)
query_pos = self.query_pos.unsqueeze(1).repeat(1, inputs.shape[0], 1) # (100, B, hidden_dim)
h = self.transformer(tgt=query_pos, memory=h) # (100, B, hidden_dim)
# Output predictions
logits = self.linear_class(h) # (100, B, num_classes + 1)
bboxes = self.linear_bbox(h).sigmoid() # (100, B, 4)
return logits, bboxes
# Example usage
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
print(logits.shape, bboxes.shape) # Expected: (100, 1, 92) and (100, 1, 4)损失函数
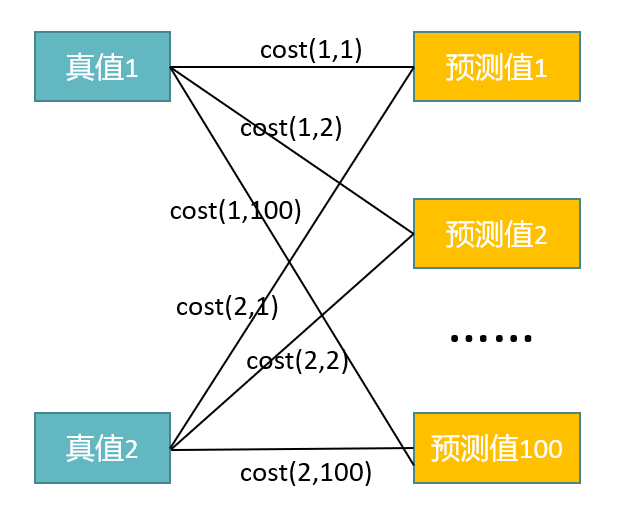
将object predictions和ground truth box之间通过匈牙利算法进行二分匹配:
- 假如有K个目标,那么100个object predictions中就会有K个能够匹配到这K个ground truth,其他的都会和“no object”匹配成功,使其在理论上每个object query都有唯一匹配的目标,不会存在重叠,所以DETR不需要nms进行后处理。
分类loss采用的是交叉熵损失,针对所有predictions;bbox loss采用了L1 loss和giou loss,针对匹配成功的predictions
匈牙利算法:
匈牙利算法是用于解决二分图匹配的问题,即将Ground Truth的K个bbox和预测出的100个bbox作为二分图的两个集合,匈牙利算法的目标就是找到最大匹配,即在二分图中最多能找到多少条没有公共端点的边。匈牙利算法的输入就是每条边的cost 矩阵
Deformable DETR
DETR问题:
- 收敛慢:训练起来非常慢,至少要训练500个epoch,比faster rcnn慢十几倍(注意力模块初始化比较稀疏,需要很长时间去学习,收敛比较慢);
- 计算量大:对小目标性能很不好,因为detr是没法使用高分辨率的图片的,计算量太大了(计算量和整个图像像素点个数呈平方关系,计算量很大),而且没有使用多尺度特征;
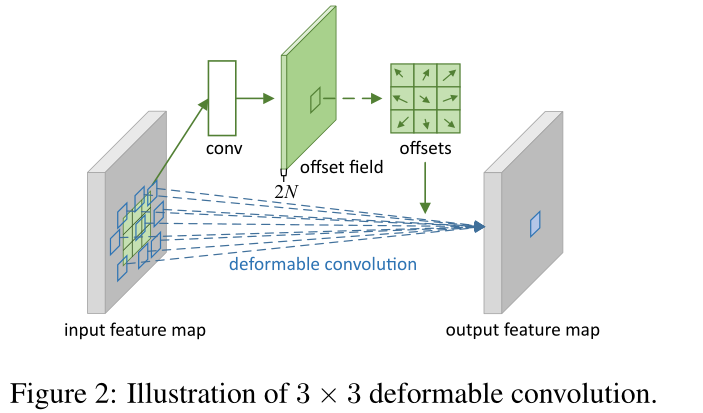
在deformable detr中,feature只与少部分其他features做相似性计算,然后对特征进行加权融合。
DCN

DETR 3D
https://github.com/WangYueFt/detr3d
https://arxiv.org/pdf/2110.06922
https://paperswithcode.com/paper/detr3d-3d-object-detection-from-multi-view
首个将 Transformer 引入 3D 目标检测的工作
多视角3D目标检测问题:
多视图特征融合:
后处理复杂:
创新点:
使用 Transformer 直接预测 3D 边界框,实现真正的端到端检测。
Overview
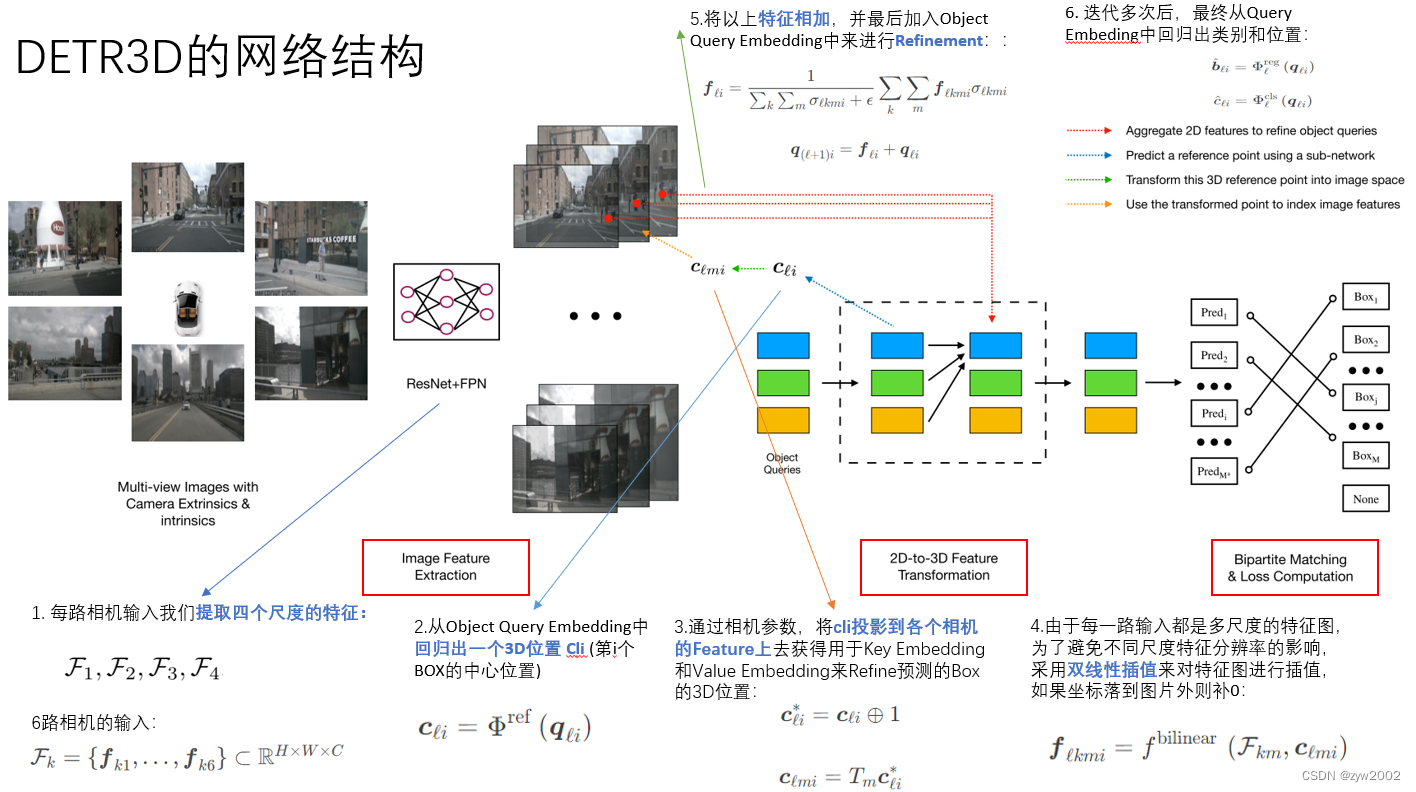
结构
Model
使用ResNet作为Backbone从相机图像中提取特征。
- ResNet 第 3 和 第 4 个 stage 使用 可变形卷机 DCN。
- 输出四个特征图:1/8,1/16,1/32和1/64
构建FPN
DETR3D detection head由6个layers。
- 每层由一个 feature refinement step 和 multi-head attention 组成。
- 最后两个子网络前去预测每个query的bounding box parameters和class label
- 每个子网络是hidden dimension为256的全连接层。
检测头
它使用了L层网络从2D feature map中去预测bounding box。每一层的步骤如下:
- 预测一组和object query相关的bounding box centers。类似于蓝色线条中的预测3D参考点。
- 利用相机投影矩阵将这些centers投影到所有的feature map中。绿色线条 。
- 利用双线性插值(bilinear interpolation)对feature进行采样,并将其整合到object query中。黄色线条。
- 用多头注意力描述object之间的相互作用(interaction)。(红色线条)。
特征整合到目标查询
对于每个目标查询,从所有摄像头的多尺度特征图中采样得到的特征 需要被整合到目标查询中。具体来说,这些特征通过加权求和的方式合并:
其中 是一个二进制掩码,用于过滤那些投影到图像外的无效点(即 超出图像边界的点,给定的参考点不一定在所有的摄像机图像中都可见)。$ \epsilon$ 是一个小常数,用于避免除以零。
是在 层 第 k 个级别第 m 个相机中的第 i 个点。
最后,将采样得到的特征添加到目标查询 中,得到更新后的目标查询:
然后使用多头注意力通过引入目标之间的交互来细化目标查询。(Deformable transformer)
transformerlayers=dict(
type='mmdet.DetrTransformerDecoderLayer',
attn_cfgs=[
dict(
type='MultiheadAttention', # mmcv.
embed_dims=256,
num_heads=8,
dropout=0.1),
dict(
type='Detr3DCrossAtten',
pc_range=point_cloud_range,
num_points=1, # 超参,采样点的数量
embed_dims=256)
],目标查询:
query 分为了
- 内容嵌入(Content Embedding):描述查询的特征(可学习的向量)。
- 位置嵌入(Position Embedding):描述查询在3D空间中的位置(可学习的3D坐标)。
class Detr3DTransformer(BaseModule):
……
def forward(self, mlvl_feats, query_embed, reg_branches=None, **kwargs):
query_pos, query = torch.split(query_embed, self.embed_dims, dim=1)
query_pos = query_pos.unsqueeze(0).expand(bs, -1, -1) # [bs,num_q,c]
query = query.unsqueeze(0).expand(bs, -1, -1) # [bs,num_q,c]
……
query = query.permute(1, 0, 2)
query_pos = query_pos.permute(1, 0, 2)
inter_states, inter_references = self.decoder(
query=query,
key=None,
value=mlvl_feats,
query_pos=query_pos,
reference_points=reference_points,
reg_branches=reg_branches,
**kwargs)损失函数
思想与 DETR 相同,让模型自己学习最优匹配,匹配上的为正样本
# 使用匈牙利算法匹配预测与真实框
cost_matrix = self.compute_cost(pred_boxes, gt_boxes)
indices = hungarian_match(cost_matrix) # 最优匹配索引
# 计算匹配后的损失
loss = 0
for idx in indices:
loss += bbox_loss(pred_boxes[idx], gt_boxes[idx])
loss += cls_loss(pred_cls[idx], gt_label[idx])损失函数组成:
- 分类损失(Focal Loss)
- 3D框回归损失(L1 + GIoU)
- 方向分类损失(CrossEntropy