
SPFormer
SPFormer
Superpoint Transformer for 3D Scene Instance Segmentation | Papers With Code
Superpoint Transformer for 3D Scene Instance Segmentation
AAAI 2023
摘要
大多数现有方法通过扩展用于 3D 对象检测或 3D 语义分割的模型来实现 3D 实例分割。然而,这些非直接方法有两个缺点:
1)不精确的边界框或不令人满意的语义预测限制了整个 3D 实例分割框架的性能。
2)现有方法需要耗时的聚合中间步骤。
为了解决这些问题,本文提出了一种基于 Superpoint Transformer的新颖的端到端3D实例分割方法,命名为SPFormer。它将点云中的潜在特征分组为 Superpoint,并通过查询向量直接预测实例,而不依赖于对象检测或语义分割的结果。该框架的关键步骤是一种带有 Transformer 的新型查询解码器,它可以通过 superpoint 交叉注意机制捕获实例信息并生成实例的 Superpoint 掩码。通过基于 superpoint 掩码的二分匹配,SPFormer 可以实现无需中间聚合步骤的网络训练,从而加速网络。 ScanNetv2 和 S3DIS 基准的大量实验验证了我们的方法简洁而高效。值得注意的是,SPFormer 在 ScanNetv2 隐藏测试集上的 mAP 超过了最先进的方法 4.3%,同时保持了快速的推理速度(每帧 247 毫秒)
提出一个混合框架,避免缺点并同时从两种类型的方法中受益。两阶段端到端的 3D 实例分割方法:SPFormer。 SPFormer 将点云中自下而上的潜在特征分组为超级点,并通过查询向量作为自上而下的管道提出实例。
Method
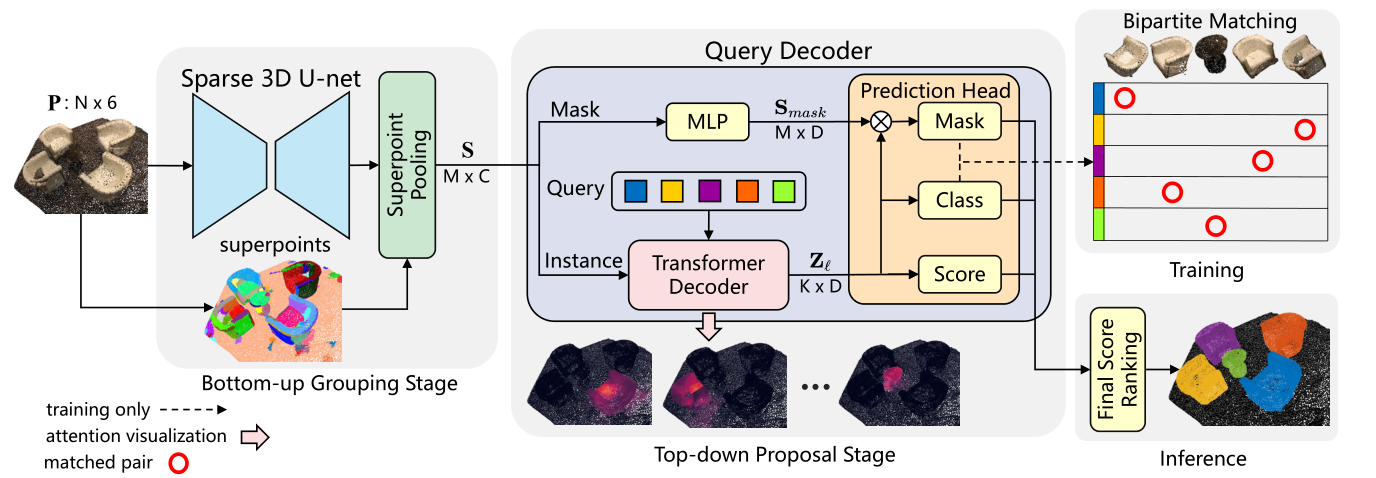
SPFormer的整体架构,包含两个阶段。在自下而上的分组阶段,稀疏3D U-net从输入点云P中提取逐点特征,然后超点池化层将同质相邻点分组为超点特征S。在自上而下的提议阶段,查询解码器为分为两个分支。实例分支通过 Transformer Decoder 获取查询向量特征 Z’。 mask 分支提取 mask-aware 特征 Smask。最后,预测头生成实例预测,并在训练/推理期间将它们输入到二分匹配或排名中。
Query Decoder
查询解码器由实例分支和掩码分支组成。
在掩模分支中,一个简单的多层感知器(MLP)旨在提取掩模感知特征。
实例分支由一系列 Transformer 解码器层组成。通过超点交叉注意力来解码可学习的查询向量。假设有 K 个可学习的查询向量。我们将每个 Transformer 解码器层的查询向量的特征预定义为 D 是嵌入维数
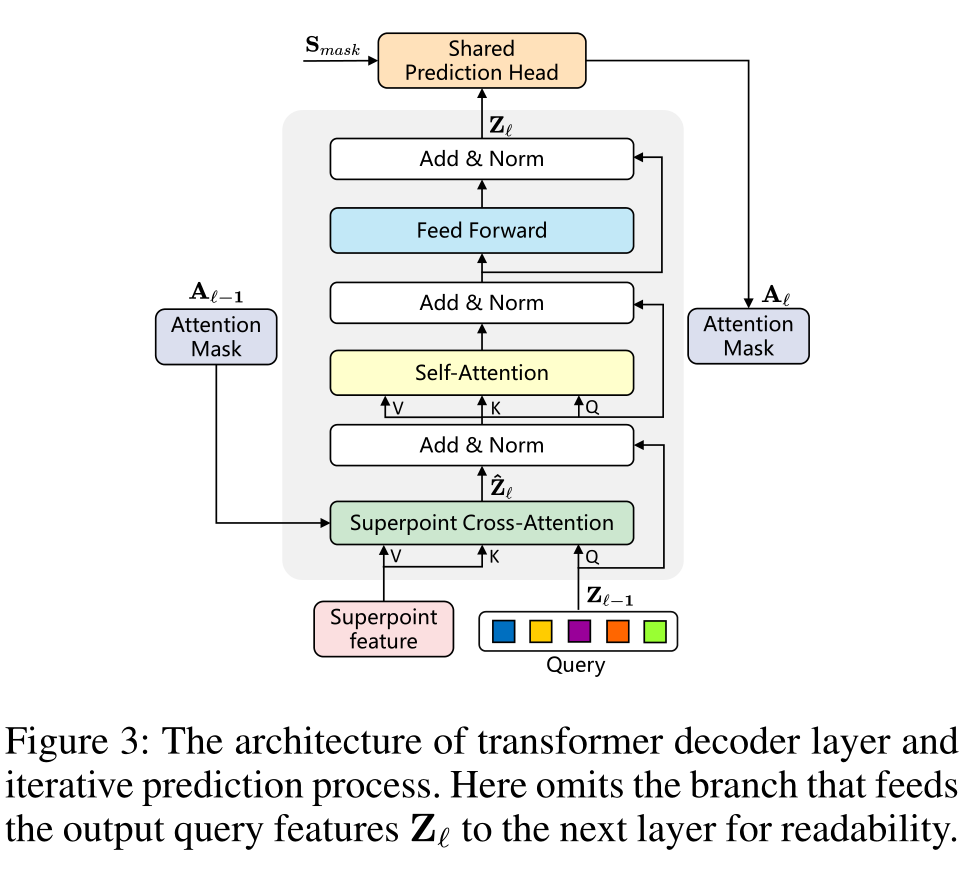
考虑到 Superpoint 的无序性和数量的不确定性,引入 Transformer 结构来处理变长输入。Superpoint 的潜在特征和可学习的查询向量被用作变压器解码器的输入。我们修改后的 Transformer 解码器层的详细架构如下图所示:
注意
In addition, because the input is the potential features of superpoints, we empirically remove position embedding.
《Masked-attention mask transformer for universal image segmentation》CVPR2022
查询向量在训练前随机初始化,每个点云的实例信息只能通过超点交叉注意力获得,因此,与标准解码器层相比,我们的 Transformer 解码器层交换了自注意力层和交叉注意力层的顺序
经过线性投影后的 Superpoint 特征 ,来自上一层的查询向量 通过 Superpoint 交叉注意机制捕获上下文信息,可以表示为:
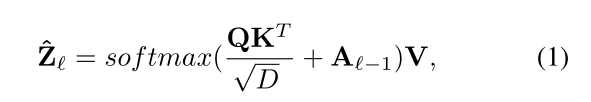
Shared Prediction Head
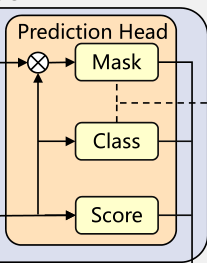
使用来自实例分支的查询向量 ,我们使用两个独立的 MLP 来预测每个查询向量的分类 ,并使用 IoU 感知分数分别。
此外,提案的排名深刻地影响实例分割结果,
- 而在实践中,由于一对一的匹配方式,大多数提案会被视为背景,这导致提案质量排名的错位。
- 因此,我们设计了一个分数分支来估计预测的超点mask和gt-mask的 IoU,以补偿未对准misalignment.。
- mask-aware features , directly multiply it by query vectors Z‘ followed a sigmoid function to generate superpoint masks prediction M‘