
EFFOcc
https://github.com/synsin0/EFFOcc
EFFOcc:从最小标签中学习高效占据网络用于自动驾驶
石一宁¹,²,姜坤¹,²†,苗金玉¹,²,王珂³,钱康安¹,²,王云龙¹,²,李久思¹,²,温拓朴¹,²,杨梦梦¹,²,许一良⁴,杨 Django¹,²†
¹清华大学车辆与运载学院,²智能绿色车辆与运载国家重点实验室,北京,中国,³Kargobot 公司,⁴纵目科技。石一宁在 Kargobot 实习期间完成此工作。†通讯作者:杨 Django,姜坤(ydg@mail.tsinghua.edu.cn,jiangkun@mail.tsinghua.edu.cn)。
摘要
3D 占据预测(3DOcc)是自动驾驶领域中一个快速崛起且具有挑战性的感知任务。现有的 3D 占据网络(OccNets)既计算量大又需要大量标注数据。在模型复杂度方面,OccNets 通常由体素级的重型 Conv3D 模块或 Transformer 组成。此外,OccNets 需要昂贵的大规模密集体素标签进行监督。由过多的网络参数和标注需求导致的模型和数据低效性,严重阻碍了 OccNets 的车载部署。
本文提出了一种高效占据学习框架 EFFOcc,旨在以最小的网络复杂度和标注需求实现最先进的精度。
我们首先提出了一种基于高效融合的 OccNet,仅使用简单的 2D 算子,并在三个大规模基准测试(Occ3D-nuScenes、Occ3D-Waymo 和 OpenOccupancy-nuScenes)上将精度提升至最先进水平。在 Occ3D-nuScenes 基准测试中,以 ResNet-18 作为图像骨干的融合模型参数为 21.35M,平均交并比(mIoU)达到 51.49。
此外,我们提出了一种多阶段占据导向的蒸馏方法,以高效地将知识迁移到仅视觉的 OccNet。在占据基准测试上的广泛实验表明,无论是基于融合还是仅视觉的 OccNets 都达到了最先进的精度。
为展示有限标签下的学习效果,我们使用仅 40% 标注序列和融合 OccNet 的蒸馏训练,实现了 100% 标注视觉 OccNet(mIoU = 30.07)性能的 94.38%(mIoU = 28.38)。代码将在 github 发布。
I 引言
自动驾驶感知需要对环境有全面的理解。常见的以物体为中心的流程(包括检测、跟踪和预测)将障碍物表示为边界框。这些流程难以处理超长或不规则形状的物体。近年来,占据网格在自动驾驶感知中重新兴起 [1]。特斯拉率先将占据网格地图(OGM)扩展到占据网络(OccNet)。特斯拉的基于视觉的占据网络 [2] 使用深度学习技术将视觉特征投影到 3D 体素中,并解码多种信息,如占据、语义和运动流。
尽管基于视觉的占据网络近年来取得了成功,但它们通常需要大量标注数据才能训练到高精度。这一现象促使我们探索一种标注高效的方法来训练高精度的视觉 OccNets。由于占据标注是基于点云分割和物体检测标注的二次标注,我们通常自动标注整个连续场景。因此,我们需要以场景为最小单元进行高效学习。我们希望用最少的场景训练 OccNets 并尽可能达到高精度。我们发现,激光雷达-相机融合占据网络能更好地适应少量标注数据。我们提出从融合教师模型向仅视觉学生模型蒸馏占据知识,同时利用标注和未标注数据。
为此,我们提出了 EFFOcc,一种新颖的占据学习框架,旨在从最小标签中学习高效且高性能的 3D 占据网络。
我们提出了一种计算高效的基于融合的 OccNet,以更少的参数实现了最先进的占据预测性能。我们的动机源于激光雷达点云天然适合几何重建,而轻量级视觉分支足以补充语义识别能力。我们设计了一种轻量级融合网络,并讨论了多种训练技术以实现最先进的性能。
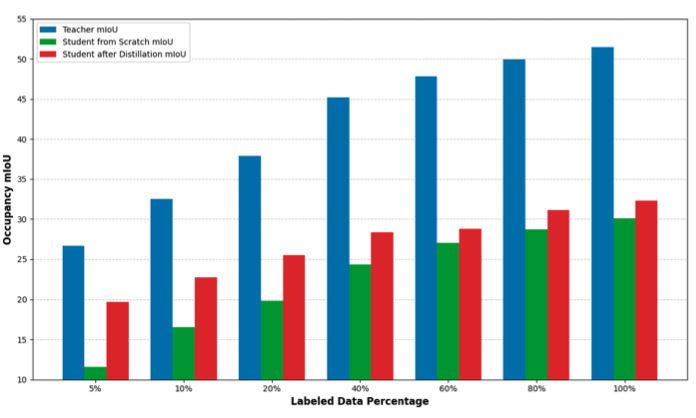
我们从融合教师模型向仅视觉学生模型蒸馏占据知识,仅使用少量标注数据和其他未标注数据。我们相信知识蒸馏有助于提升仅视觉 OccNets 的性能,尤其是在未标注数据上。在知识蒸馏过程中,我们首先将教师模型的占据结果分解为三个子区域:前景、背景和空区域。然后区域掩码同时适用于 BEV 和 3D 区域。我们从教师模型向仅视觉学生模型进行了 BEV 区域和 3D 区域的特征蒸馏。不同数据规模下蒸馏的益处如图 1 所示。
总之,我们的贡献如下:
- 提出了一种标注高效的占据学习框架 EFFOcc,高效训练基于融合和视觉的 OccNets。我们为激光雷达-相机融合的 3D 占据预测提供了一种简单的融合 OccNet,并通过轻量级设计将其提升至最先进水平。
- 提出了一种多阶段占据导向的蒸馏方法,从融合教师模型蒸馏出实时仅视觉占据网络,并以更少的标注数据实现竞争性性能。
- 在 nuScenes 和 Waymo Open Dataset 两个大规模数据集上的三个公开基准测试中验证了模型的有效性。
注
图1:基于融合的教师模型与仅视觉占据网络在不同标注数据规模下从头训练和通过蒸馏训练的性能对比统计图。
II 相关工作
A. 计算高效的占据网络
3D 占据网络(OccNets)用均匀划分的 3D 体素描述世界。OccNets 可以准确重建遮挡下的通用物体,但通常为车载部署带来巨大的计算负载。
为减少 3D 体素计算量,提出了多种方法。
- PanoOcc [3] 用稀疏卷积替换 3D 卷积算子,同时预测非空体素的占据率并删除预测的空体素以保持稀疏性。
- FlashOcc [4] 和 FastOcc [5] 提出了高效的通道到高度方法,避免了复杂的 3D 卷积计算。
- 南京大学(NJU)的 SparseOcc [6] 提出了完全稀疏模型以利用几何稀疏性和稀疏实例查询,通过掩码 Transformer 适应物体稀疏性。
- 上海交通大学(SJTU)的 SparseOcc [7] 在基于几何的视图变换后删除空体素,并使用稀疏卷积算子。此外,提出了一种稀疏潜在扩散器以扩散与占据体素相邻的空体素。他们实现了显著的 74.9% FLOPs 减少。
大多数计算高效的设计针对仅视觉 OccNets,而 EFFOcc 首次探索了高效融合网络,在有限标签下表现良好。
B. 自动驾驶感知中的知识蒸馏
知识蒸馏是一种学习技术,旨在将知识从大型复杂教师模型迁移到小型学生模型。知识蒸馏广泛应用于视觉 BEV 检测学习中,从教师模型(如基于激光雷达或融合的检测器)中学习 [8, 9]。然而,占据任务比检测任务更具挑战性,因为占据预测存在更严重的类别不平衡,不仅是前景物体之间的不平衡,还包括背景元素的不平衡。因此,当前基于视觉的占据网络在前景障碍物上的精度较低。RadOcc [10] 在体素特征上应用神经渲染作为辅助监督。与现有技术相比,EFFOcc 设定了一个半监督知识蒸馏问题:给定有限标签和足够数据,EFFOcc 提出从标注和未标注样本中蒸馏教师模型特征。
III 方法
A. 3D 占据预测的任务形式化
占据预测任务形式化为构建具有固定感知范围和分辨率的语义 3D 占据网格。传感器信息来自环视摄像头和 360 度激光雷达。每个体素网格由语义类别表示。
B. 架构
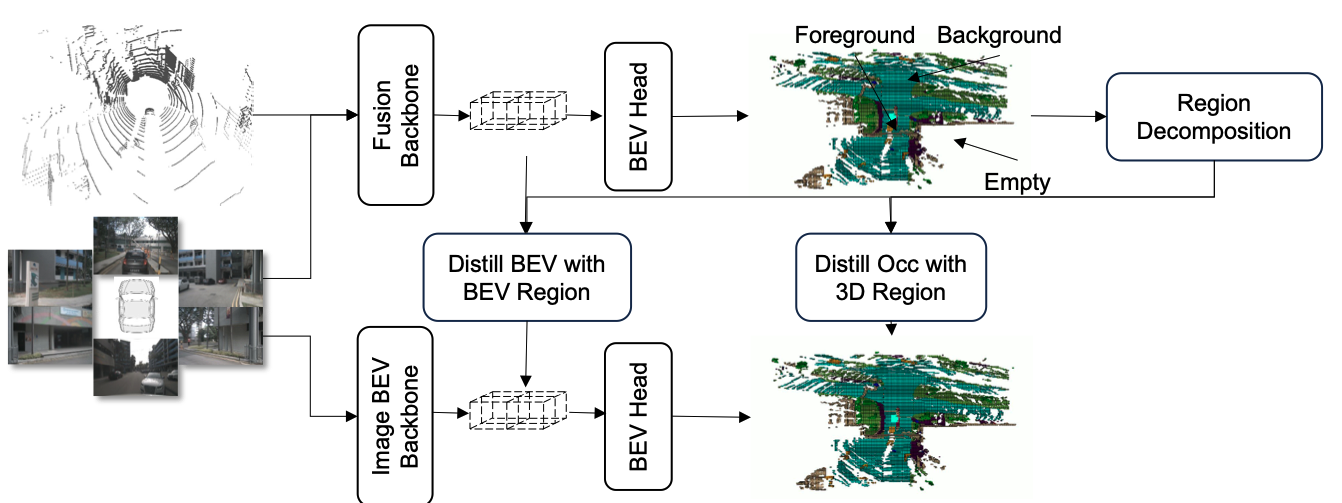
EFFOcc 的框架如图 2 所示。总体目标是从模型中心角度追求网络最小化和训练成本最低化。第 III-C 节介绍了仅使用 2D 算子的轻量级融合网络设计。第 III-D 节使用融合 OccNet 作为教师模型,并将教师模型的占据结果作为感兴趣区域。提出的区域分解蒸馏通过不同比例的标注数据提升了仅视觉 OccNet 的性能。
注
图2:EFFOcc框架示意图。激光雷达点云和多视角图像通过融合网络生成基于融合的占据预测(教师模型)。学生模型接收多视角图像输入,并在BEV(鸟瞰图)和3D占据特征空间上从教师模型蒸馏多阶段特征。
C. 高效融合网络
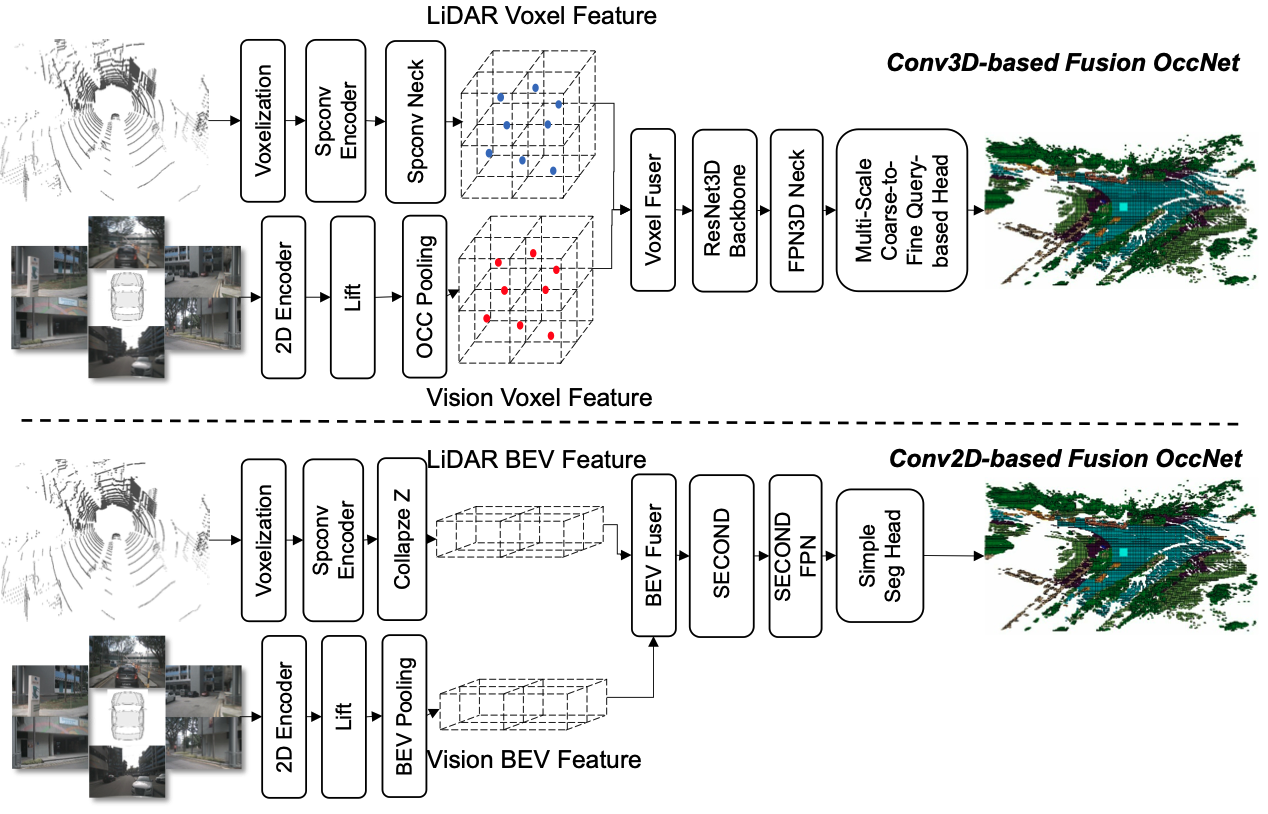
我们的设计目标是以尽可能少的网络参数实现相似的精度。我们从 OpenOccupancy [11] 中介绍的体素级密集融合方法开始。它由视觉分支、点云分支、由 3D 卷积算子支持的自适应体素融合模块以及具有从粗到细查询的多尺度分割头组成。
我们将每个模块替换为轻量级版本而不损失精度。
我们移除了 OpenOccupancy 激光雷达分支上的 3D CNN,将所有占据池化和 Conv3D 占据编码器替换为 BEVpoolv2 [12] 和 Conv2D BEV 编码器,并将体素融合层替换为 BEV 融合层。
此外,模型仅使用单尺度特征图和单阶段粗预测。我们的网络与体素级密集融合方法的对比如图 3 所示。
注
图3:EFFOcc融合占据网络框架与密集融合占据网络[10,11]的细节对比。我们的轻量级设计将体素特征替换为BEV特征,占据池化替换为BEV池化,ResNet3D骨干替换为SECOND骨干,并将复杂的由粗到精预测头替换为简单的Conv2D头。
重要
BEVPOOLING:
重要
BEV Fuser
对于点云分支,
- 我们使用均值特征编码作为体素特征编码(VFE)层,并使用下采样步幅为 8 的 Spconv8x 作为激光雷达编码器。
- 然后将稀疏 3D 特征展开为 BEV 特征。
对于图像分支,
- 我们使用图像编码器,并采用 BEVpoolv2 [12] 作为视图投影器以加速从透视视图到 BEV 的转换。我们采用简单的基于 Conv2d 的算子作为融合层。
融合层后,
- 我们使用轻量级 SECOND [13] 和 SECOND FPN 作为 BEV 以更多受益于检测预训练。
- 占据头由两个 Conv2d 层组成,高度通道从特征通道分离以生成最终 3D 输出。
我们使用先前工作中的损失函数:交叉熵损失 、Lovasz-softmax 损失 [14]、亲和力损失 和 [15]。对于 Occ3D-Waymo 案例,我们使用在线难例挖掘(OHEM)[16] 损失。Lovasz-softmax 损失和亲和力损失消耗更多 GPU 内存,并在 OpenOccupancy 基准测试上有显著提升,但在 Occ3D 基准测试上帮助较小(mIoU 提升 <1.0)。除非特别说明,大多数 Occ3D-nuScenes 基准测试实验仅使用交叉熵损失以节省训练阶段的 GPU 内存。总损失 是各损失的加权和:
我们设置所有权重 。
重要
亲和力损失:
重要
Lovasz-softmax 损失:
D. 多阶段占据蒸馏
蒸馏过程将融合 OccNet 的知识迁移到仅视觉 OccNet 以提升其性能。
首先,我们进行了一种朴素蒸馏,即在融合教师模型和仅视觉学生模型生成的 BEV 特征之间进行全空间特征对齐,但未能提升精度。一个可能的原因是占据网络需要同时处理前景、背景和空环境,并面临更严重的语义分布不平衡。我们对 BEV 特征图的统计发现,少于 1% 的支柱包含前景物体,约 40% 的支柱包含背景,其余支柱均为空。我们设计的蒸馏策略更关注前景体素。
受 BEV 检测器多阶段蒸馏实践的启发,我们在 BEV 空间和 3D 空间上进行蒸馏。我们将教师模型预测的前景、背景和空区域分解,并将区域输入到 BEV 空间和 3D 空间。
教师 和学生 之间的 BEV 特征蒸馏损失 和 3D 特征蒸馏损失 为:
其中前景区域掩码 、背景区域掩码 和空区域掩码 具有区域权重 、、。
表示 BEV 或 3D 特征图上的坐标索引。
所有区域掩码均为二值。 是 3D 特征图的宽度、长度和高度。 是前景区域网格的总和。
我们经验性地设置 以实现三个区域的平等平均。我们对 BEV 特征图计算均方误差(MSE)损失,对 3D 特征图计算余弦相似性损失。最终蒸馏损失 是 BEV 空间和 3D 空间蒸馏损失的加权和(权重为 和 )。
仅视觉学生网络在输入数据有标注时使用蒸馏损失和分类损失的总和进行训练,在输入数据未标注时仅使用蒸馏损失。
IV 实验
A. 数据集和指标
我们在三个流行的占据基准测试上验证模型:Occ3D-nuScenes [17]、Occ3D-Waymo [17]、OpenOccupancy-nuScenes [11]。所有基准测试对 3D 占据预测的主要指标是所有语义类别的平均交并比(mIoU)。设 为类别数,、 和 分别对应类别 的真阳性、假阳性和假阴性预测数。
Occ3D-nuScenes 基于大规模公开可用的 nuScenes 数据集 [18]。数据集包含 700 个训练场景、150 个验证场景和 150 个测试场景,每个场景以 2Hz 的关键帧率标注。自车的传感器配置为 6 个环视摄像头(分辨率 1600×900)和 1 个 32 线激光雷达。Occ3D-nuScenes 包含 17 个语义类别,包括通用物体类别。
Occ3D-Waymo 基于大规模公开可用的 Waymo Open Dataset [19]。数据集包含 1000 个序列用于训练验证集,其中 798 个序列用于训练集,202 个序列用于验证集。真值标签以 10Hz 标注。自车的传感器配置为 5 个环视摄像头(分辨率 1920×1280 或 1920×1080)和 5 个激光雷达。Occ3D-Waymo 包含 15 个语义类别,包括通用物体类别。
对于这两个数据集,Occ3D 将周围世界划分为分辨率为 [200,200,16] 的 3D 体素网格。感知范围为 [-40m,-40m,-5m,40m,40m,3m]。体素大小设置为 0.4m。
OpenOccupancy-nuScenes 同样基于 nuScenes [18] 数据集。该基准测试比 Occ3D-nuScenes 更具挑战性,因为它需要更宽的感知范围 [-51.2m,-51.2m,-5m,51.2m,51.2m,3m] 和更精细的分辨率 [512,512,40],体素大小设置为 0.2m。在语义类别上略有不同的是,OpenOccupancy 忽略了通用物体类别,仅包含 16 个语义类别。
B. 实现细节
数据预处理。 对于训练和推理阶段,我们首先加载多视角图像及其相机参数,然后对每个输入图像进行归一化、填充和多尺度翻转以进行图像增强。我们聚合多帧激光雷达点云,并对点云和体素标签进行随机翻转以进行 BEV 增强。我们不使用任何测试时增强技术。在训练阶段使用 Occ3D 基准测试的相机掩码。
训练和推理。 我们的代码基于 MMDetection3D 版本 1.0.0rc4 [20]。实验在 8 块 2080TI GPU 或 4 块 A6000 GPU 上进行,总批次为 16。我们使用 AdamW 优化器,学习率为 0.0001,权重衰减为 0.01。我们使用指数移动平均(EMA)钩子以获得更好的精度。在推理阶段,批次大小设置为 1。推理速度由单块 A6000 GPU 测量。
C. 有限标签下的高效学习结果
表 I 展示了 OccNets 在有限标签下的整体高效学习性能。我们分别使用不同比例的数据来训练融合网络和视觉网络。在此设置中,为了说明数据的效率,我们没有使用任何检测网络的预训练权重,因为检测网络是使用全部数据进行训练的。从表中可以看出,当训练数据非常有限时,融合网络仅使用相对较少的标注就能实现相当的性能,但视觉网络的性能较低。我们的蒸馏方法非常高效。通过高效学习技术,我们仅使用 40% 的标注序列就实现了 92.44% 的性能(mIoU=28.38),而使用全部标注训练的视觉网络的 mIoU 为 30.07。使用 80% 的标注数据时,经过蒸馏的 OccNet 比使用 100% 标注的视觉 OccNet 高出 1.04 mIoU。
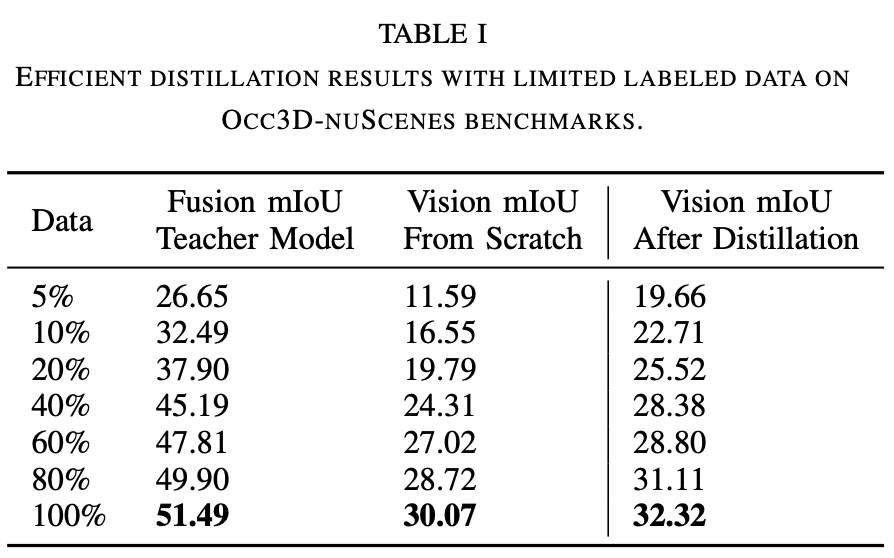
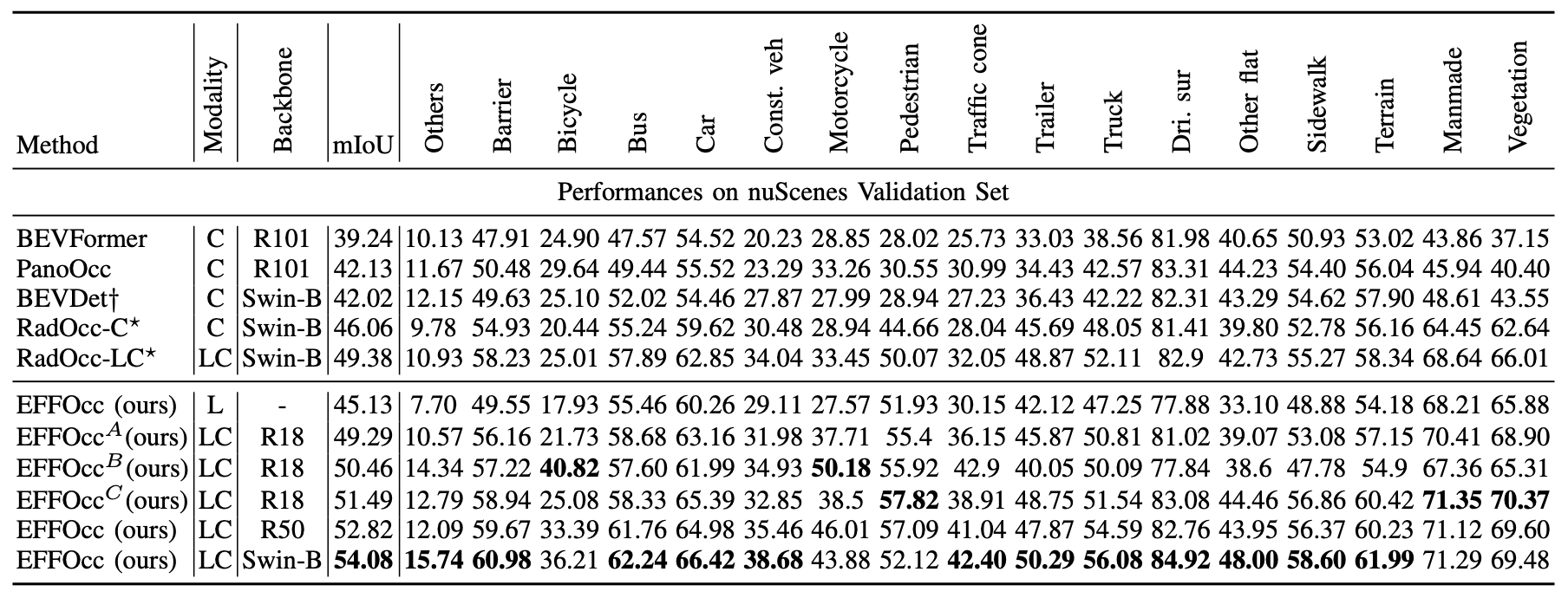
表 2。 Occ3D-nuScenes 验证集上的 3D 占据预测性能。† 表示通过官方代码复现的性能。* 表示原始论文提供的结果。我们报告了六种 EFFOcc 融合模型的变体。EFFOcc-R18^A 使用交叉熵损失训练 24 个周期。EFFOcc-R18^B 使用全部四种损失(交叉熵损失、Lovasz-softmax 损失、几何和语义亲和力损失)训练 24 个周期。EFFOcc-R18^A 和 EFFOcc-R18^B 均从 DAL [12] 的检测检查点初始化。EFFOcc-R18^C 使用交叉熵损失训练 48 个周期。EFFOcc-R50 和 EFFOcc-Swin-B 使用交叉熵损失训练 24 个周期。Const. veh. 指工程车辆,drl sur. 指可行驶表面。
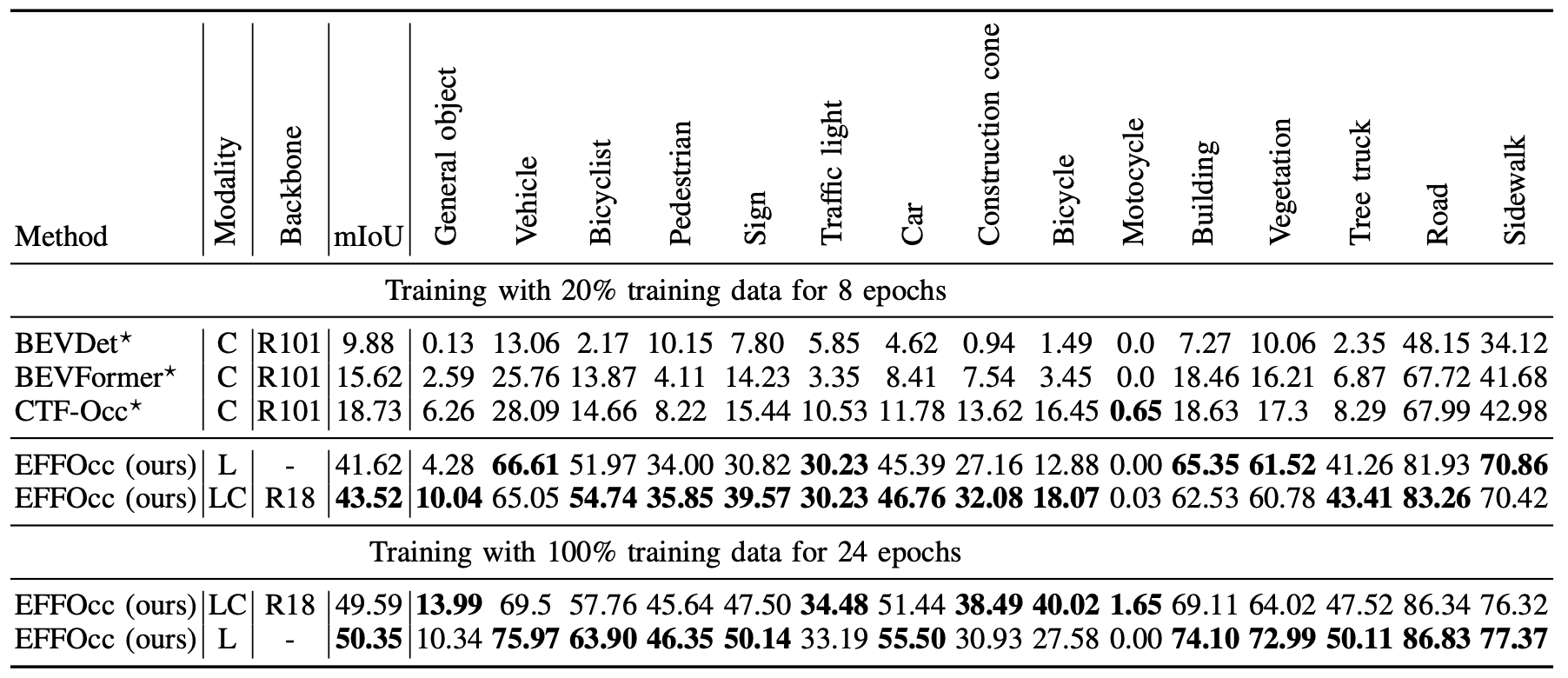
表 3. Occ3D-Waymo 验证集上的 3D 占据预测性能。† 表示通过官方代码复现的性能。* 表示 Occ3D [17] 提供的结果。
D. 提出的融合式占用网络的结果
- Occ3D-nuScenes 上的结果:表 II 展示了 Occ3D-nuScenes 验证集上的结果。基线是基于视觉的先进模型以及 RadOcc [10] 的教师模型 RadOcc-LC。
- 我们的纯激光雷达模型与基于 Swin-B [28] backbone的先进视觉模型相比,实现了类似的 mIoU 性能。我们提供了几种融合模型的变体,以讨论提升融合式 OccNet 达到先进水平的训练技术。
- EFFOcc-R18A 从检测检查点进行预训练,使用 ResNet-18 作为图像backbone,图像大小为 256×704,仅比 RadOcc-LC 低 0.09 mIoU,但运行速度显著更快。
- EFFOcc-B 采用三种额外的损失函数,与仅使用交叉熵损失训练的模型相比,mIoU 提高了 1.17。然而,使用多种损失函数会使训练时间翻倍。为此,我们尝试将训练计划延长至 48 个周期,并从头开始训练模型,模型性能提升至 51.49 mIoU,比 RadOcc-LC 高出 2.11 mIoU。
- 我们的实践表明,检测预训练和更长的训练计划有助于实现融合式 OccNet 的先进性能。我们进一步扩大图像 backbone,并分别使用 ResNet50 和 SwinTransformer-Base 作为图像backbone训练 EFFOcc-R50 和 EFFOcc-Swin-B。
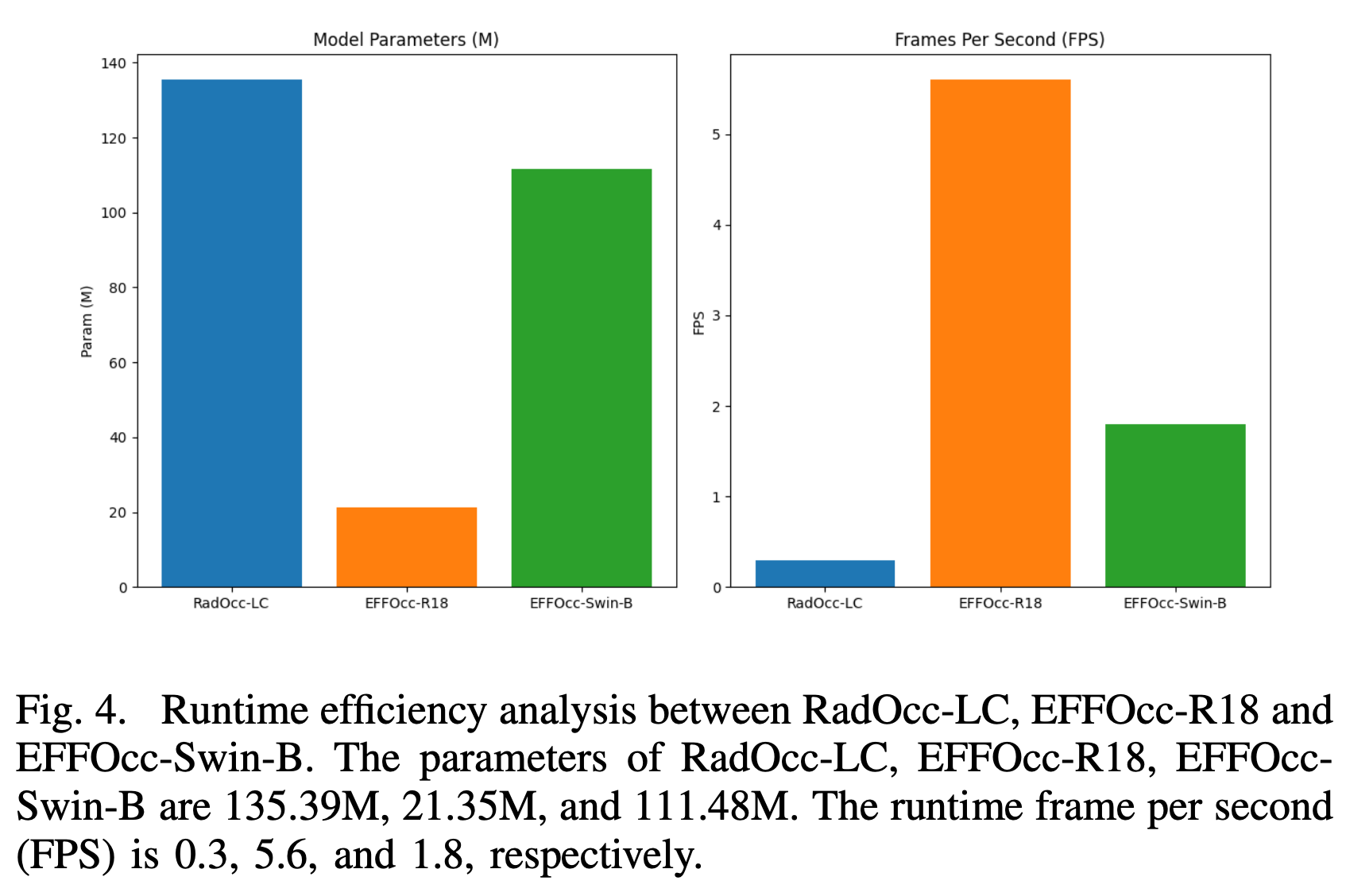
- 当使用更多参数的图像backbone时,模型性能进一步提升。EFFOcc-R50 使用 256×704 的图像大小,EFFOcc-Swin-B 使用 512×1408 的图像大小。EFFOcc-Swin-B 与使用 Swin-B backbone的 RadOcc-LC 相比,实现了显著的 +4.70 mIoU 增益。我们在图 4 中比较了融合式基线模型和我们模型的参数数量和运行速度。我们的模型是一个高度计算高效的占用网络,在类似 mIoU 精度的情况下,参数减少了 80% 以上,速度加快了 18 倍。
- Occ3D-Waymo 上的结果:表 III 展示了 Occ3D-Waymo 验证集上的结果。为了与视觉方法的评估对齐,我们仅评估对相机可见的体素。为了在较小的数据规模上快速验证,我们遵循 Occ3D [17] 的做法,仅使用 20% 的训练数据进行 8 个周期的训练。激光雷达模型的 mIoU 精度是视觉方法的两倍多,主要是因为 Waymo 的激光雷达比 nuScenes 的 32 线激光雷达强大得多。在激光雷达模型中添加轻量级图像分支可实现合理的 +1.90 mIoU 增益。如果模型在 100% 的数据上进行 24 个周期的训练,总共使用 150k 训练样本,则纯激光雷达模型的性能比融合模型高出 0.76 mIoU。图像分支导致精度下降的异常现象可能是由于激光雷达特征网络的充分训练、视觉覆盖不完全以及激光雷达与视觉之间的冲突。
- OpenOccupancy-nuScenes 上的结果:表 IV 展示了 OpenOccupancy-nuScenes 验证集上的结果。我们的模型比其他模型更轻量级,因为我们使用 ResNet-18 作为图像背景,图像大小为 256×704,而其他模型使用 ResNet-50 和 896×1600 的图像大小。与其他激光雷达 - 相机融合 OccNet 相比,我们实现了最佳的语义 mIoU 22.9 和最佳的几何 IoU 30.8。与 Occ3D-nuScenes 基准相比,我们的方法在更大的感知范围和更细的网格分辨率下也表现出同样良好的性能。
E. 基于知识蒸馏的视觉 OccNet 的结果
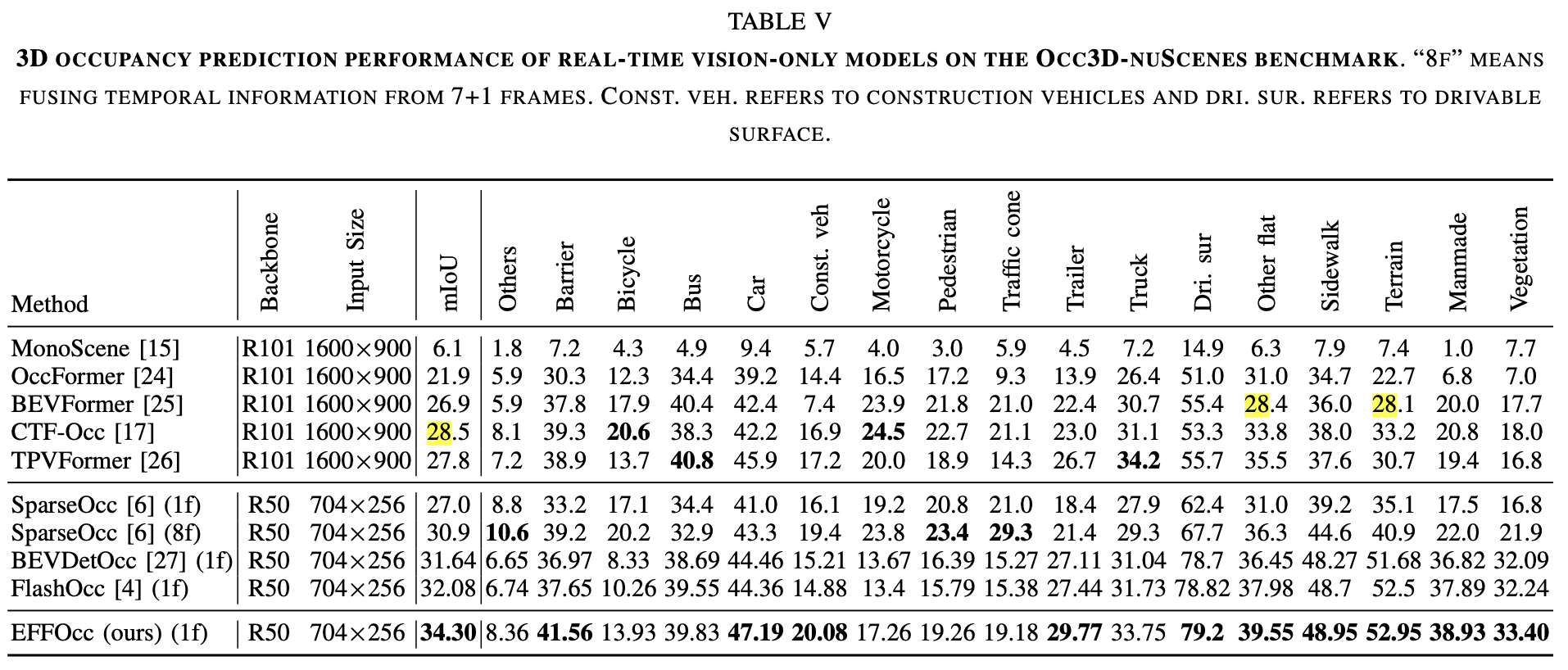
表 V 展示了基于视觉的占用网络的结果。我们对使用 ResNet-50 [29] 作为图像背景、输入大小为 704×256 的单帧图像的 FlashOcc 模型进行了蒸馏。该模型从 BEVDet [27] 的检测预训练检查点进行初始化。我们使用全部标注数据对视觉模型进行了 48 个周期的蒸馏。在此设置中,我们的蒸馏模型比基线 FlashOcc [4] 好 2.22 mIoU。我们在表 VI 中对不同的蒸馏方法进行了消融研究。我们首先在没有蒸馏的情况下训练 FlashOcc-R50 24 个周期。我们在鸟瞰图(BEV)和 3D 占用空间上进行蒸馏。我们测试了不同的损失函数,包括前景和背景重新加权的 L1 损失(FG/BG)、1 - 余弦相似度(1 - cosine)、均方误差(MSE)、交叉熵损失和 Kullback - Leibler(KL)散度损失。我们还测试了 BEV 蒸馏和 3D 蒸馏之间不同的权重。我们发现,BEV 和 3D 蒸馏的权重相等、BEV 空间的 MSE 损失和 3D 空间的 1 - 余弦损失显示出最佳的 mIoU 精度,为 33.93。
F. 定性结果
我们在图 5 中可视化了一个单帧的融合式、基于视觉的以及经过蒸馏的占用预测示例。与蒸馏前的基于视觉的模型相比,经过蒸馏的模型与融合式教师模型更好地对齐,尤其是在远处物体的重建方面。
V 结论
本文主要讨论了以最小标签和计算成本训练占据网络的最小工作流程设计。在两大公开数据集上达到或超越现有 OccNets 性能的同时,我们显著降低了训练成本并提升了可用性。此外,我们设计了一种多阶段蒸馏策略,使融合网络能够提升轻量级仅视觉占据网络的精度。未来工作将研究更有效的主动学习技术,以寻找 OccNets 所需的最小标签。
参考文献
(参考文献内容省略)