
InternImage
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
单位:上海AI Lab, 清华, 南大, 港中文
代码:https://github.com/OpenGVLab/InternImage
论文:https://arxiv.org/abs/2211.05778
Deformable Convolutional Networks
[论文速览]Deformable Convolutional Networks; DCN[1703.06211]
ICCV 2017 Microsoft Research Asia; DCN
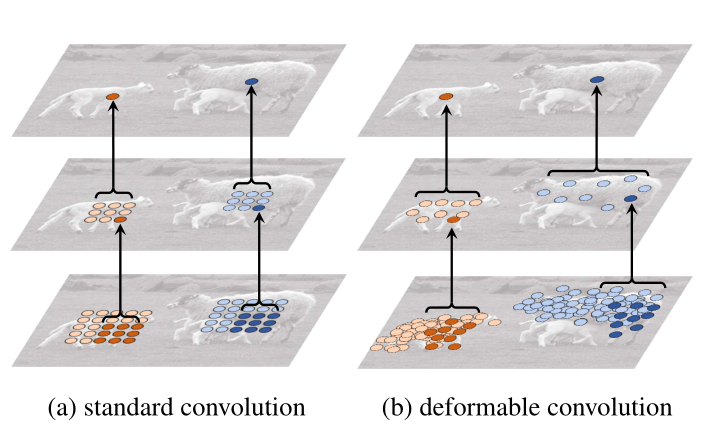
Illustration of the fixed receptive field in standard convolution (a) and the adaptive receptive field in deformable convolution (b), using two layers. Top: two activation units on the top feature map, on two objects of different scales and shapes. The activation is from a 3 × 3 filter. Middle: the sampling locations of the 3 × 3 filter on the preceding feature map. Another two activation units are highlighted. Bottom: the sampling locations of two levels of 3 × 3 filters on the preceding feature map. The highlighted locations correspond to the highlighted units above.
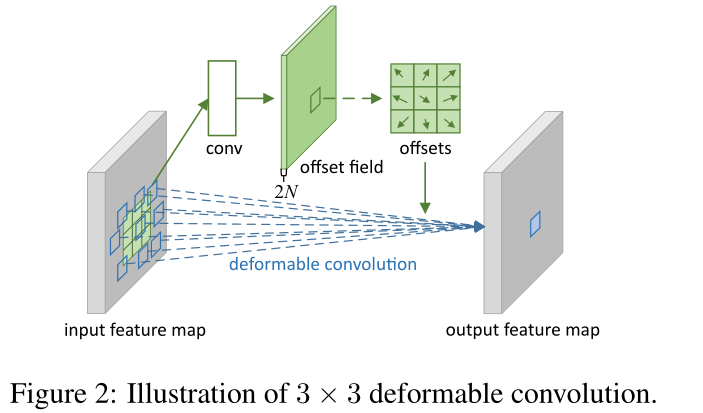
Deformable Convolution
Regular conv
Deformable conv
- 双线性插值
- 通过一个 conv 层计算如何 offset
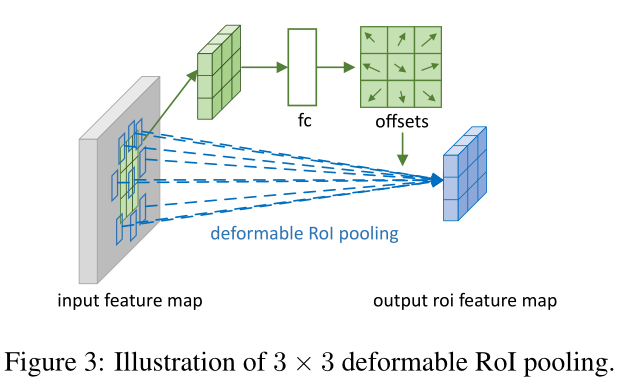
Defomable RoI Pooling
RoI Pooling (average)
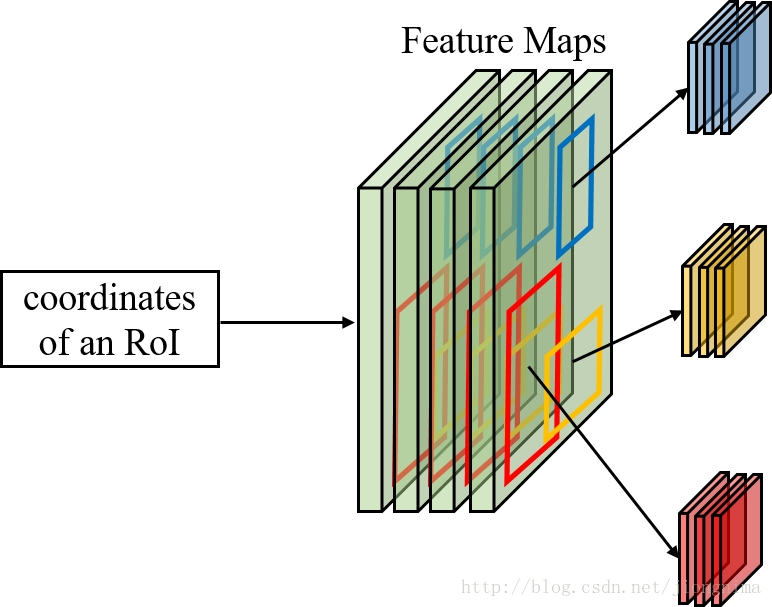
首先第一个问题是为什么需要RoI Pooling?答案是在Fast R-CNN中,特征被共享卷积层一次性提取。因此,对于每个RoI而言,需要从共享卷积层上摘取对应的特征,并且送入全连接层进行分类。因此,RoI Pooling主要做了两件事,第一件是为每个RoI选取对应的特征,第二件事是为了满足全连接层的输入需求,将每个RoI对应的特征的维度转化成某个定值。RoI Pooling示意图如下所示:
实例分割模型Mask R-CNN详解:从R-CNN,Fast R-CNN,Faster R-CNN再到Mask R-CNN_
Given the input feature map and a RoI of size and top-left corner RoI pooling divides the RoI into ( is a free parameter) bins and outputs a feature map .
For -th bin (),
其中 是 bin 中像素的数量
Position-Sensitive Roi Pooling
R-FCN:Object Detection via Region-based Fully Convolutional Networks
NIPS 2016;
基于区域的全卷积神经网络
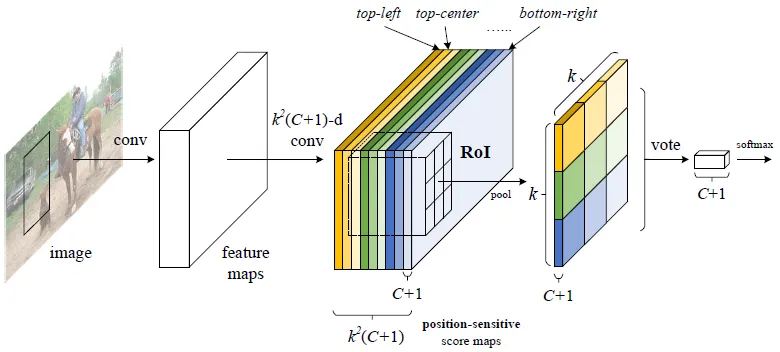
Visualization


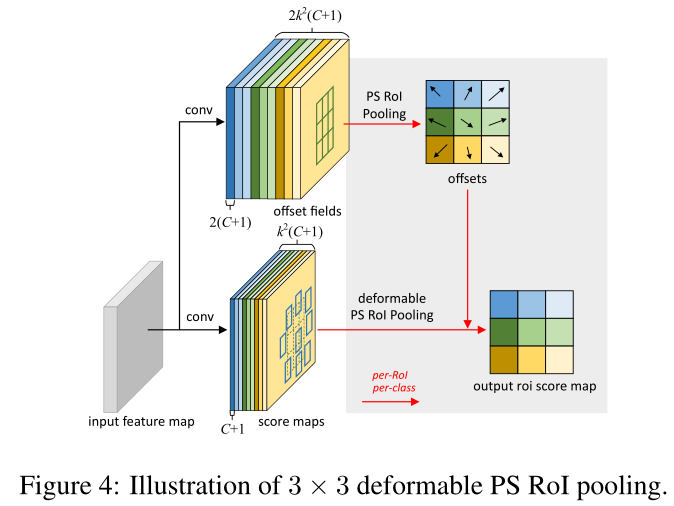
Deformable ConvNets v2: More Deformable, Better Results
论文阅读-可变形卷积v2: More Deformable, Better Results - 知乎 (zhihu.com)
可变形卷积能够很好地学习到发生形变的物体,但是论文观察到当尽管比普通卷积网络能够更适应物体形变,可变形卷积网络却可能扩展到感兴趣区域之外从而使得不相关的区域影响网络的性能。
- 更多的可变形卷积层
- V1 仅在最后一个stage加入可变卷积
- 调节能力,即学习偏移的同时还会加入每一个采样点的权重
DCN v3
COCO新纪录65.4mAP!InternImage:注入新机制,扩展DCNv3,探索视觉大模型 - 知乎 (zhihu.com)
- 提出一种新的大尺度CNN基础模型InternImage,也是首个参数达1B、训练数据达400M并取得与ViT相当、甚至更优的CNN方案。这说明:对于大尺度模型研究,卷积模型同样是一个值得探索的方向。
- 通过将长程依赖、自适应空域聚合引入到DCNv3,作者成功的对CNN进行了大尺度扩展,同时还对模块定制化、堆叠规则以及缩放策略进行了探索。
- 图像分类、目标检测、语义分割以及实例分割等任务实验结果验证了所提方案的有效性。值得一提的是:InternImage-B仅需ImageNet-1K训练即可取得84.9%的精度(比其他CNN方案至少高出1.1%);当引入大尺度参数(1B)、大训练数据(427M)后,InternImage-H取得了89.2% ;在COCO任务上,InternImage-H以2.18B参数量取得了65.4%mAP指标,比SwinV2-G高出2.3%,同时参数量少27% 。
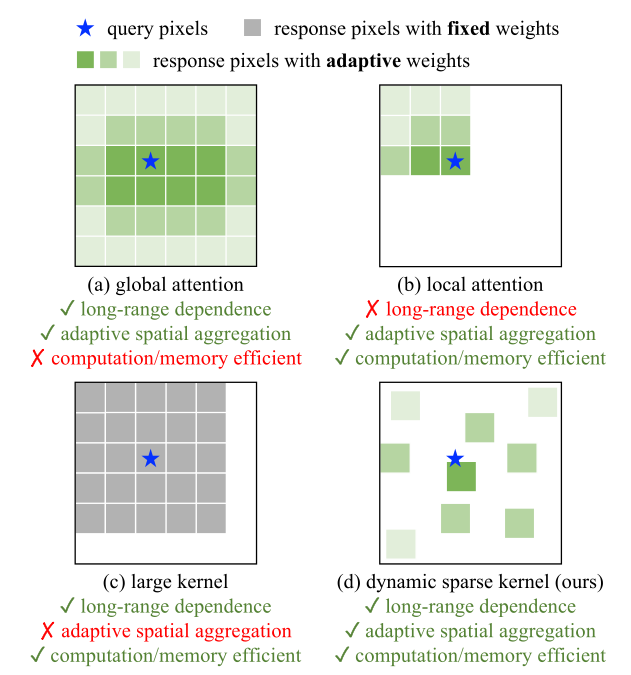
(a) 显示了多头自注意力 (MHSA) [1] 的全局聚合,其计算和内存成本在需要高分辨率输入的下游任务中非常昂贵。 (b) 将 MHSA 的范围限制在本地窗口以降低成本。 (c) 是具有非常大的内核的深度卷积,用于模拟长程依赖关系。 (d) 是可变形卷积,它与 MHSA 具有相似的有利特性,并且对于大规模模型来说足够有效。我们从它开始构建一个大规模的CNN。
当前主流的 Transformer 系列模型主要依靠多头自注意力机制实现大模型构建,其算子具有长距离依赖性,足以构建远距离特征间的连接关系,还具有空间的自适应聚合能力以实现构建像素级别的关系。
- 但这种全局的注意力机制其计算和存储需求量巨大,很难实现高效训练和快速收敛。
同样的,局部注意力机制缺乏远距离特征依赖。大核密集卷积由于没有空间聚合能力,而难以克服卷积天然的归纳偏置,不利于扩大模型。
因此,InternImage 通过设计动态稀疏卷积算子,达到实现全局注意力效果的同时不过多浪费计算和存储资源,实现高效训练。
研究者基于 DCNv2 算子,重新设计调整并提出 DCNv3 算子
DCNv2
其中 表示采样点总数, 枚举采样点。 表示第 k 个采样点的投影权重, 表示第$ k$ 个采样点的调制标量,通过 sigmoid 函数进行归一化。 表示预定义网格采样的第 个位置 与常规卷积中一样,$\Delta p_k $ 是对应于第 个网格采样位置的偏移量。从方程中我们可以看出,
- 对于长程依赖,采样偏移 是灵活的,能够与短程或长程特征交互;
- 对于自适应空间聚合,采样偏移 和调制标量 都是可学习的并且由输入 x 调节。由此可见,DCNv2 与 MHSA 具有相似的有利特性,这促使我们在此算子的基础上开发基于 CNN 的大规模基础模型。
DCNv3
在已有的实践中,DCNv2往往作为常规卷积的扩展,加载常规卷积的预训练权值后进行微调以达成更优性能。这种使用方式不适用于需要从头开始训练的大尺度视觉基础模型。为解决上述问题,作者对DCNv2进行了如下扩展改进:
- Sharing weights among convolutional neurons. 类似常规卷积, DCNv2的不同卷积单元具有独立的线性投影权值, 其参数量与内存复杂度与采样点成线性关系, 这无疑会大幅限制其在大尺度模 型方面的高效性。针对于此, 受启发于分离卷积, 作者将原始的卷积权值 调整为depthwise(对应位置感知调制因子 )与 point-wise(对应采样点间共享投影权值 ) 两部分。
- Introducing multi-group mechanism. 多组/头设计源于组卷积, 但在MHSA中得到广泛应用, 可用于在不同位置从不同表达子空间学习更丰富的信息。受此启发, 作者将空域聚合过程拆分为 组, 每组具有独立的采样偏移 、调制因子 , 促使不同组具有不同的空域聚合模式, 进而产生更强的特征表达能力。
- Normalizing modulation scalars along sampling points. DCNv2的调制因子通过Sigmoid进行归一化处理,尽管每个调制因子均在[0,1]范围内,但其和并不稳定,从0到K之间变化,这会导致不稳定的梯度。为消除该不稳定问题,作者将元素级的Sigmoid归一化调整为沿采样点的Softmax归一化。此时,调制因子的综合为1,这使得整个训练过程更为稳定。
G 表示聚合组的数量,对于第 g 个组,, 表示该组的位置无关投影权重,其中 表示组维度。 表示第 g 组中第 k 个采样点的调制标量,通过 softmax 函数沿维度 K 进行归一化。
表示切片的输入特征图。 是第g组中网格采样位置 对应的偏移量。
总而言之, DCNv3 作为 DCN系列的扩展具有以下几个特性:
- 该算子弥补了常规卷积在长程依赖与自适应空域聚合方面的不足;
- 相比MHSA与形变注意力,该算子集成了CNN的归纳偏置;
- 相比MHSA与重参数大核,受益于稀疏采样,该算子在计算量与内存方面更为高效。
构建模型
Basic Block 在模块层面,不同于传统CNN常用的BottleNeck,作者采用了ViT的基本模块:加持了更鲜艳的成分(如LN、FFN、GELU),见上图的基本模块示意图,即将ViT模块中的MHSA替换为了DCNv3。
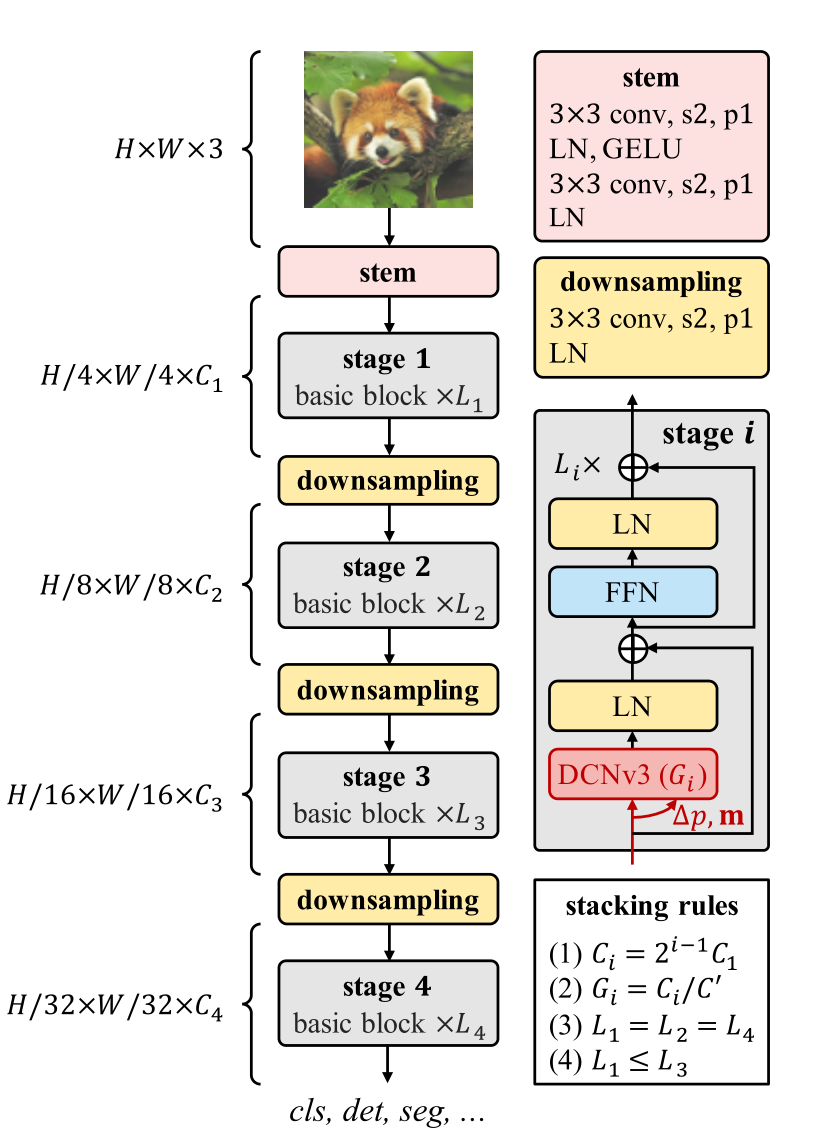
Stacking Rules
规定了一个堆叠规则,由四个超参控制搜索空间,
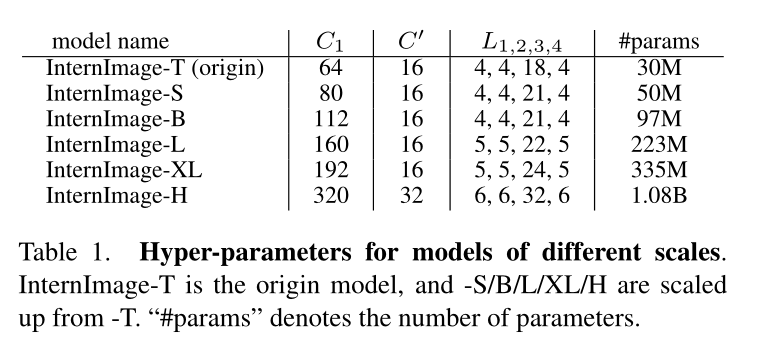
Scaling Rules
根据搜索到的最佳超参配置,由缩放规则对模型扩展
缩放规则由 Efficientnet 启发
Efficientnet: Rethinking model scaling for convolutional neural networks.
Result
![]()