
MonoScene
Monocular 3D Semantic Scene Completion
https://blog.csdn.net/kebijuelun/article/details/127405153
摘要
MonoScene 提出了一种单目 3D 语义场景补全(SSC)框架,能够从单张 RGB 图像中推断场景的密集几何结构和语义信息。与依赖于 2.5D 或 3D 输入的现有 SSC 方法不同,我们解决了从 2D 到 3D 的复杂场景重建问题,同时联合推断其语义信息。我们的框架依赖于连续的 2D 和 3D UNet 网络,通过一种新颖的 2D-3D 特征投影模块(FLoSP)连接,该模块受到光学原理的启发,并引入了一个 3D 上下文关系先验(3D CRP)以增强空间语义一致性。除了架构上的贡献,我们还提出了新的全局场景和局部视锥损失函数。实验表明,MonoScene 在所有指标和数据集上的表现均优于现有方法,甚至能够在相机视野之外合理地生成场景。我们的代码和预训练模型可在 github 获取。
1. 引言
从图像中估计 3D 信息是计算机视觉领域的经典问题之一 [54]。尽管人类能够自然地从单张图像中理解场景,同时推断出几何和语义信息,但数十年的研究表明,这一任务的复杂性不容小觑 [57, 75, 80]。因此,许多算法依赖于专用的深度传感器,例如激光雷达(Lidar)[36, 50, 62] 或深度相机 [2, 15, 19],这些传感器简化了 3D 估计问题。然而,这些传感器通常比普通相机更昂贵、体积更大且更具侵入性。相比之下,相机被广泛应用于智能手机、无人机、汽车等设备中。因此,能够从图像中估计 3D 场景将为许多新应用铺平道路。
3D 语义场景补全(SSC)旨在联合推断场景的几何和语义信息,近年来受到越来越多的关注 [56]。然而,现有的方法仍然依赖于深度数据(例如占用网格、点云、深度图等),并且大多数方法是为室内或室外场景专门设计的。在这里,我们提出了 MonoScene,它与现有文献不同,仅依赖于单张 RGB 图像来推断密集的 3D 体素化语义场景,无论室内还是室外场景都能适用。
为了解决这一极具挑战性的问题,我们受光学原理启发,将 2D 特征沿视线方向投影,从而将 2D 和 3D 网络连接起来,同时让 3D 网络自行发现相关的 2D 特征。现有的 SSC 文献主要依赖于交叉熵损失函数,该函数独立地考虑每个体素,缺乏上下文感知能力。相比之下,我们提出了新的 SSC 损失函数,用于优化一组体素的语义分布,既包括全局范围,也包括局部视锥范围。最后,为了进一步增强上下文理解能力,我们设计了一个 3D 上下文层,为网络提供全局感受野以及体素语义关系的洞察。
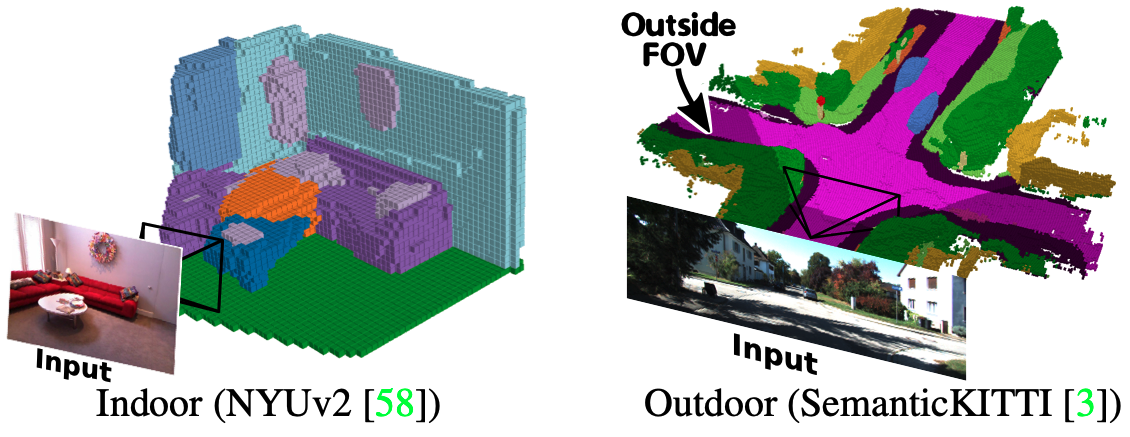
图 1. 使用 MonoScene 进行 RGB 语义场景补全。 我们的框架从单张 RGB 图像推断出密集的语义场景,并能够合理地推测出图像视野范围之外的场景(右侧的深色体素)。
我们在室内和室外场景上广泛测试了 MonoScene(见图 1),它在所有可比基线方法上均表现出色,甚至在某些使用 3D 输入的基线方法上也表现优异。我们的主要贡献总结如下:
- MonoScene:首个仅使用单张 RGB 图像处理室内和室外场景的 SSC 方法。
- 2D 特征视线投影机制(FLoSP,第 3.1 节),用于连接 2D 和 3D 网络。
- 3D 上下文关系先验(3D CRP,第 3.2 节)层,用于增强网络的上下文感知能力。
- 新的 SSC 损失函数,用于优化全局场景类别亲和力(第 3.3.1 节)和局部视锥比例(第 3.3.2 节)。
2. 相关工作
单目图像的三维重建
尽管早期的研究 [31, 57, 80] 已经涉及了从单目图像中估计三维信息的问题,但在深度学习时代,最初的研究主要集中在单个三维物体的重建上,这些研究使用了显式 [1, 11, 16, 23, 26, 43, 63, 65–67, 70] 或隐式 [47, 49, 51, 52, 68] 表示。关于这一主题的全面综述可以参考文献 [30]。对于多个物体,常见的做法是将重建与目标检测结合起来 [27, 28, 34, 35, 78]。与我们的工作更接近的是,整体三维理解试图预测场景和物体的布局 [32, 37, 48, 60, 75, 83],从而达到稀疏的场景表示。最近,文献 [18] 针对室内场景提出了密集的可见全景重建,通过将单个二维任务特征反向投影到三维空间来实现。相比之下,我们的方法则致力于密集地估计室内外场景的语义和几何信息。
三维语义场景补全(SSC)
SSCNet [59] 首次定义了“SSC”任务,即联合推断几何和语义信息。这一任务最近受到了越来越多的关注,并在综述 [56] 中进行了全面的回顾。现有的方法都使用了几何输入,例如深度图 [12, 25, 39–42, 45]、占用网格 [13, 25, 55, 69] 或点云 [53, 81]。截断符号距离函数(TSDF)也被证明是很有用的 [6, 9, 10, 12, 20, 21, 41, 59, 64, 77, 79]。在其他一些创新中,有些 SSC 方法使用对抗性训练来指导真实感 [10, 64],采用多任务学习 [6, 38],或者使用轻量级网络 [40, 55]。对我们来说,值得注意的是,尽管有些方法使用了 RGB 图像作为输入 [6, 8, 9, 14, 20, 20, 25, 29, 39, 40, 42, 45, 81],但它们总是与其他几何输入(例如深度、TSDF 等)一起使用。一个显著的点是 [56] 中提到的,现有方法是为室内或室外场景设计的,在另一种场景中表现欠佳。同一综述还强调了 SSC 中损失函数的多样性不足。相比之下,我们仅使用单张 RGB 图像来解决 SSC 问题,引入了新的 SSC 损失函数,并且对各种类型的场景都具有鲁棒性。
上下文感知
上下文特征对于语义 [71] 和 SSC [56] 任务至关重要。一种简单的策略是使用跳跃连接将多尺度特征连接起来 [9, 19, 45, 59, 77],或者使用扩张卷积来获得较大的感受野,例如流行的 Atrous Spatial Pyramid Pooling(ASPP)[7],它也被用于 SSC [39, 40, 45, 55]。通过自注意力机制 [24, 33] 和全局池化 [72, 76] 来收集长距离信息。文献 [71] 表明,显式的上下文学习是有益的。我们提出了一个 3D 上下文组件,它利用多个关系先验,并提供全局感受野。
3. 方法

图 2. MonoScene 框架。
我们从单张 RGB 图像推断三维语义场景补全(SSC),利用 2D 和 3D UNet,通过我们的特征视线投影(FLoSP,第 3.1 节)连接,同时使用 3D 上下文关系先验(3D CRP,第 3.2 节)增强空间语义感知能力。在标准交叉熵损失()的基础上,我们的场景类别亲和力损失(,第 3.3.1 节)优化了全局语义()和几何()性能,视锥比例损失(,第 3.3.2 节)则对局部视锥中的类别分布进行优化,为遮挡部分提供额外的监督。
三维语义场景补全(SSC)的目标是联合推断三维场景的几何和语义信息,通过预测语义类别,其中表示自由空间类别,表示语义类别数量。这一任务几乎完全依赖于 2.5D 或 3D 输入 [56],例如点云、深度图等,这些输入作为强大的几何线索。然而,MonoScene 仅从单张 RGB 图像解决体素化的 SSC 问题,学习。
由于从 2D 恢复 3D 的复杂性,这要困难得多。我们的流程如图 2 所示,使用 2D 和 3D UNet,通过我们的特征视线投影模块(FLoSP,第 3.1 节)连接,将 2D 特征提升到可能的 3D 位置,从而增强信息流并实现 2D-3D 解耦。
受 [71] 启发,我们通过 3D 上下文关系先验组件(3D CRP,第 3.2 节)捕获长距离语义上下文,该组件插入在 3D 编码器和解码器之间。
为了指导 SSC 训练,我们引入了新的互补损失函数。首先,场景类别亲和力损失(第 3.3.1 节)优化了类内和类间的场景级指标。其次,视锥比例损失(第 3.3.2 节)对齐局部视锥中的类别分布,为场景遮挡提供了额外的监督。
2D-3D 骨干网络
我们依赖于连续的 2D 和 3D UNet 网络,并使用标准的跳跃连接。2D UNet 基于预训练的 EfficientNetB7 [61],输入为图像。3D UNet 是一个自定义的浅层编码器-解码器,包含两层。SSC 输出通过处理 3D UNet 的输出特征,使用我们的完成头模块获得,该模块包含一个 3D ASPP [7] 块和一个 softmax 层。
3.1 特征视线投影(FLoSP)
从 2D 提升到 3D 是一个众所周知的病态问题,因为单视点存在尺度歧义 [22]。我们不是直接解决尺度问题,而是从光学角度出发,将多尺度 2D 特征反向投影到所有可能的 3D 对应点,即沿着它们的光学射线进行聚合,形成一个唯一的 3D 表示。我们的直觉是,通过 3D 网络处理这种表示,可以为网络提供一组 2D 特征的指导。与 [52] 类似,我们的投影机制将 2D 特征投影到给定的 3D 地图上,作为 2D-3D 跳跃连接。然而,我们的组件通过将多尺度 2D 特征提升到单个 3D 特征图,连接 2D 和 3D 网络。我们主张这使得 2D-3D 表示解耦,为 3D 网络提供了使用高级 2D 特征进行细粒度 3D 消歧的自由度。与 [52] 相比,第 4.3 节的消融实验表明,我们的策略显著更好。
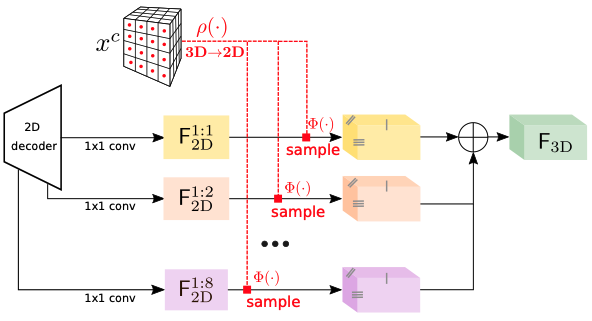
图 3. 特征视线投影(Features Line of Sight Projection, FLoSP)。
我们沿着 2D 特征的视线方向进行投影,通过采样()将它们放置在 3D 体素质心()投影到 2D 平面上的位置()。这一过程增强了 2D 和 3D 之间的信息流动,并允许 3D 网络自主发现哪些 2D 特征是相关的。在实践中,假设已知相机内参,我们将 3D 体素质心()投影到 2D 平面上,并从 2D 解码器特征图 中采样对应的特征,其中 表示特征图的下采样比例。我们从多个尺度 (例如 )重复这一过程,并将采样得到的特征进行聚合,形成最终的 3D 特征图 。如果某个体素投影到图像外,其特征向量将被设置为零。最终的 3D 特征图 用作 3D UNet 的输入。
我们的过程如图 3 所示。假设已知相机内参,我们将 3D 体素质心 投影到 2D 并从 2D 解码器特征图中采样对应的特征,比例为。在所有尺度上重复这一过程,最终的 3D 特征图可以表示为:
其中,表示在坐标处对进行采样,是透视投影。实际上,我们从尺度进行反向投影,并在采样前对 2D 特征图应用卷积,以便进行求和。投影到图像外的体素,其特征向量被设置为 0。输出图用作 3D UNet 的输入。
3.2 3D 上下文关系先验(3D CRP)
由于 SSC 高度依赖于上下文 [56],我们受 CPNet [71] 的启发,该研究表明二元上下文先验对于 2D 分割是有益的。在这里,我们提出了一个 3D 上下文关系先验(3D CRP)层,插入到 3D UNet 的瓶颈处,该层学习元体素 体素语义场景关系图。这为网络提供了全局感受野,并通过关系发现机制增强了空间语义感知能力。由于 SSC 是一个高度不平衡的任务,学习二元(即)关系如 [71] 是次优的。
体素体素关系
我们考虑体素 体素关系,判断其中一个是否为空闲,以及它们的语义类别是否相似或不同。对于每组,我们编码是否两个体素都被占用,分别对应于“至少有一个体素为空”和“两个体素都被占用”。对于每组,我们编码它们的语义类别是否相似或不同,从而得到 4 个不重叠的关系:。
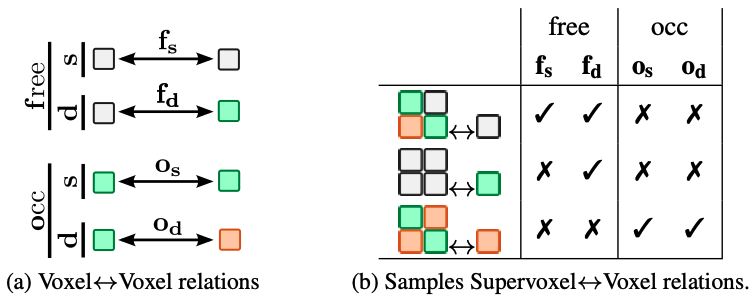
图 4. 2D 体素关系图示。
(a) 我们考虑体素之间的四种关系:两个体素都为空(free),两个体素都被占用且语义类别相同(occupied-similar),两个体素都被占用但语义类别不同(occupied-different),以及一个体素为空而另一个体素被占用(one free, one occupied)。
(b) 为了减少计算量,我们采用“超体素↔体素”关系,将体素分组为非重叠的超体素,并预测这些超体素与单个体素之间的关系,而不是直接计算所有体素对之间的关系。(灰色表示 free;彩色表示 occupied,颜色表示语义)
图 4a 以 2D 形式展示了这些关系(见图例中的颜色含义)。由于体素关系是贪婪的,对于个体素有个关系,我们提出了更轻量的超体素 体素关系。
超体素体素关系
我们定义超体素为 个相邻体素组成的非重叠组,学习大小为的超体素 体素关系矩阵。假设超体素包含体素,以及一个体素,则存在对关系。而不是回归中关系的复杂计数,我们预测哪些关系存在,如图 4b 所示。这可以表示为:
其中,返回集合中不同的元素。
3D 上下文关系先验层
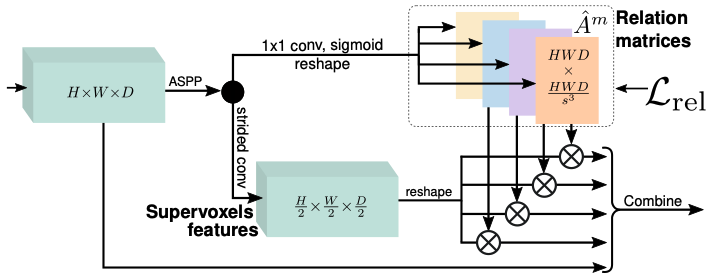
图 5. 3D 上下文关系先验(3D CRP)。
我们推断关系矩阵 (这里,4 表示 4 种关系),每个矩阵编码一种独特的体素关系 ,可选地通过关系损失 进行监督。将关系矩阵与超体素特征相乘,以收集上下文信息,并与输入特征结合(通过拼接、卷积、DDR [40]),用于后续处理。图中省略了特征维度。
图 5 展示了我们这一层的架构。
它以空间维度为的 3D 地图作为输入,在其上应用一系列 ASPP 卷积 [7] 以收集较大的感受野,然后将其拆分为个大小为的矩阵。每个矩阵编码一个关系,并由其真实值进行监督。
然后,我们优化加权多标签二元交叉熵损失:
其中,遍历关系矩阵的所有元素,。关系矩阵与重塑后的超体素特征相乘,以收集全局上下文信息。或者,关系矩阵中的关系可以是自发现的(不使用),通过移除,即表现为注意力矩阵。
3.3 损失函数
我们现在介绍新的损失函数,旨在实现不同的全局(第 3.3.1 节)或局部(第 3.3.2 节)优化目标。
3.3.1 场景类别亲和力损失
我们希望明确地让网络了解全局 SSC 性能。为此,我们基于 [71] 中的 2D 二元亲和力损失,引入一个多类别版本,直接优化场景级和类别级指标。具体来说,我们优化类别级可微的(P)recision、(R)ecall 和(S)pecificity,其中和衡量相似类别体素的性能,而衡量不同类别体素(即非类别)的性能。假设是体素的真实类别,是其被预测为类别的概率,我们定义:
其中,是伊万斯括号。为了更具一般性,我们的损失最大化上述类别级指标:
在实际应用中,我们优化语义 和几何 ,其中 分别是语义和几何标签及其预测值。
3.3.2 视锥比例损失
从单个视点消除遮挡是无法实现的,我们观察到遮挡体素倾向于被预测为遮挡它们的物体的一部分。为了减轻这种效应,我们提出了视锥比例损失,明确优化视锥中的类别分布。如图 6 所示,我们将输入图像划分为大小的局部块,每个块对应场景中的一个 3D 视锥,我们在每个局部视锥上应用该损失(定义为块中各个像素视锥的并集)。直观上,对齐视锥分布为网络提供了关于场景可见和遮挡结构的额外线索,让网络能够感知到可能被遮挡的内容(例如,汽车可能会遮挡道路)。对于视锥,我们计算作为中体素的真实类别分布,以及作为类别在中的比例。设和是它们的软预测对应物,通过对每个类别的预测概率求和得到。为了强制一致性,我们计算作为局部视锥的 Kullback-Leibler (KL) 散度之和:
注意,这里使用的是,而不是。事实上,视锥中只包含场景的小部分,其中某些类别可能缺失,这使得 KL 散度在局部上无法定义。因此,我们在上计算 KL 散度,即视锥中存在的真实类别。
3.4 训练策略
MonoScene 通过优化我们的 4 个损失函数和标准交叉熵损失()进行端到端的训练:
由于真实世界的数据由于遮挡而具有稀疏的真实标签,因此损失函数仅在定义的地方进行计算 [45, 56, 59]。真实标签和(用于和)分别从中简单地获得。我们遵循 [9, 55] 的方法,为使用类别权重。
4. 实验
我们在流行的室内 NYUv2 [58] 和室外 SemanticKITTI [3] 数据集上评估了 MonoScene 的性能。由于我们首次尝试仅从单张 RGB 图像进行三维语义场景补全(SSC),因此我们在第 4.1 节详细介绍了对最近 SSC 基线方法 [9, 39, 55, 69] 的非平凡调整,并在第 4.2 节详细说明了我们的性能表现,以及在第 4.3 节进行的消融研究。
数据集
NYUv2 [58] 包含 1449 个使用 Kinect 捕获的室内场景,编码为 240×144×240 的体素网格,标注了 13 个类别(11 个语义类别、1 个自由空间类别和 1 个未知类别)。输入 RGBD 图像的尺寸为 640×480。类似于 [9, 39, 40, 45],我们使用 795/654 的训练/测试分割,并在测试集上进行评估,比例为 1:4。SemanticKITTI [3] 包含室外激光雷达扫描,体素化为 256×256×32 的网格,体素尺寸为 0.2 米,标注了 21 个类别(19 个语义类别、1 个自由空间类别和 1 个未知类别)。我们使用尺寸为 1226×370 的第 2 个相机的 RGB 图像,并将其左侧裁剪为 1220×370。我们使用官方的 3834/815 训练/验证分割,并始终在全尺寸(即 1:1)下进行评估。主要结果来自隐藏的测试集(在线服务器),消融研究则来自验证集。
训练设置
除非另有说明,我们使用 FLoSP 的尺度为 (1, 2, 4, 8),3D CRP 的监督关系数为 4(即 ,并使用 ),以及 的视锥用于 。由于内存原因,NYUv2 的 3D UNet 输入尺寸为 60×36×60(比例为 1:4),SemanticKITTI 的输入尺寸为 128×128×16(比例为 1:2)。由于内存限制,SemanticKITTI 的输出通过完成头中的反卷积层放大到 1:1 的比例。详细信息见附录 A。我们使用 AdamW [46] 优化器进行训练,批量大小为 4,权重衰减为 。学习率设置为 ,在第 20 和 25 个 epoch 时,NYUv2 和 SemanticKITTI 的学习率分别降低 10 倍。
评估指标
按照常见做法,我们报告了场景补全(SC)任务的占用体素的交并比(IoU),不考虑其语义类别,以及语义场景补全(SSC)任务的所有语义类别的平均交并比(mIoU)。需要注意的是,IoU 和 mIoU 之间存在强烈的相互作用,因为通过降低语义标签的准确性(即降低 mIoU)可以更容易地获得更好的几何估计(即更高的 IoU)。正如 [56] 中提到的,室内和室外设置的训练和评估实践有所不同:室内评估仅在观察到的表面和遮挡体素上进行,而室外评估则在所有体素上进行,这是由于深度/激光雷达数据的稀疏性不同。为了应对这两种设置,我们在所有体素上使用更严格的评估指标。随后,我们重新训练了所有基线方法。
4.1 基线方法
我们考虑了 4 种主要的 SSC 基线方法,这些方法是目前开源的最优方法之一,包括 2 种室内设计方法:3DSketch [9] 和 AICNet [39],以及 2 种室外设计方法:LMSCNet [55] 和 JS3CNet [69]。我们还在本地与 S3CNet [12]、Local-DIFs [53] 和 CoReNet [52] 进行了比较。我们分别在它们的 3D 输入版本和主要基线的 RGB 推理版本上进行了评估。RGB 推理基线。与我们不同的是,所有基线都需要一个 3D 输入,例如占用网格、点云或深度图,这为它们提供了不公平的几何优势。为了公平比较,我们调整了主要基线,使其能够直接从二维图像()推断出它们的 3D 输入,我们将其称为“RGB 推理”,并用上标表示,例如 AICNet。请注意,基线方法本身并未改变。推断的 3D 输入用帽子表示,例如 。我们使用预训练的 AdaBin [4] 来推断深度图(),作为 AICNet的输入。利用内在校准,我们进一步将深度转换为 TSDF()[74],作为 3DSketch的输入,并将深度反投影为点云(),直接用作 JS3CNet的输入,或者将其离散化为占用网格()作为 LMSCNet的输入。对于训练,JS3CNet还需要一个语义点云(),这是通过将 与预训练网络 [82] 得到的二维语义标签结合起来获得的。
4.2 性能
4.2.1 评估
表 1 报告了 MonoScene 和 RGB 推理基线在 NYUv2(测试集)和 SemanticKITTI 官方基准(隐藏测试集)上的性能。所有方法的低分数都证明了该任务的复杂性。在两个数据集上,我们都以显著的 mIoU 优势超过了所有方法,在 NYUv2(表 1a)上提高了 +4.03,在 SemanticKITTI(表 1b)上提高了 +2.11。重要的是,IoU 也得到了提高或保持一致(分别提高了 +3.87 和 +0.16),这表明我们的网络在捕捉场景几何结构的同时,避免了通过降低 IoU 来不恰当地提高 mIoU。在各个类别上,MonoScene 要么表现最佳,要么排名第二,在两个数据集的大结构类别上表现出色(例如室内场景的地板、墙壁;室外场景的道路、建筑)。在 SemanticKITTI 上,我们在小运动物体类别(汽车、摩托车、人等)上被超越,我们认为这是由于地面真实情况中对运动物体的聚合,这一点在 [53, 56] 中被强调。这迫使我们预测单个物体的运动,我们认为当使用 3D 输入时,这一任务会变得更加容易。
定性分析。我们在图 7 中比较了我们的 SSC 输出,显示输入图像(最左列)及其对应的相机视锥在真实情况(最右列)中的表现。请注意 NYUv2 中的噪声标签,其中缺少物体(例如第 2 行的窗户;第 3 行的天花板),以及 SemanticKITTI 中的稀疏几何结构(例如第 1-3 行中建筑物的孔洞)。在室内场景(NYUv2,图 7a)中,所有方法都能正确捕捉到全局场景布局,但只有 MonoScene 能够恢复薄元素,如桌子腿和靠垫(第 1 行),或者画框和尺寸合适的电视(第 2 行)。在复杂的室外场景(SemanticKITTI,图 7b)中,与基线相比,MonoScene 显然能够更好地捕捉场景布局,例如十字路口(第 1、3 行)。它还能推断出更精细的被遮挡的几何结构,这在第 1-3 行的汽车形状中尤为明显。有趣的是,尽管相机的视野范围相对场景较窄,MonoScene 仍然能够合理地推测出视野范围之外的场景(较暗的体素)。这在第 3、4 行中尤为突出,底部场景被合理地猜测出来,尽管它不在视野范围内。附录 B.1 提供了视野内外性能的详细信息。
4.2.2 与 2.5/3D 输入基线的比较
为了完整性,我们在表 2 中还将 MonoScene 与一些原始基线进行了比较(即使用真实的 3D 输入)。尽管这种设置对我们来说是不公平的,因为我们只使用了 RGB,但在 NYUv2(表 2a)中,我们仍然在 mIoU 上超过了最近的 LMSCNet 和 AICNet,分别提高了 +6.48 和 +3.17,尽管 IoU 略有下降(-1.6 和 -1.26)。值得注意的是,AICNet 也使用了 RGB 和深度信息,这表明我们的方法在仅使用图像的情况下就能很好地恢复几何结构。3DSketch 使用 RGB + TSDF,在 mIoU 和 IoU 上都超过了我们,这表明 TSDF 对 SSC 的好处,正如 [56] 中提到的。在 SemanticKITTI(表 2b)中,基线方法在所有指标上都明显超过了我们,这既与激光雷达起源的 3D 输入的水平视场角比相机宽得多有关(180° vs 82°),也与更复杂、更混乱的室外场景有关——这些场景更难从单个图像视点重建。表 2 中 2D 和 2.5/3D 之间的大差距部分是由于深度精度较低。例如,在 NYUv2/Sem.KITTI 上,AdaBins [4] 的 RMSE 分别为 0.36/2.36 米,而体素的尺寸为 0.08/0.2 米。此外,由于我们考虑了被遮挡的体素,我们的几何结构如预期一样更好。这通过使用 MonoScene 的几何结构作为 LMSCNet 的输入来评估,在 SemanticKITTI 验证集上,IoU/mIoU 从 28.61/6.70 提高到 35.94/9.44。尽管如此,表 3 显示 MonoScene 在预测几何结构和语义方面仍然表现更好,分别达到了 37.12/11.50。
4.3 消融研究
我们在 NYUv2(测试集)和 SemanticKITTI(验证集)上对 MonoScene 框架进行了消融研究,并报告了 3 次运行的平均值,以考虑训练的变异性。架构组件。表 3 显示所有组件都对最佳结果做出了贡献。“无 FLoSP”时,我们通过插值和卷积将 2D 解码器特征调整到所需的 3D UNet 输入大小。具体来说,FLoSP(第 3.1 节)被证明是最关键的,因为它显著提高了语义(在 NYUv2 上提高了 +12.83,在 SemanticKITTI 上提高了 +6.72)和几何(在 NYUv2 上提高了 +14.11,在 SemanticKITTI 上提高了 +9.56)的性能。3D CRP(第 3.2 节)对 IoU(分别提高了 +0.77 和 +1.12)和 mIoU(分别提高了 +0.54 和 +1.33)的贡献相等。两个 SCAL 损失(第 3.3.1 节)的贡献如预期不同,因为 有助于语义(在两个数据集上分别提高了 +1.61 mIoU),而 则提高了几何(分别提高了 +1.55 和 +2.20 IoU)。在 NYUv2 中,稍微降低了 IoU(-0.31),但在 SemanticKITTI 上提高了相同的指标(+0.34)。最后,视锥比例损失(第 3.3.2 节)在两个数据集上都至少提高了 +0.38,并且最高可达 +0.61。
特征投影的效果。我们现在深入研究 FLoSP(第 3.1 节)在我们基于 RGB 的任务中的效果。在表 4a 中,我们使用 FLoSP 仅从给定的 2D 尺度投影 2D 特征,通过改变公式 (1) 中的 来实现。更多的 2D 尺度能够持续提高 IoU 和 mIoU,并且倾向于降低方差——这表明 (1, 2, 4, 8) 投影确实是最佳选择。
更多的 2D 尺度能够持续提高 IoU 和 mIoU,并且倾向于降低方差——这表明 (1, 2, 4, 8) 投影确实是最佳选择。
在表 4a 中,我们研究了在 FLoSP(第 3.1 节)中使用不同的 2D 尺度()进行投影的效果。结果表明,使用更多的 2D 尺度可以显著提升性能,尤其是在 NYUv2 数据集上,使用 (1, 2, 4, 8) 的投影组合表现最佳。此外,这种多尺度投影方式还能降低结果的方差,说明其性能更加稳定。
我们进一步将 FLoSP 与 CoReNet [52] 中的“光线追踪跳跃连接”进行了比较,后者在性质上与 FLoSP 相近。为了公平地评估仅特征投影的效果,我们移除了其他组件,创建了一个轻量级版本(“Ours-light”),它使用了相同的 2D 编码器(E)、3D 解码器(D)和投影尺度(1, 2, 4),如图 8a 所示。这些尺度对应于 3D 解码器中所有可能的尺度,与 CoReNet 的设置一致。在 NYUv2 数据集上,如图 8b 所示,FLoSP 的性能显著优于 CoReNet(在相同的 (1, 2, 4) 尺度下,IoU 提高了 +10.2,mIoU 提高了 +8.56)。即使仅使用单一尺度 (1) 进行投影,我们的方法仍然表现良好。我们推测,这种性能差异可能是由于 CoReNet 使用相同尺度的 2D-3D 连接,而 FLoSP 则允许 2D 和 3D 尺度解耦,让网络能够自主学习哪些 2D 特征对于 3D 消歧更为重要,这一观点也得到了第 4.3 节消融实验的支持。
3D CRP(第 3.2 节)的效果。尽管在表 3 中已经证明 3D CRP 对性能有益,但我们在表 4b 中进一步研究了不同数量的关系()以及是否使用监督()的影响。结果表明,使用更多的关系(即 )相比于仅使用 2 种关系(即 )能够带来更高的性能指标。这与我们的预期一致,因为 NYUv2 数据集中自由空间与占用空间体素的比例大约为 9:1,存在严重的类别不平衡问题。此外,通过关系损失 对关系矩阵 进行监督也能够进一步提升所有指标。如果不使用监督,我们的 3D CRP 将作为自注意力层,隐式地学习上下文信息。
视锥比例损失的效果。表 5 展示了在两个数据集上,改变局部视锥数量()对性能的影响。视锥数量的增加意味着视锥尺寸的减小,即提供了更细粒度的局部监督。随着 的增大,所有指标均有所提升,这表明视锥比例损失确实能够为网络提供更精细的指导,尤其是在与仅在图像级别(即 )应用损失函数相比时,其优势更加明显。
5. 讨论
MonoScene 通过使用连续的 2D 和 3D UNet 网络,结合新的特征投影模块、增强的上下文感知能力和新的损失函数,首次实现了从单目 RGB 图像中进行语义场景补全(SSC)。尽管取得了良好的结果,但我们的框架仍然存在一些局限性。尽管如此,这项工作为从单张图像中理解 3D 场景开辟了新的可能性,为混合现实、照片编辑和移动机器人等领域带来了新的机遇。
局限性
尽管 MonoScene 在多个数据集上取得了良好的性能,但该框架在推断精细几何结构方面仍然存在挑战,尤其是在分离语义相似的类别(例如汽车/卡车或椅子/沙发)时。此外,由于单目图像的视角限制,模型在处理小物体时表现不佳,这主要是因为这些小物体在数据集中较为稀疏(例如在 SemanticKITTI [3] 中占比不到 0.3%)。此外,由于我们利用 2D-3D 投影的 FLoSP 模块(第 3.1 节),我们在不同相机设置的数据集上进行了实验,结果表明,当测试集的相机设置与训练集相差较大时,结果虽然仍然具有一致性,但会出现更大的失真现象。如图 9 所示,随着相机水平视场角(FOV)的增加或减少,预测结果的失真程度也随之增加。
更广泛的影响与伦理问题
从单张图像中联合理解 3D 几何结构和语义信息,为混合现实、照片编辑和移动机器人等领域带来了新的机遇。然而,场景理解中不可避免的错误可能会带来严重的后果(例如在自动驾驶领域),因此这类算法应始终与其他手段相结合以确保安全。
致谢
本研究使用了 GENCI–IDRIS 提供的高性能计算资源(项目编号 2021-AD011012808)。该研究是在 SAMBA 合作项目中完成的,该项目由 BpiFrance 在“未来投资计划”中共同资助。
附录
A. 架构细节
A.1 基线方法
- AICNet [39]:我们使用了 AICNet 的官方实现。对于 RGB 推理版本(AICNet),我们使用预训练的 AdaBins [4] 在 NYUv2 [58] 和 SemanticKITTI [3] 上预测深度图。
- 3DSketch [9]:我们使用了 3DSketch 的官方代码。对于 3DSketch,我们再次使用 AdaBins(如上所述),并将深度图转换为 TSDF,使用“tsdf-fusion”[74] 从 3DMatch Toolbox 中实现。
- JS3C-Net [69]:我们使用了 JS3C-Net 的官方代码。对于 JS3C-Net,我们通过将预测的深度图(使用 AdaBins)反投影到 3D 空间,生成输入点云。JS3C-Net 在训练时还需要语义点云,这些语义点云是通过将反投影的点云与使用 [82] 中代码获得的 2D 语义标签结合得到的。
- LMSCNet [55]:我们使用了 LMSCNet 的官方实现。对于 LMSCNet,输入的占用网格是通过对反投影点云进行离散化得到的。
A.2 MonoScene
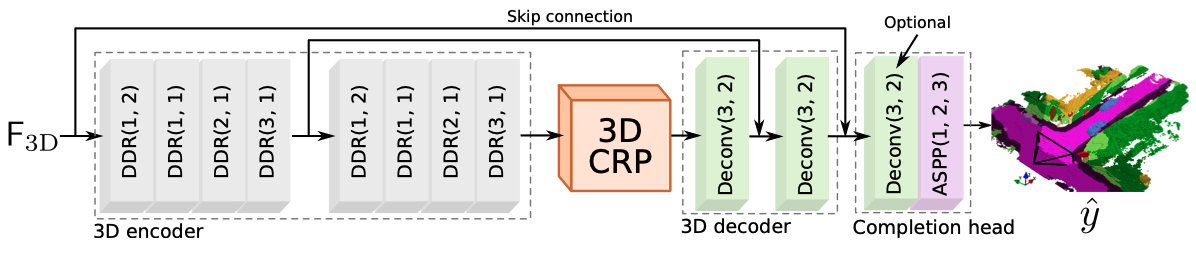
图 10. MonoScene 3D 网络架构。 3D UNet 使用 2 层下采样,每层包含 4 个 DDR 块 [40],以及 2 层上采样,每层使用反卷积。完成头模块包含一个 ASPP,其扩张率为 (1, 2, 3),用于收集多尺度特征,以及一个可选的反卷积层,用于达到输出尺寸——仅在 SemanticKITTI 数据集中使用。
图 10 详细展示了我们的 3D 网络架构。类似于 3DSketch [9],我们采用了 DDR [40] 作为基本构建块,以实现较大的感受野和较低的内存成本。3D 编码器包含 2 层,每层通过下采样将尺寸减半,并包含 4 个 DDR 块。3D 解码器包含两个反卷积层,每层将尺寸加倍。类似于其他方法 [55],完成头包含一个 ASPP,其扩张率分别为 (1, 2, 3),用于收集多尺度特征,并且在 SemanticKITTI 中使用了一个可选的反卷积层来达到输出尺寸。
对于训练,MonoScene 在 NYUv2 [58] 上使用 2 个 V100 32GB GPU(每个 GPU 处理 2 个项目)训练了 7 个小时,在 SemanticKITTI [3] 上使用 4 个 V100 32GB GPU(每个 GPU 处理 1 个项目)训练了 28 个小时。
B. 附加结果
B.1 SemanticKITTI
- 定量性能:我们在表 6 中报告了验证集上的性能。与主文中表 1b 的测试集性能相比,我们注意到 MonoScene 的泛化能力优于 JS3C-Net和 AICNet,因为验证集和测试集之间的差距更小(-0.42,而 JS3C-Net和 AICNet的差距分别为 -1.34 和 -1.22)。我们还在表 7 中报告了完整的 SemanticKITTI 官方基准测试结果(即隐藏测试集),尽管 MonoScene 仅使用 RGB 图像,但它仍然优于一些使用 3D 输入的 SSC 基线方法。
- 定性性能:在图 11 中,我们还提供了更多的定性结果。与所有基线方法相比,MonoScene 更好地捕捉了景观和物体(例如第 3-9 行的汽车;第 6、10 行的行人;第 3、5 行的交通标志)。然而,它仍然在预测细小物体(例如第 1 行的树干;第 3 行的行人;第 2、6 行的交通标志)方面存在困难,难以区分远处连续的汽车(例如第 5、7、8 行),并且在推断非常复杂、高度混乱的场景时表现不佳(例如第 9、10 行)。
- 评估范围:表 8 报告了仅考虑视野内(in-FOV)、视野外(out-FOV)或整个场景(Whole Scene)时的性能,如主文中所述。与整个场景相比,视野内的性能更高,因为它仅考虑了可见表面,而视野外的性能显著较低,因为图像并未观察到该部分。
B.2 NYUv2
我们在图 12 中展示了更多的定性结果。总体而言,MonoScene 在预测场景布局和物体几何结构方面表现更好,尤其是在第 1-4 行、第 6 行和第 9 行中。然而,MonoScene 仍然会在复杂场景(例如第 1、4、6 行的书架)或罕见物体(第 8 行的跑步机)上出现误预测。有时,它还会混淆语义相似的类别(例如第 6、8 行的窗户/物体;第 1、5 行的床/物体;第 1、2 行的家具/桌子),这主要是由于室内场景的高变异性,即同一类别中的物体可能具有完全不同的外观、姿态和位置,例如床(第 1、5-7、9 行)和沙发(第 2-4 行)。
B.3 泛化能力
图 13 展示了在不同相机设置的数据集上进行测试时,MonoScene 的预测结果。随着相机设置与训练集的偏离,结果中的失真现象逐渐增加。此外,领域差距(例如城市、乡村等)也起到了重要作用。由于 MonoScene 是在德国中型城市卡尔斯鲁厄的住宅场景和狭窄街道上进行训练的,因此与 KITTI-360 的领域差距较小。而 nuScenes 和 Cityscapes 的结果则受到了相机设置变化和大型城市场景(例如斯图加特 - Cityscapes;新加坡、波士顿 - nuScenes)的影响,这些城市街道更宽、更密集,且具有不同的景观。