PETR 系列
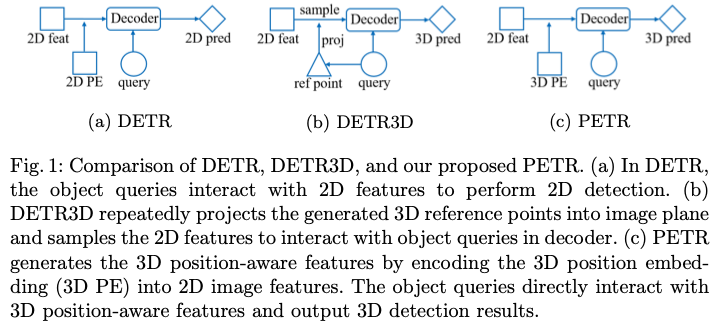
DETR:每个物体query表示一个物体,并在transformer解码器中与2D特征进行交互以生成预测;
DETR3D:物体query预测的3D参考点通过相机参数投影回图像空间,并用于从所有相机视图中采样2D特征,解码器将采样的特征和query作为输入,更新物体query的表示(说到底仍旧是在2D特征中进行交互)
重要
问题:
- 参考点的预测坐标可能不够准确,导致采样的特征超出物体区域。
- 只会收集投影点处的图像特征,这无法从全局视角进行表示学习.
- 复杂的特征采样过程会阻碍检测器的实际应用,DETR 3D 稀疏的query 限制了直接使用密集BEV 特征
作者的目标是将多视角的2D特征转换为3D感知特征,可以直接在3D环境下更新物体查询。
PETR
2022 ECCV
https://blog.csdn.net/qq_55794606/article/details/141818806
https://github.com/megvii-research/PETR?tab=readme-ov-file
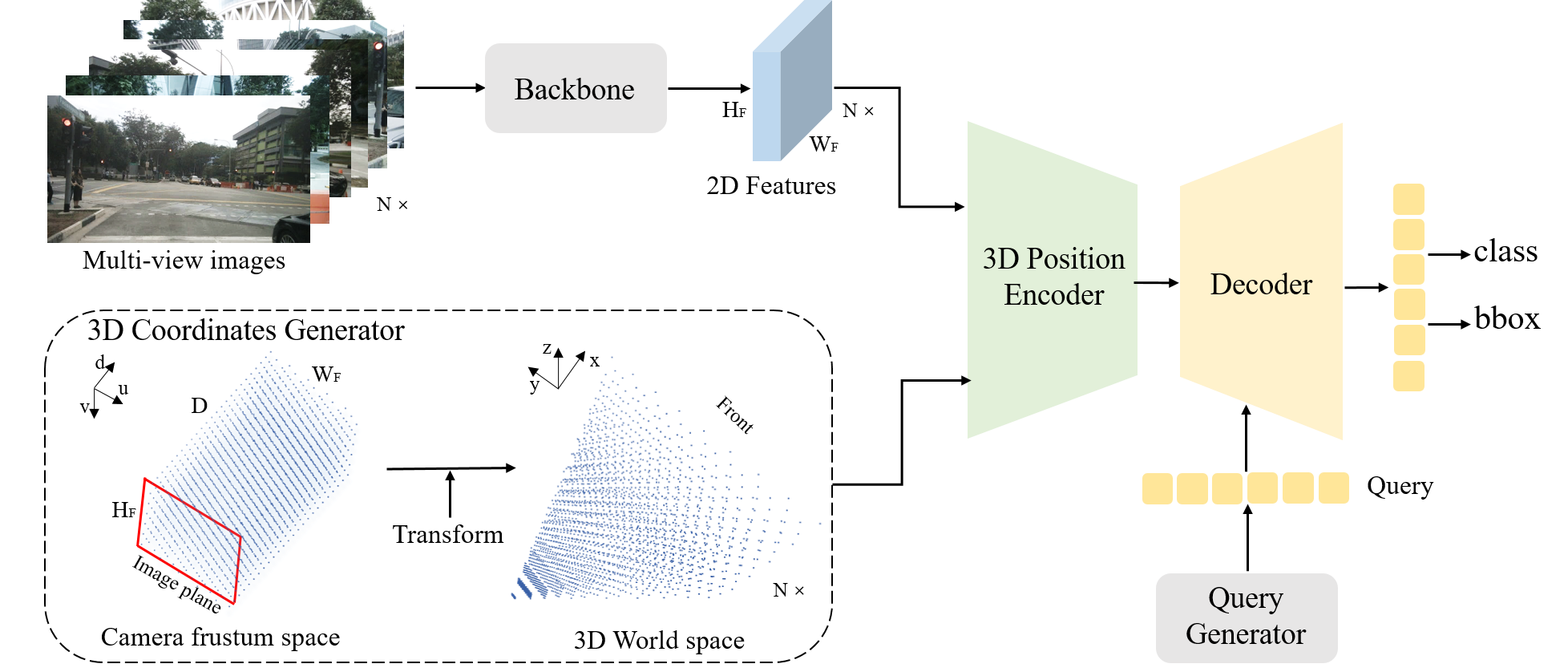
为了实现这一目标,
- 首先将由不同视角共享的相机视锥空间离散化为网格坐标。
- 然后,通过不同的相机参数将这些坐标转换为 3D 世界空间的坐标。
- 接着,通过主干网络中提取出来的2D 图像特征,与 3D 坐标一起,输入到一个简单的 3D 位置编码器中,以生成 3D 位置感知特征。
- 3D 位置感知特征将在 transformer 解码器中与物体查询进行交互,更新后的物体查询将进一步用于预测物体类别和 3D 边界框。
与 DETR3D 相比,提出的 PETR 架构带来了许多优势。
- 它保持了原始 DETR [4] 的端到端特性,同时避免了复杂的 2D 到 3D 投影和特征采样。
- 在推理时,3D 位置坐标可以以离线方式生成,并作为额外的输入位置嵌入。这使得实际应用相对更简单。
模型
3D Position Encoder
位置编码
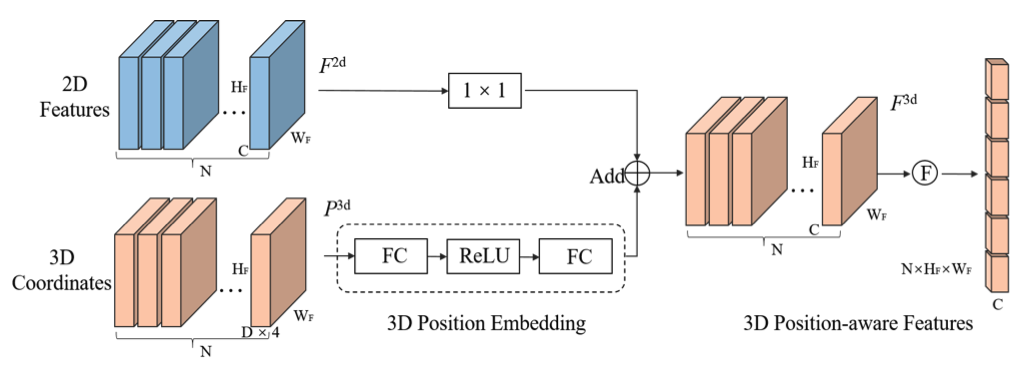
- 多视角2D图像特征输入到一个1×1卷积层中以降低维度。
- 由3D坐标生成器产生的3D坐标通过一个多层感知机(MLP)网络转换为3D位置嵌入(PE)。
- 然后,将3D位置嵌入与同一视角的2D图像特征相加,生成3D位置感知特征。
- 最后,将3D位置感知特征展平,作为Transformer解码器的关键输入部分。 表示展平操作。
Decoder
transformer decoder
略
Query
初始化生成:
两层 MLP
数量:
根据消融实验,与固定采样的方式相比,与 DETR 类似可学习的 query 效果更好,且 query 越多模型效果越好,但是消耗上升,取平衡 1500 个 query。
优化:
L 层解码器
实验
All experiments are trained for 24 epochs (2x schedule) on 8 Tesla V100 GPUs with a batch size of 8. No test timeaugmentation methods are used during inference.
PETRv2
2022
ECCV 2023
PETRv2是将PETR扩展到时序模型以及BEV语义分割上。
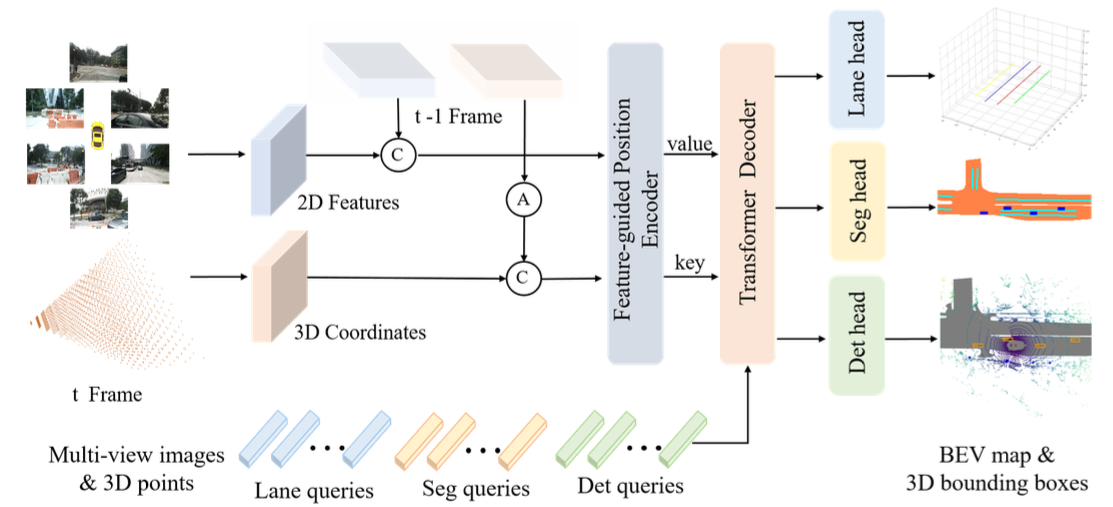
本文提出的PETRv2框架示意图。
- 从多视角图像中提取2D特征,并按照 PETR 的方式生成 3D 坐标。
- 为了实现时间对齐,前一帧t-1的3D坐标首先通过姿态变换(pose transformation)转换到当前帧 t 的坐标系中。
- 然后,两帧的2D特征和3D坐标分别被拼接在一起,并输入到特征引导的位置编码器(Feature-guided Position Encoder, FPE)中,以生成用于Transformer解码器的键(key)和值(value)组件。
- 检测查询(det queries)、分割查询(seg queries)和车道查询(lane queries)分别初始化于不同的空间,并与Transformer解码器中的多视角图像特征进行交互。
- 最后,更新后的查询被输入到特定任务的头部(task-specific heads)中,以预测3D边界框、鸟瞰图分割图(BEV segmentation map)和3D车道。 A⃝ 表示从帧t-1到帧t的3D坐标对齐。 C⃝ 表示沿批量轴(batch axis)的拼接操作。
不同点如下:
时域对齐
PETR已经证明了3D PE在3D感知中的有效性
在实践中发现,通过简单地将前一帧的3D坐标与当前帧对齐,PETR在时域条件下工作良好。
考虑到自运动,前一帧t-1的3D坐标首先通过姿态变换将变换为当前帧t的坐标系。
然后,将相邻帧的2D特征和3D坐标分别串联在一起,并输入到特征引导的位置编码器(FPE)。
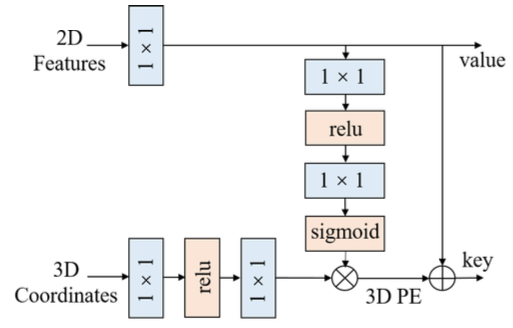
特征引导的位置编码
引入图片特征加入 3D PE 中。
Query
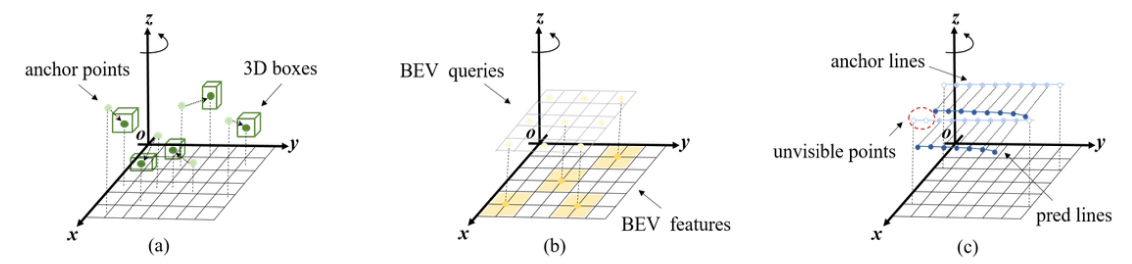
检测查询(det query)定义在整个3D空间中,而分割查询(seg query)初始化在鸟瞰图(BEV)空间下。车道查询(lane query)则以锚点车道的形式定义,每个锚点车道由300个采样点组成。
STEAM PETR
ICCV 2023.
https://github.com/exiawsh/StreamPETR
https://arxiv.org/pdf/2303.11926
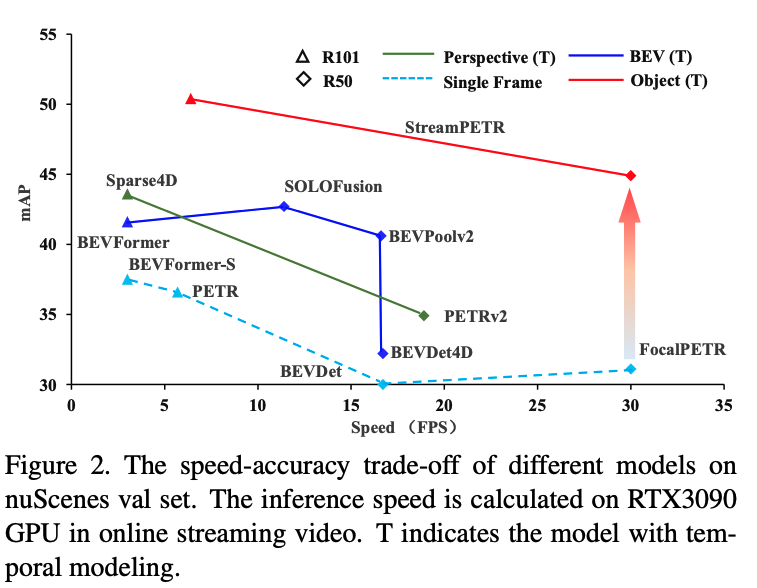
StreamPETR-Large is the first online multi-view method that achieves comparable performance (62.0 mAP, 67.6 NDS and 65.3 AMOTA) with the baseline of lidar-based method.
要解决的问题
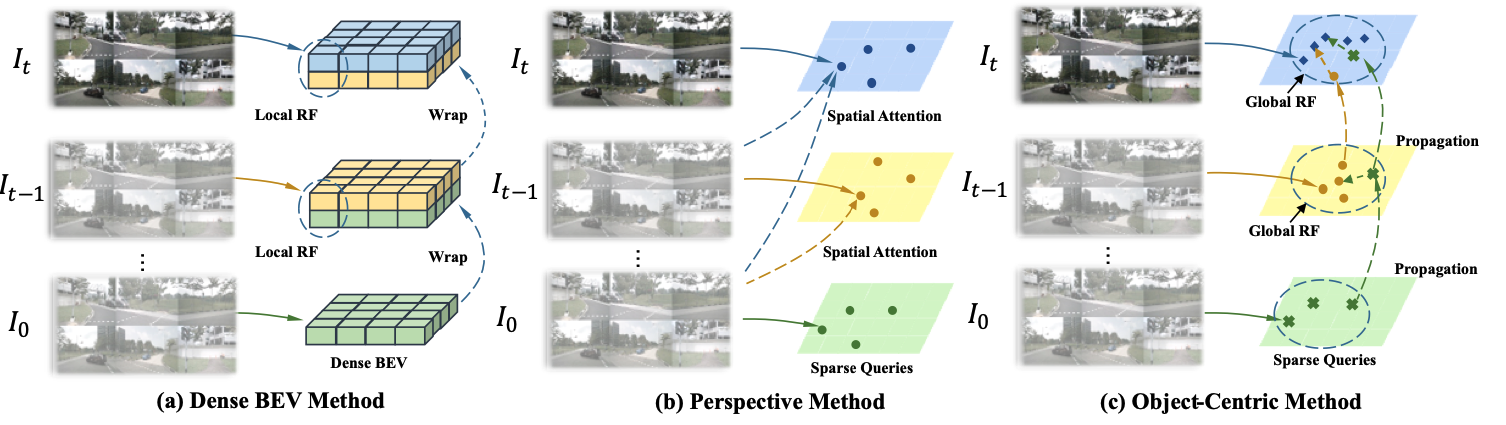
现有的基于时序的BEV方法分为两类(a,b),
其中第一类是在BEV特征上进行时序融合,该类方法是将之前帧的BEV特征通过warp操作来转换到当前帧。但是这种方法如果想对移动的物体建模,就需要很大的感受野;
第二类是基于感知的方法,该类方法可以通过稀疏的query来对移动的物体进行建模,但是由于每次都要查询之前所有的帧,会带来巨大的计算量。
核心贡献:提出了以 query 为中间表示的对移动对象进行时序建模的 bev 模型
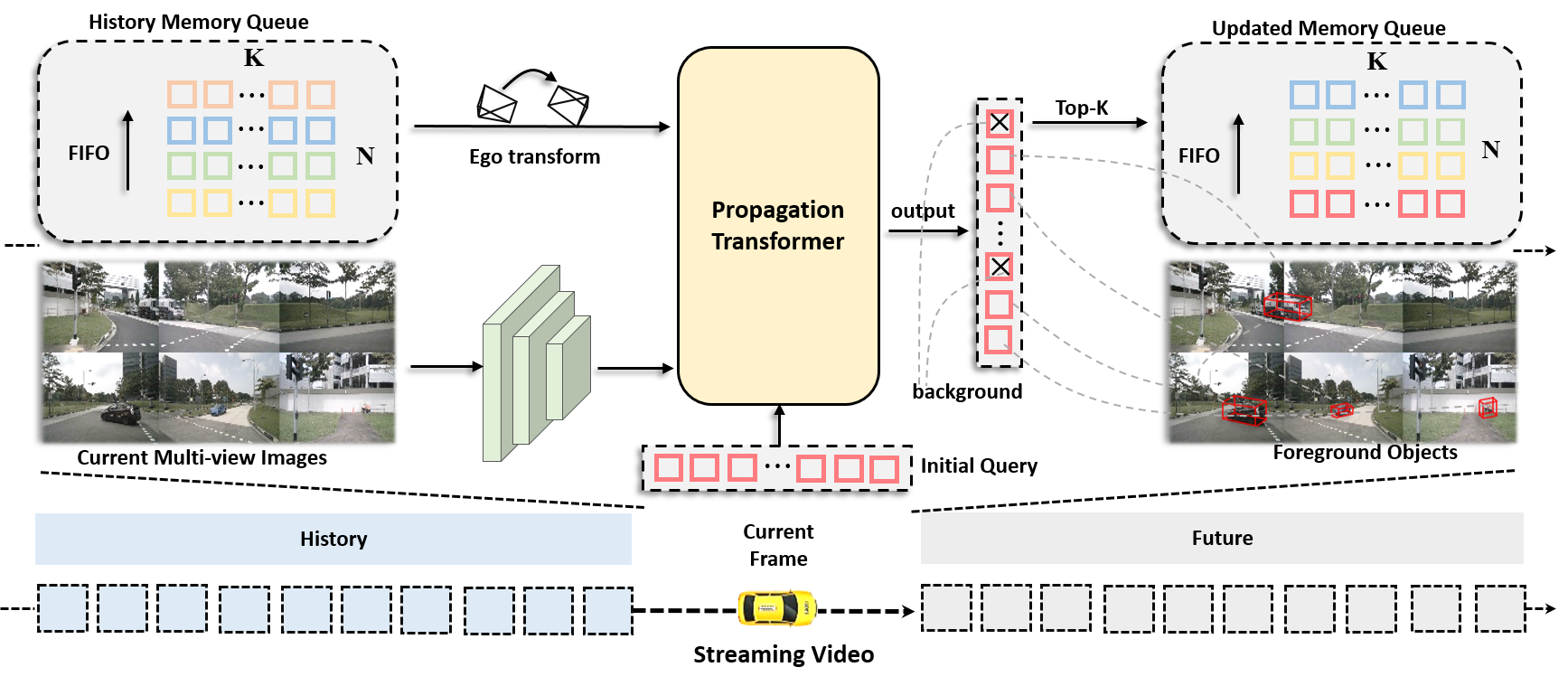
内存队列存储历史对象查询。在Propagation Transformer中,最近的对象查询依次与历史查询和当前图像特征交互,以获得时间和空间信息。
输出查询被进一步用于生成检测结果,并且前K个非背景目标查询被推送到存储器队列中。
通过存储器队列的循环更新,长期时间信息被逐帧传播。
History Memory Queue
Queue的大小是 NxK,N是储存的帧数,K是储存的object的数量。
采用先入先出(FIFO)的更新机制,一般根据分类得分选取TopK个前景目标的信息进行存储。
具体而言,每一个内存空间包含对应object的时间间隔 , 语义embedding ,对象中心点 ,速度 v 和姿态矩阵 E。在实验中我们选取 K=256
Propagation Transformer
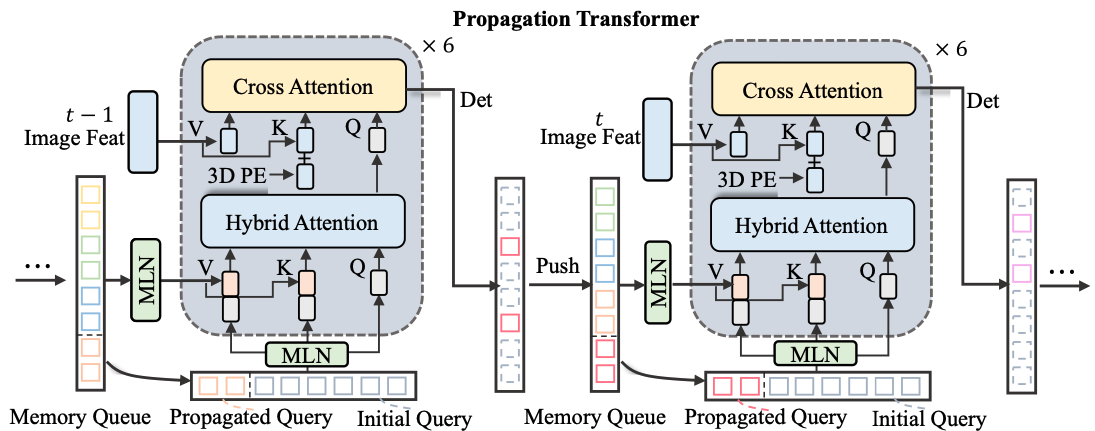
MLN实现了隐式的运动补偿,Hybrid attention则实现RNN式的时序交互。
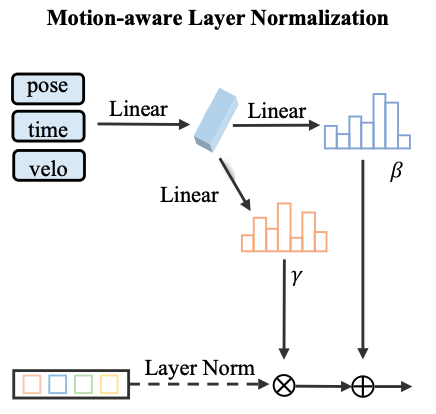
MLN
使用运动信息对 layer norm 后对 query 进行加权
实验
推理:RTX 3090 GPU