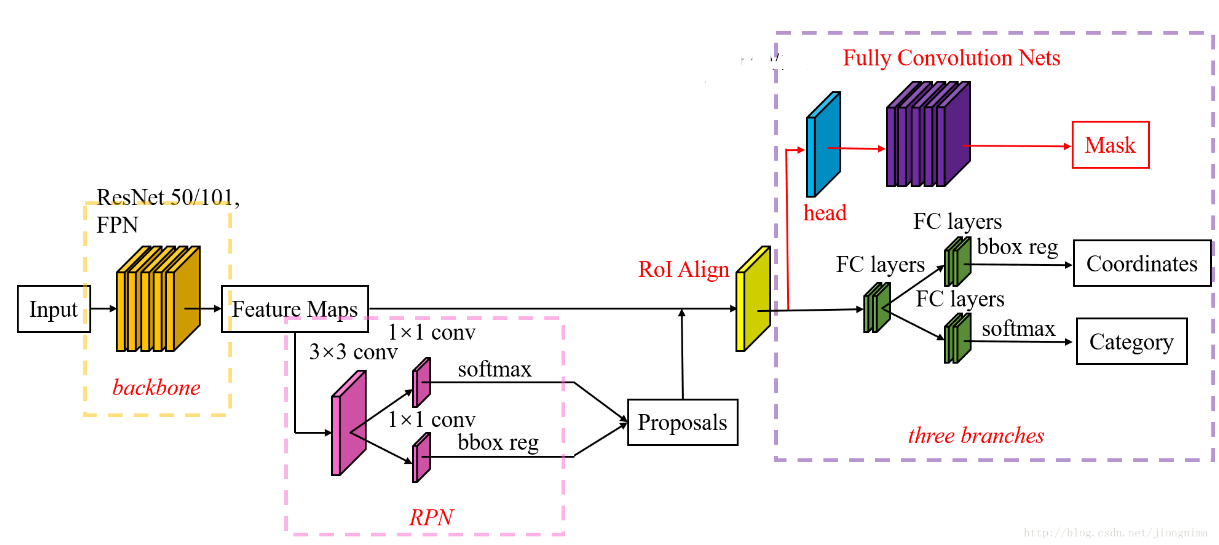
实例分割
实例分割
一种分类方法:
- Top-Down
首先通过目标检测的方法找出实例所在的区域(bounding box),再在检测框内进行语义分割,每个分割结果都作为一个不同的实例输出**。这类方法的代表作就是大名鼎鼎的Mask R-CNN**了。
- Bottom-Up
自下而上的实例分割方法的思路是:首先进行像素级别的语义分割,再通过聚类、度量学习等手段区分不同的实例。
- One stage
有两种思路:
- 一种是受one-stage, anchot-based 检测模型如YOLO,RetinaNet启发,代表作有YOLACT和SOLO;
- 一种是受anchor-free检测模型如 FCOS 启发,代表作有PolarMask和AdaptIS。
R-CNN
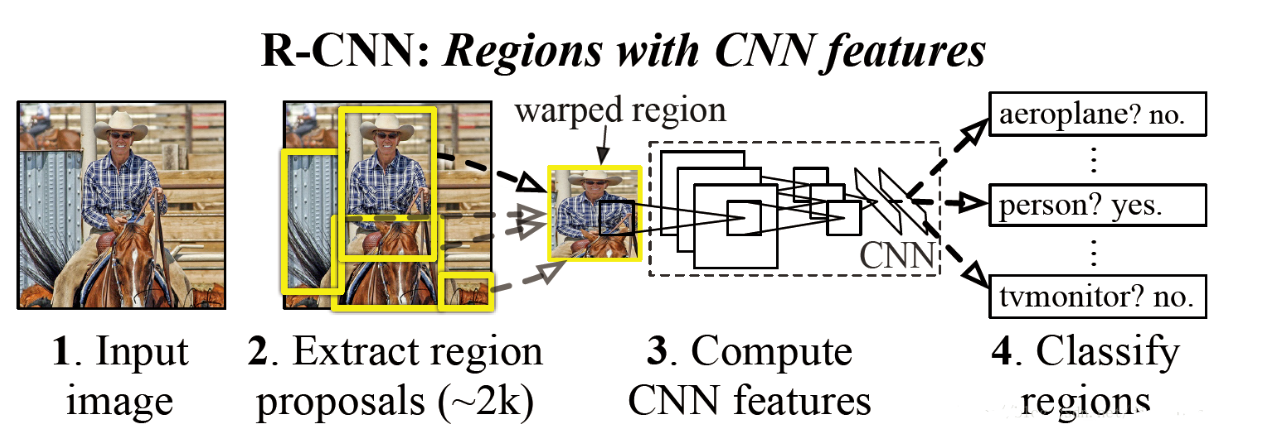
流程:
首先模型输入为一张图片,然后在图片上提出了约2000个待检测区域(SS算法),
然后这2000个待检测区域一个一个地(串联方式)通过卷积神经网络提取特征,
这些被提取的特征通过一个支持向量机(SVM)进行分类,得到物体的类别,并通过一个bounding box regression调整目标包围框的大小。
贡献:
- 使用了卷积神经网络进行特征提取。
- 使用bounding box regression进行目标包围框的修正。
问题:
- 耗时的 selective search,对一帧图像,需要花费2s。
- 耗时的串行式CNN前向传播,对于每一个RoI,都需要经过一个AlexNet提特征,为所有的RoI提特征大约花费47s。
- 三个模块是分别训练的,并且在训练的时候,对于存储空间的消耗很大。
Selective Search
选择性搜索算法(Selective Search)超详解(通俗易懂版)_迪菲赫尔曼的博客-CSDN博客
第三十三节,目标检测之选择性搜索-Selective Search - 大奥特曼打小怪兽 - 博客园 (cnblogs.com)
Fast R-CNN
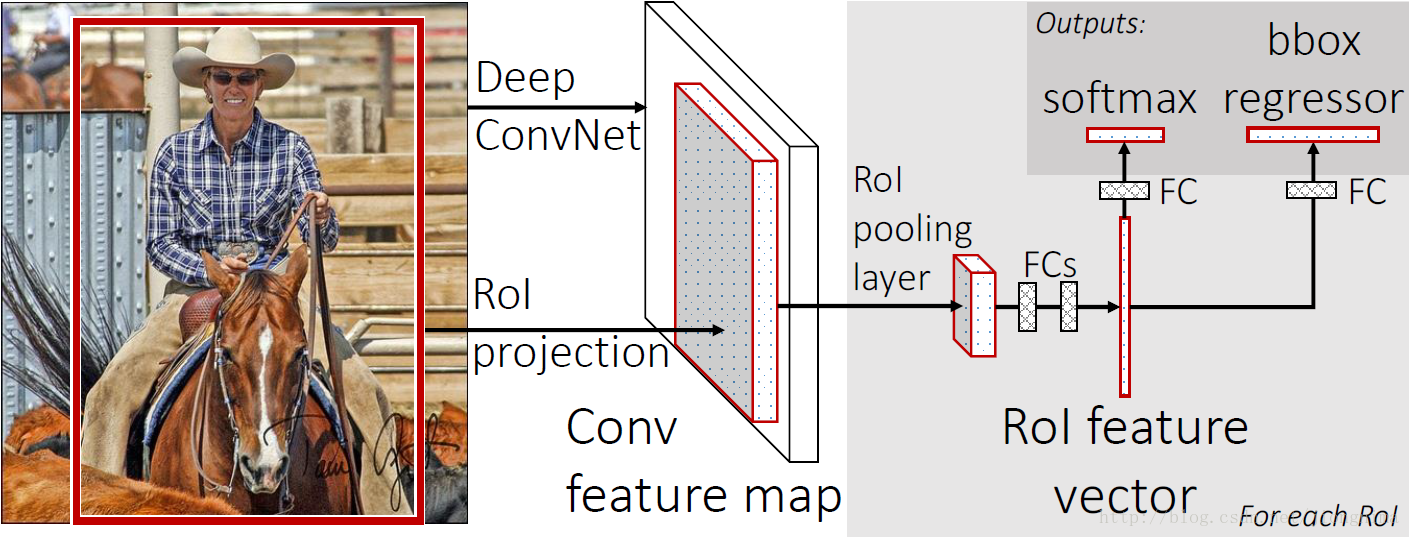
流程
- 首先还是采用selective search提取2000个候选框,
- 然后,使用一个神经网络对全图进行特征提取。
- 使用一个RoI Pooling Layer在全图特征上摘取每一个RoI对应的特征,再通过全连接层(FC Layer)进行分类与包围框的修正。
贡献
Fast R-CNN的贡献可以主要分为两个方面:
取代R-CNN的串行特征提取方式,直接采用一个神经网络对全图提取特征(这也是为什么需要RoI Pooling的原因)。
除了selective search,其他部分都可以合在一起训练。
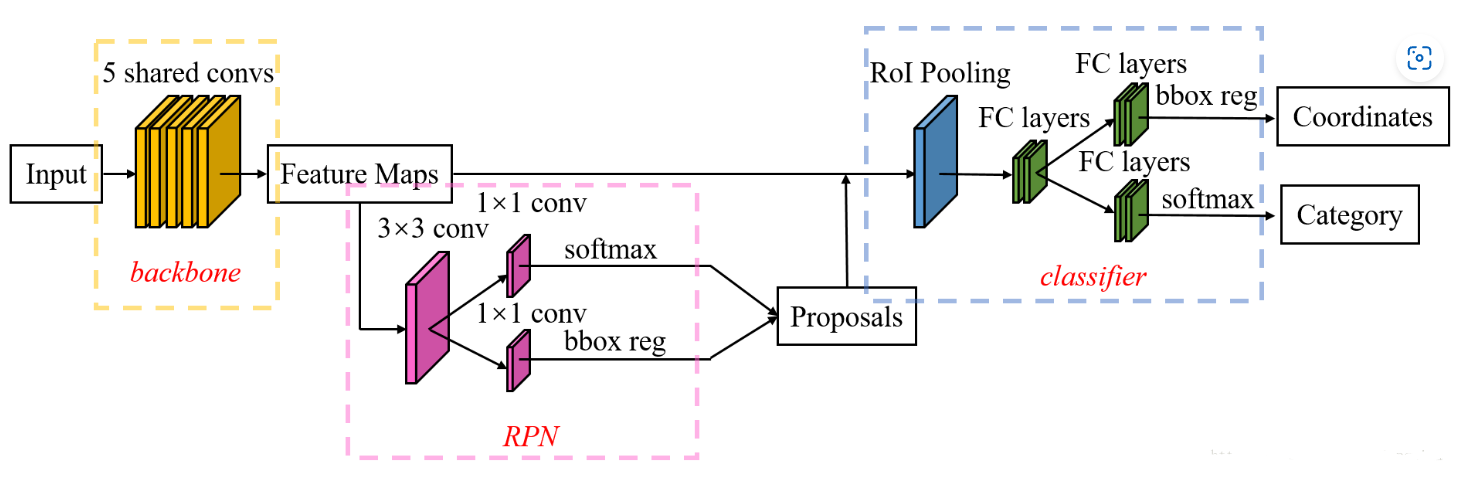
Faster R-CNN
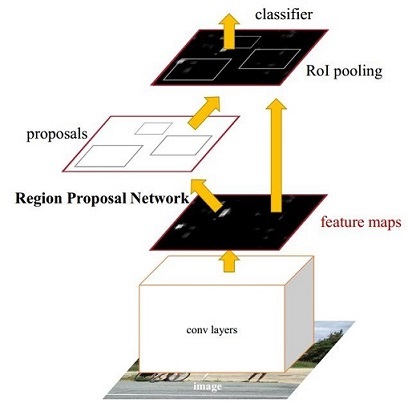
- 首先使用共享的卷积层为全图提取特征,
- 然后将得到的feature maps送入RPN,RPN生成待检测框(指定RoI的位置)并对RoI的包围框进行第一次修正。
- 之后就是Fast R-CNN的架构了
RoI Pooling Layer 根据 RPN 的输出在feature map上面选取每个 RoI 对应的特征,并将维度置为定值。最后,使用全连接层(FC Layer)对框进行分类,并且进行目标包围框的第二次修正。
尤其注意的是,Faster R-CNN真正实现了端到端的训练(end-to-end training)。
Region Proposal Network
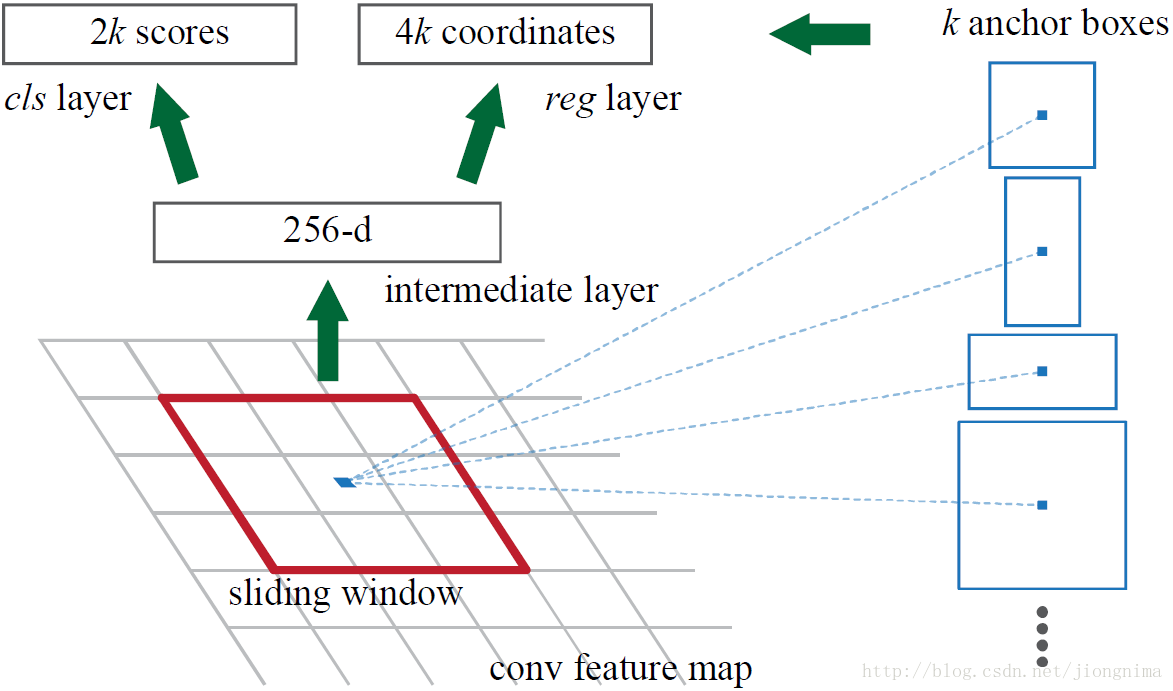
RPN依靠一个在共享特征图上滑动的窗口,为每个位置生成9种预先设置好长宽比与面积的目标框(文中叫做anchor)。这9种初始anchor包含三种面积(128×128,256×256,512×512),每种面积又包含三种长宽比(1:1,1:2,2:1)。
anchor:实际上就是一组由rpn/generate_anchors.py生成的矩形
- 每个点上有k个anchor(默认k=9),而每个anhcor要分positive和negative,所以每个点由256d feature转化为cls=2•k scores;而每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4•k coordinates
- 全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练
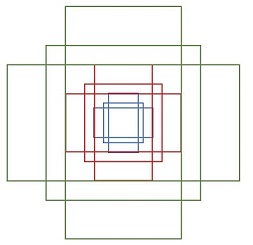
cls layer
如果一个anchor与ground truth的IoU在0.7以上,那这个anchor就算前景(positive)。类似地,如果这个anchor与ground truth的IoU在0.3以下,那么这个anchor就算背景(negative)。
reg layer
边框修正主要由4个值完成,tx,ty,th,tw。这四个值的意思是修正后的框在anchor的x和y方向上做出平移(由tx和ty决定),并且长宽各自放大一定的倍数(由th和ty决定)。
Smooth L1 loss
Classifier
RoI Pooling
特征被共享卷积层一次性提取。因此,对于每个RoI而言,需要从共享卷积层上摘取对应的特征,并且送入全连接层进行分类。因此,RoI Pooling主要做了两件事,
- 第一件是为每个RoI选取对应的特征,
- 第二件事是为了满足全连接层的输入需求,将每个RoI对应的特征的维度转化成某个定值。
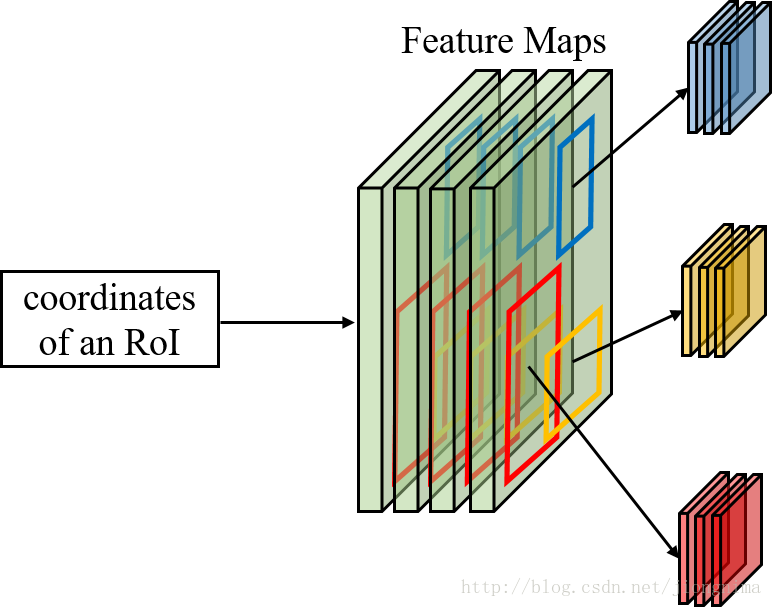
分类和边框修正
在 RoI Pooling 后,分类器主要是分这个提取的RoI具体是什么类别(人,车,马等等),一共C+1类(包含一类背景)。RoI边框修正和RPN中的anchor边框修正原理一样,同样也是SmoothL1 Loss,
RoI边框修正也是对于非背景的RoI进行修正,对于类别标签为背景的RoI,则不进行RoI边框修正的参数训练。
推理
推理和训练过程类似
首先通过RPN生成约20000个anchor(40×60×9)通过RPN。
对20000个anchor进行第一次边框修正,得到修订边框后的proposal。
对超过图像边界的proposal的边进行clip,使得该proposal不超过图像范围。
忽略掉长或者宽太小的proposal。
将所有proposal按照前景分数从高到低排序,选取前6000个proposal。
使用阈值为0.7的NMS算法排除掉重叠的proposal。
针对上一步剩下的proposal,选取前300个proposal进行分类和第二次边框修正
Mask R-CNN
问题
问题1:从输入图上的RoI到特征图上的RoI feature,RoI Pooling是直接通过四舍五入取整得到的结果。
RoI Pooling过后的得到的输出可能和原图像上的RoI对不上,如下图所示:

右图中蓝色部分表示包含了轿车主体的的信息的方格,RoI Pooling Layer的四舍五入取整操作导致其进行了偏移。
问题2:再将每个RoI对应的特征转化为固定大小的维度时,又采用了取整操作。在这里笔者举例讲解一下RoI Pooling的操作:
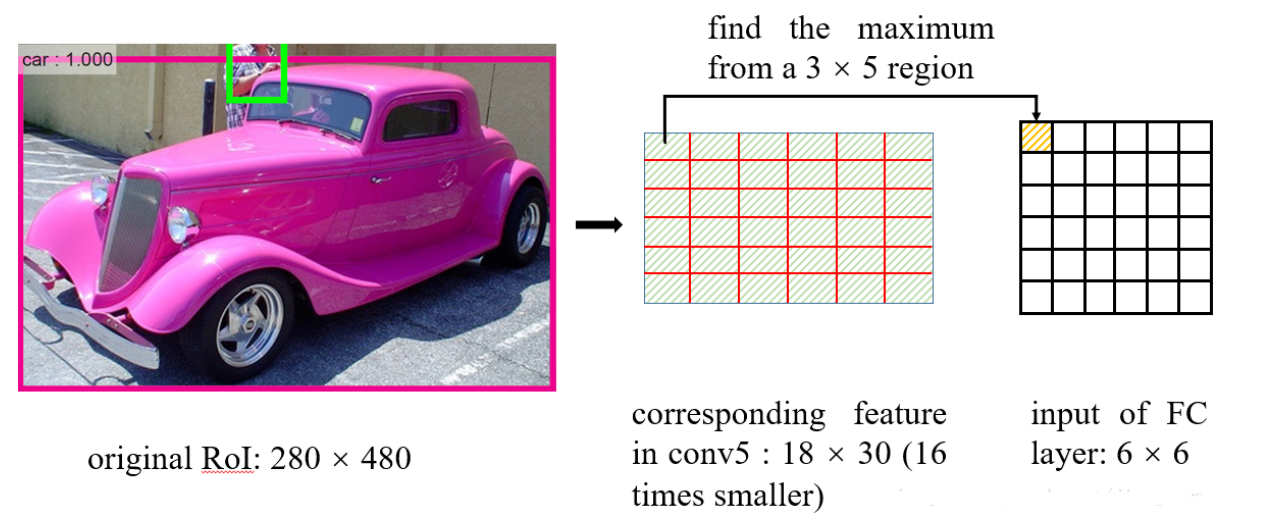
在从RoI得到对应的特征图时,进行了问题1描述的取整,在得到特征图后,如何得到一个6×6的全连接层的输入呢?RoI Pooling这样做:将RoI对应的特征图分成6×6块,然后直接从每块中找到最大值。在上图中的例子中,比如原图上的的RoI大小是280×480,得到对应的特征图是18×30。将特征图分成6块,每块大小是3×5,然后在每一块中分别选择最大值放入6×6的对应区域中。在将特征图分块的时候,又用到了取整
- 这种取整操作(在Mask R-CNN中被称为quantization)对RoI分类影响不大,可是对逐像素的预测目标是有害的,因为对每个RoI取得的特征并没有与RoI对齐。因此,Mask R-CNN对RoI Pooling做了改进并提出了RoI Align。
- RoI Align的主要创新点是,针对问题1,不再进行取整操作。针对问题2,使用双线性插值来更精确地找到每个块对应的特征。
- 总的来说,RoI Align的作用主要就是剔除了RoI Pooling的取整操作,并且使得为每个RoI取得的特征能够更好地对齐原图上的RoI区域。