概览
多模态融合 Occ 预测
提示
L + C
| 项目 | 经典 LSS | LSSViewTransformer |
|---|---|---|
| 输出空间 | BEV 2D plane | Sparse 3D voxel grid |
| Lift-to-3D | Yes | Yes |
| Splat-to-BEV | Yes | ❌(而是聚合到3D voxel) |
| 用途 | BEV语义理解、检测等 | Occupancy 预测 |
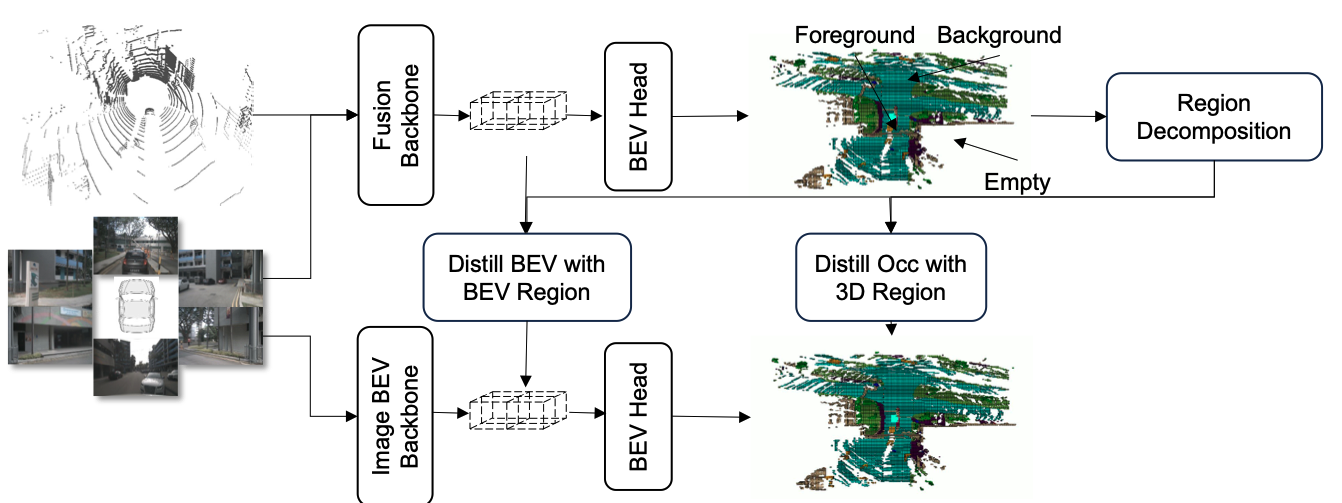
EFFOcc
2025
https://github.com/synsin0/EFFOcc
DAOcc
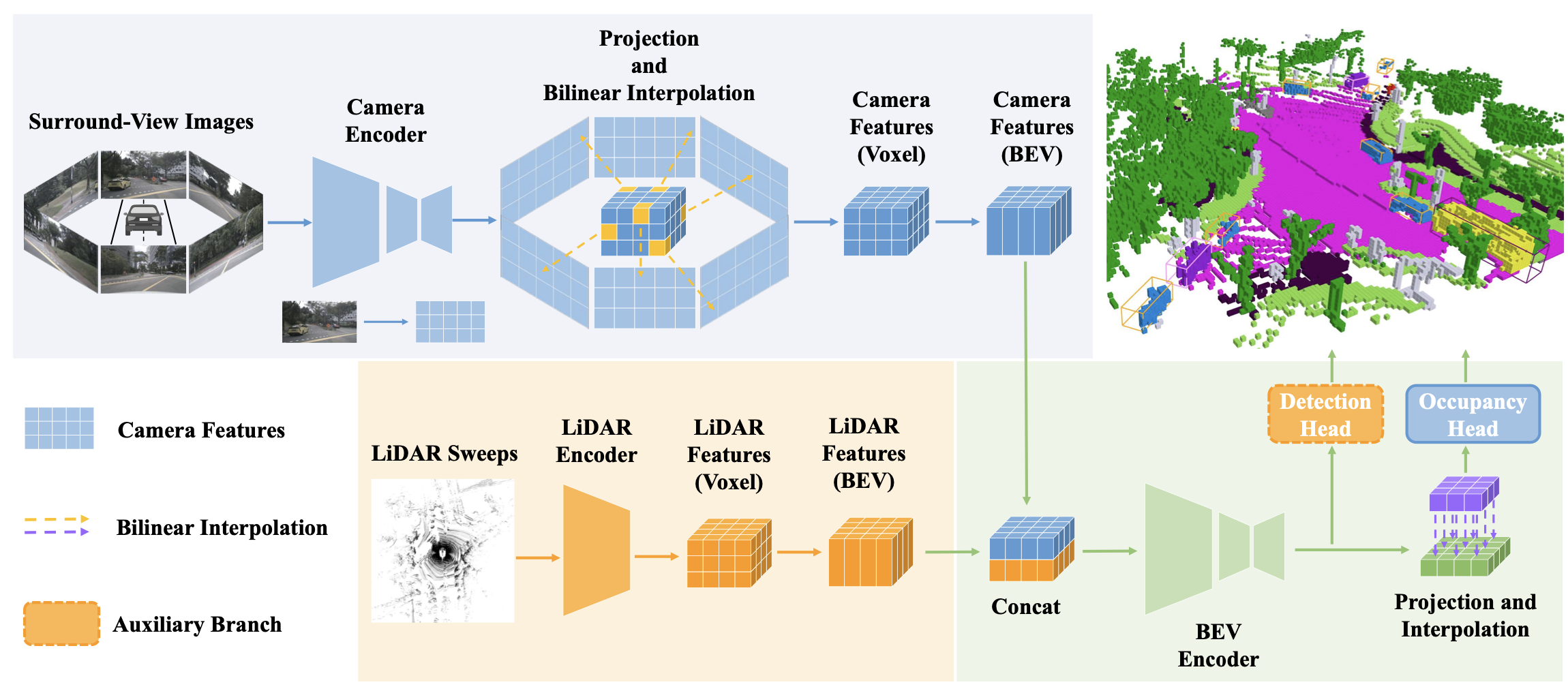
GaussianFormer3D
Multi-Modal Gaussian-based Semantic Occupancy Prediction with 3D Deformable Attention
https://arxiv.org/pdf/2505.10685
https://lunarlab-gatech.github.io/GaussianFormer3D/#
代码暂未开源
OCCFusion
Multi-Sensor Fusion Framework for 3D Semantic Occupancy Prediction
https://github.com/DanielMing123/OCCFusion
https://arxiv.org/pdf/2403.01644
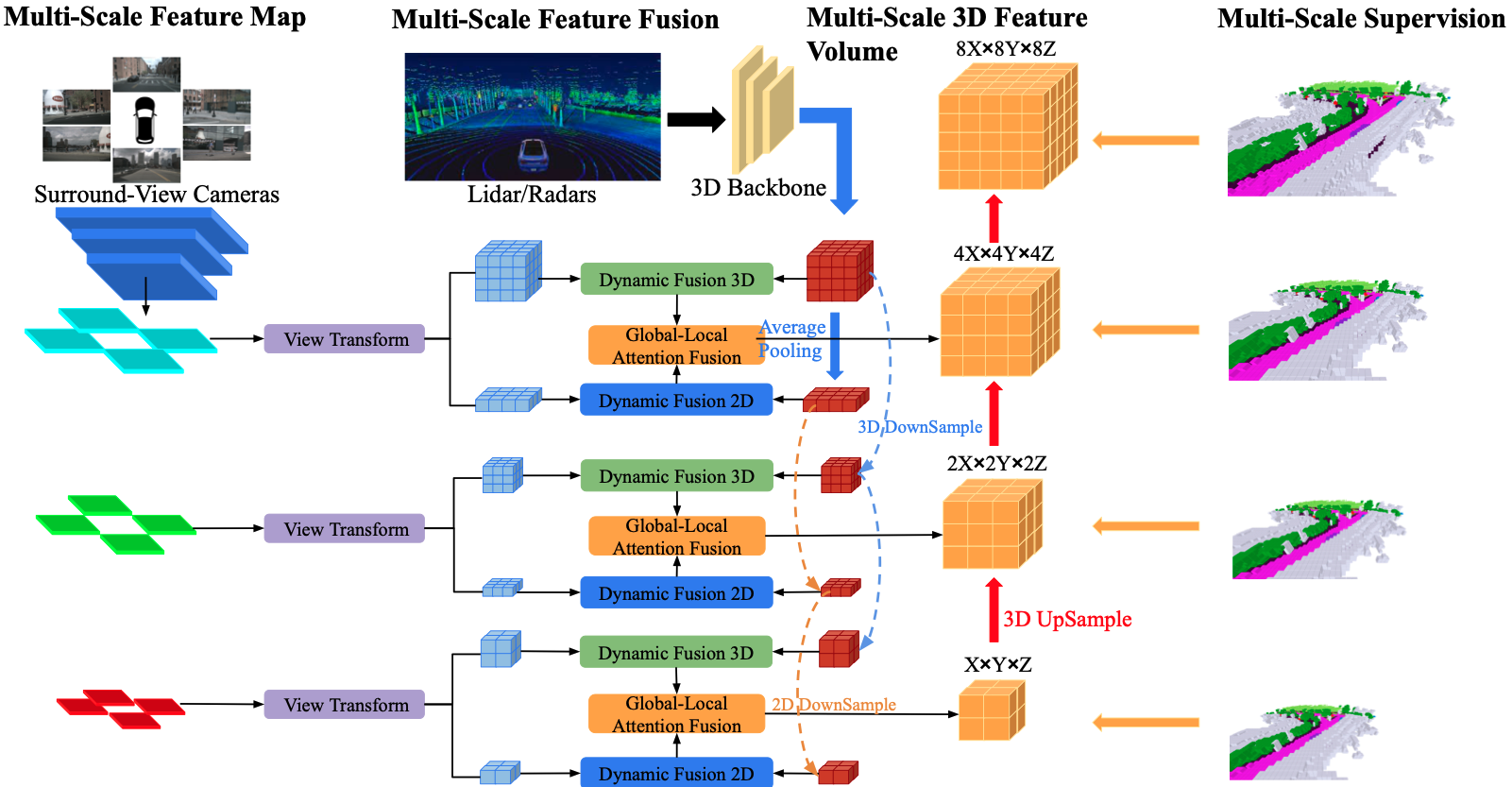
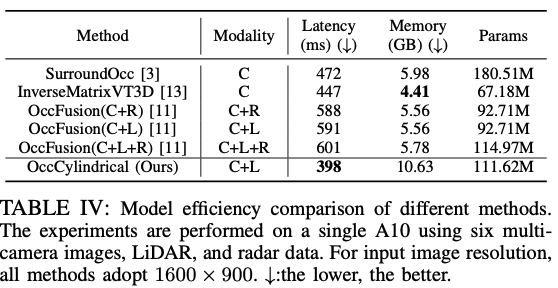
将环视图像输入 2D 主干网络以提取多尺度特征。
对每个尺度进行视图变换,以获得该层级的全局 BEV 特征和局部 3D 特征体积。
同时,将激光雷达和环视雷达生成的 3D 点云输入 3D 主干网络,以分别生成多尺度的局部 3D 特征体积和全局 BEV 特征。
将每个层级的合并后的全局 BEV 特征和局部 3D 特征体积输入全局 - 局部注意力融合模块,以生成每个尺度的最终 3D 体积。
对每个层级的 3D 体积进行上采样,并执行跳跃连接,同时采用多尺度监督机制。
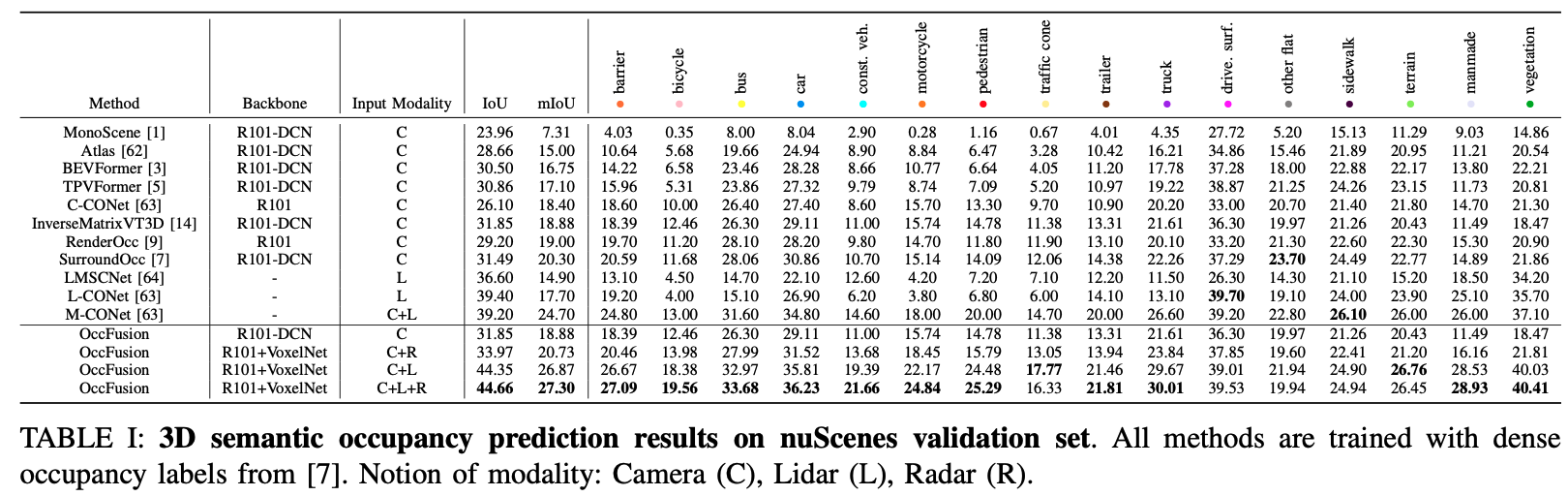
| 方法 | 延迟(ms)(↓) | 内存(GB)(↓) | 参数 |
|---|---|---|---|
| SurroundOcc [7] | 472 | 5.98 | 180.51M |
| InverseMatrixVT3D [14] | 447 | 4.41 | 67.18M |
| OccFusion(C+R) | 588 | 5.56 | 92.71M |
| OccFusion(C+L) | 591 | 5.56 | 92.71M |
| OccFusion(C+L+R) | 601 | 5.78 | 114.97M |
表 VI:不同方法的模型效率比较。实验在单个 A10 上进行,使用六个多相机图像、激光雷达和雷达数据。对于输入图像分辨率,所有方法均采用 1600×900。↓:越低越好。
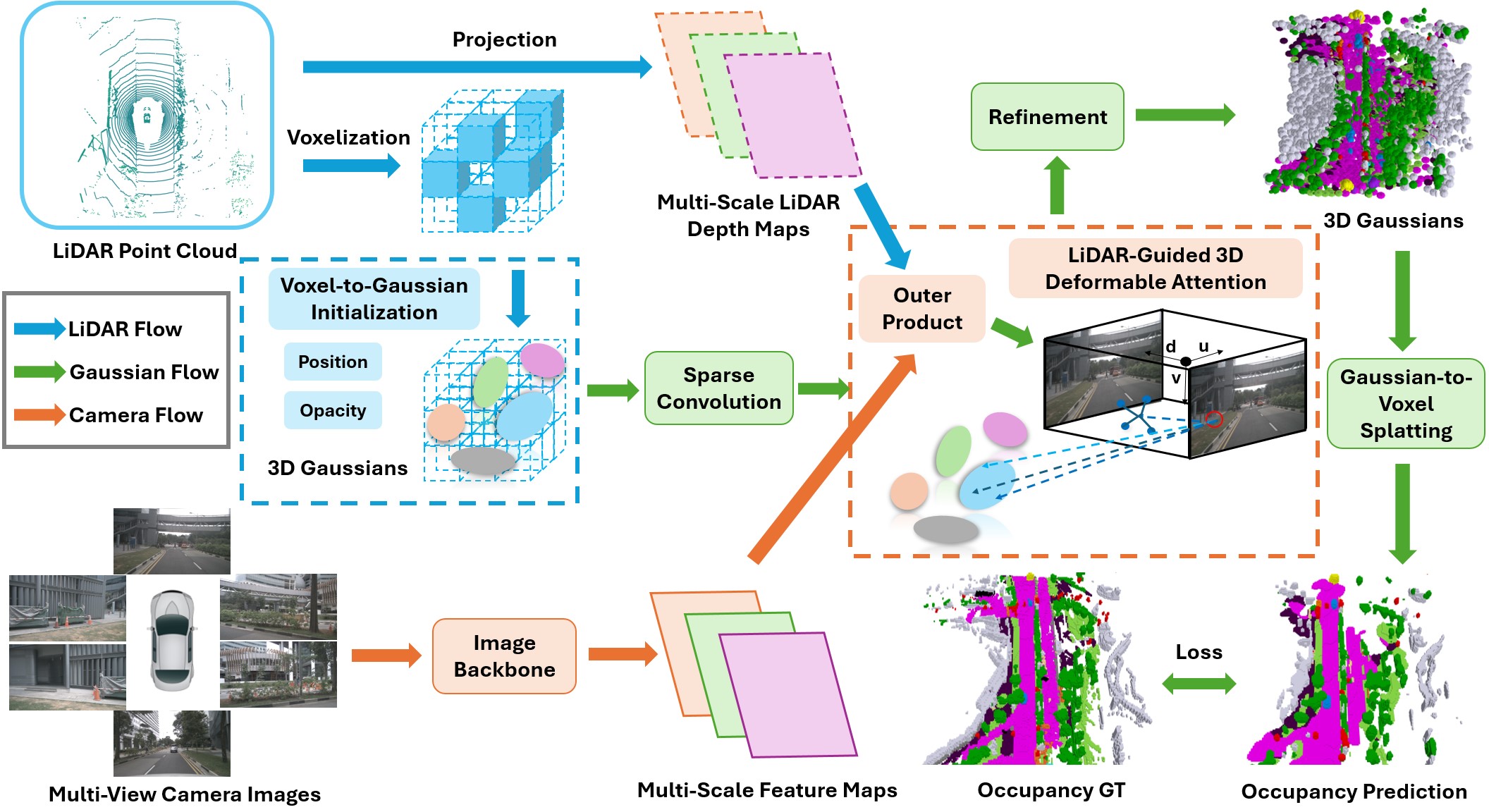
OccCylindrical
Multi-Modal Fusion with Cylindrical Representation for 3D Semantic Occupancy Prediction
https://www.arxiv.org/pdf/2505.03284
代码链接失效
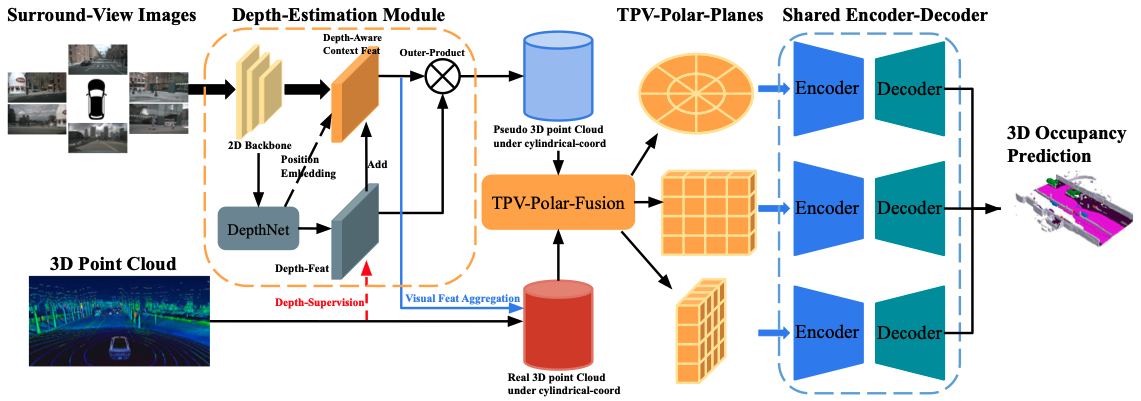
OccCylindrical的整体架构如下:首先,将环视图像通过二维主干网络进行初步处理,提取视觉特征。随后,利用DepthNet基于这些视觉特征生成深度分布特征,并使用激光雷达点云中的深度信息对深度分布特征进行监督。与此同时,将预定义的深度分布坐标(作为位置嵌入)与深度特征一起重新融合到视觉特征中,从而得到深度感知上下文特征。对深度分布特征和深度感知上下文特征进行外积操作,得到伪三维点云。TPV-Polar-Fusion模块以伪三维点云和激光雷达点云作为输入,进行特征级融合,并输出三个TPV-Polar平面。共享的编码器 - 解码器结构进一步细化TPV-Polar平面,并将细化后的TPV-Polar平面输出到预测头,用于三维语义占位预测。