
Swin Transformer
Abstract
这篇论文提出了一个新的 Vision Transformer 叫做 Swin Transformer,它可以被用来作为一个计算机视觉领域一个通用的骨干网络
- 之所以这么说,是因为ViT 在结论的部分指出他们只是做了分类任务,把下游任务比如说检测和分割留给以后的人去探索,所以说在 ViT 出来之后,大家虽然看到了Transformer在视觉领域的强大潜力,但是并不确定Transformer能不能把所有视觉的任务都做掉,所以 Swin Transformer这篇论文的研究动机就是想告诉大家用 Transformer没毛病,绝对能在方方面面上取代卷积神经网络,接下来大家都上 Transformer 就好了
但是直接把Transformer从 NLP 用到 Vision 是有一些挑战的,这个挑战主要来自于两个方面
- 一个就是尺度上的问题。因为比如说现在有一张街景的图片,里面有很多车和行人,里面的物体都大大小小,那这时候代表同样一个语义的词,比如说行人或者汽车就有非常不同的尺寸,这种现象在 NLP 中就没有
- 另外一个挑战是图像的 resolution太大了,如果要以像素点作为基本单位的话,序列的长度就变得高不可攀,所以说之前的工作要么就是用后续的特征图来当做Transformer的输入,要么就是把图片打成 patch 减少这个图片的 resolution,要么就是把图片画成一个一个的小窗口,然后在窗口里面去做自注意力,所有的这些方法都是为了减少序列长度
基于这两个挑战,本文的作者就提出了 hierarchical Transformer,它的特征是通过一种叫做移动窗口的方式学来的
- 移动窗口的好处:不仅带来了更大的效率,因为跟之前的工作一样,现在自注意力是在窗口内算的,所以这个序列的长度大大的降低了;同时通过 shifting 移动的这个操作,能够让相邻的两个窗口之间有了交互,所以上下层之间就可以有 cross-window connection,从而变相的达到了一种全局建模的能力
然后作者说这种层级式的结构不仅非常灵活,可以提供各个尺度的特征信息,同时因为自注意力是在小窗口之内算的,所以说它的计算复杂度是随着图像大小而线性增长,而不是平方级增长
这其实也为作者之后提出 Swin V2 铺平了道路,从而让他们可以在特别大的分辨率上去预训练模型
因为 Swin Transformer 拥有了像卷积神经网络一样分层的结构,有了这种多尺度的特征,所以它很容易使用到下游任务里
- 在密集预测型的任务上
Method
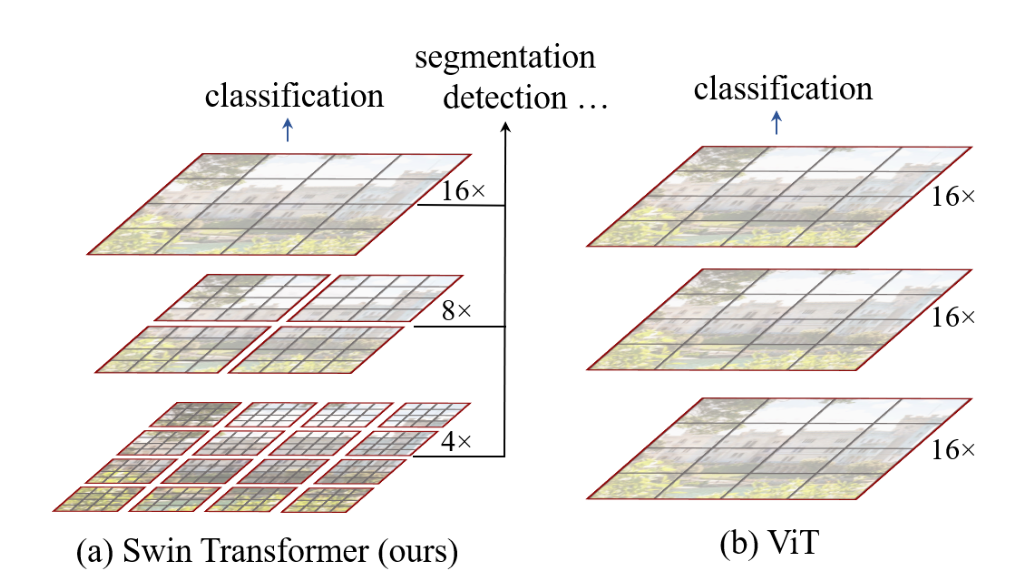
Figure 1. (a) The proposed Swin Transformer builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks.
(b) In contrast, previous vision Transformers [20] produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of selfattention globally.
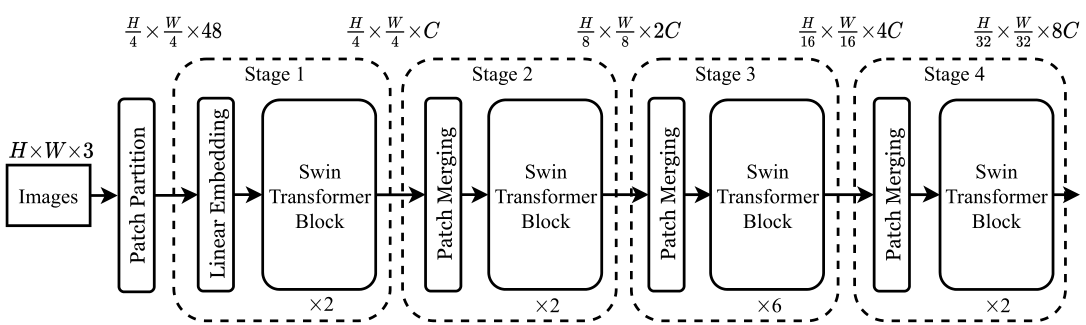
首先将图片输入到Patch Partition模块中进行分块,即每4x4相邻的像素为一个Patch,然后在channel方向展平(flatten)。假设输入的是RGB三通道图片,那么每个patch就有4x4=16个像素,然后每个像素有R、G、B三个值所以展平后是16x3=48,所以通过Patch Partition后图像shape由 [H, W, 3]变成了 [H/4, W/4, 48]。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 [H/4, W/4, 48]变成了 [H/4, W/4, C]。其实在源码中Patch Partition和Linear Embeding就是直接通过一个卷积层实现的,和之前Vision Transformer中讲的 Embedding层结构一模一样。
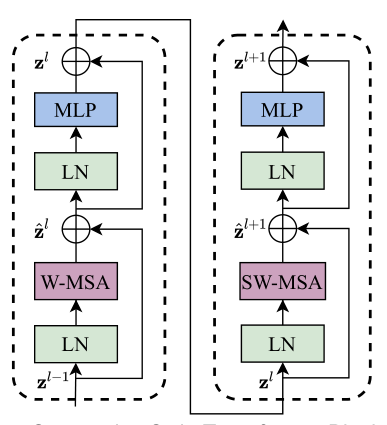
然后就是通过四个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样(后面会细讲)。然后都是重复堆叠Swin Transformer Block注意这里的Block其实有两种结构,如图(b)中所示,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构。而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构。所以你会发现堆叠Swin Transformer Block的次数都是偶数(因为成对使用)。
最后对于分类网络,后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出。图中没有画,但源码中是这样做的。
究动机就是想要有一个层级式的 Transformer,为了这个层级式,所以介绍了 Patch Merging 的操作,从而能像卷积神经网络一样把 Transformer 分成几个阶段,为了减少计算复杂度,争取能做视觉里密集预测的任务,所以又提出了基于窗口和移动窗口的自注意力方式,也就是连在一起的两个Transformer block,最后把这些部分加在一起,就是 Swin Transformer 的结构
Patch Embedding
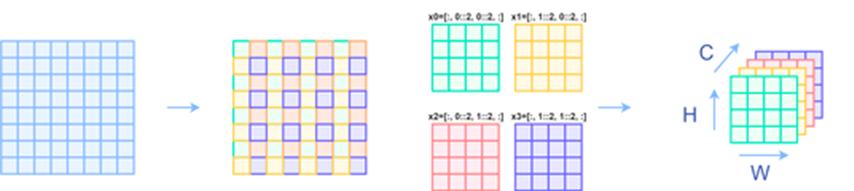
Patch Merging
W-MSA
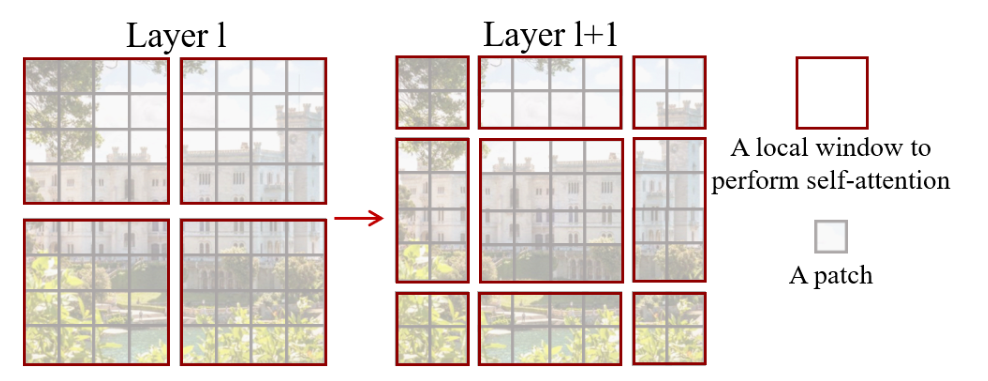
Figure 2. An illustration of the shifted window approach for computing self-attention in the proposed Swin Transformer architecture. In layer l (left), a regular window partitioning scheme is adopted, and self-attention is computed within each window. In the next layer l + 1 (right), the window partitioning is shifted, resulting in new windows. The self-attention computation in the new windows crosses the boundaries of the previous windows in layer l, providing connections among them.
Masked MSA
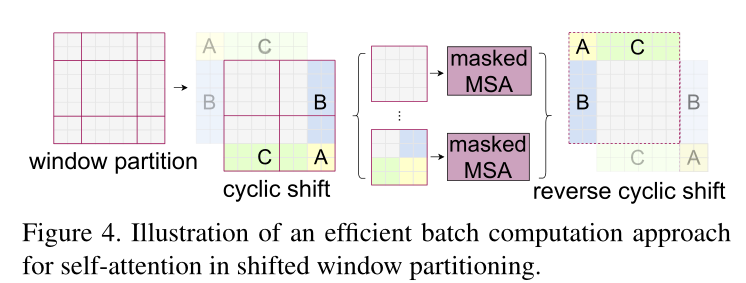
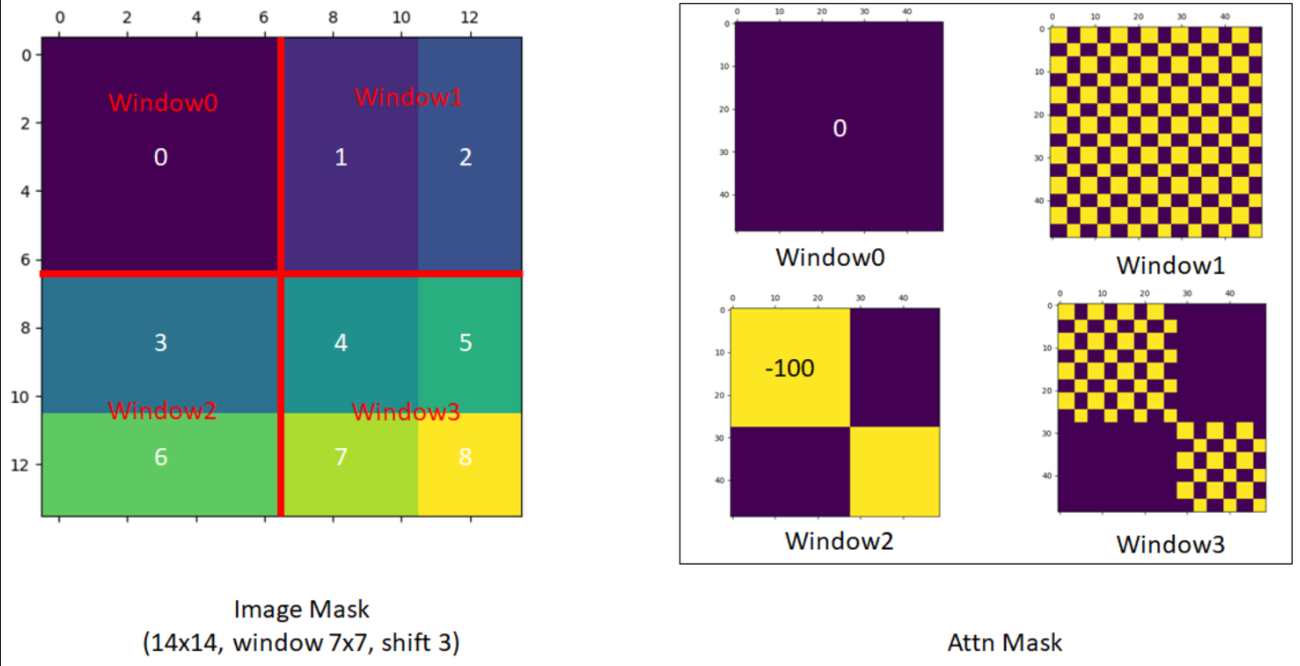
- 作者通过这种巧妙的循环位移的方式和巧妙设计的掩码模板,从而实现了只需要一次前向过程,就能把所有需要的自注意力值都算出来,而且只需要计算4个窗口,也就是说窗口的数量没有增加,计算复杂度也没有增加,非常高效的完成了这个任务