
PointGPT
PointGPT: Auto-regressively Generative Pre-training from Point Clouds | Papers With Code
CGuangyan-BIT/PointGPT (github.com)

一种将GPT概念扩展到点云的方法,在多个3D点云下有任务中(点云分类,part分割等)上实现了最先进的性能。
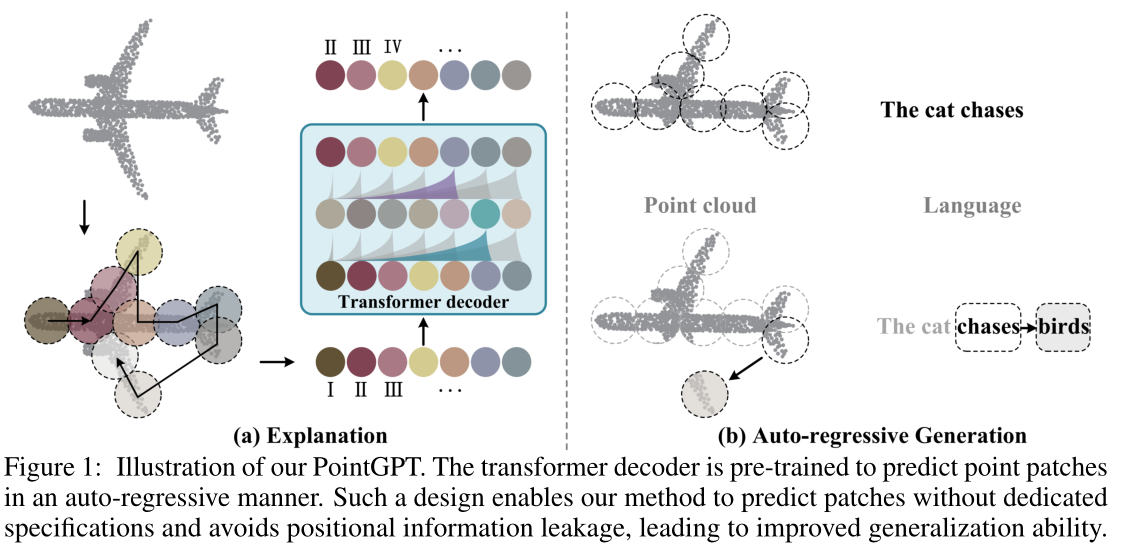
PointGPT 的整体架构
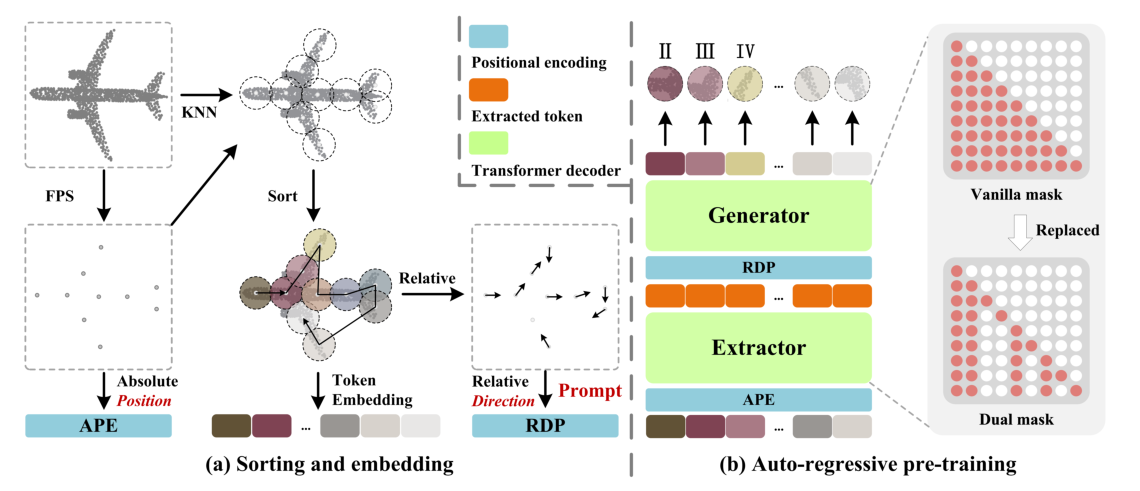
Fig.2. Overall architecture of our PointGPT. (a) The input point cloud is divided into multiple point patches, which are then sorted and arranged in an ordered sequence. (b) An extractor-generator based transformer decoder is employed along with a dual masking strategy for the auto-regressively prediction of the point patches. In this example, the additional mask of the dual masking strategy is applied to the same group of random tokens for better illustration purposes.
(a) 将输入点云分为多个点patches,然后将这些点patches按顺序排序和排列。 (b) 采用基于提取器-生成器的变换器解码器以及用于点patches的自回归预测的双掩蔽策略。在此示例中,为了更好地说明目的,将双重掩码策略的附加掩码应用于同一组随机token。
- 点云序列模块(Point Cloud Sequencer Module):这个模块用于构建点块的有序序列。它将点云分割成不规则的点块,并按照 Morton 排序将它们排列起来,形成一个有序序列。
- 提取器(Extractor):这是一个用于学习潜在表示的模块。有序的点块序列被输入到提取器中,通过自回归的方式学习点块的潜在表示。提取器的目标是从前面的点块中预测下一个点块。
- 生成器(Generator):这是一个用于自回归生成点块的模块。在预训练阶段,生成器根据前面的点块生成下一个点块,以自回归的方式逐步生成点块序列。在预训练结束后,生成器被丢弃,不再使用。
- 预训练后的阶段(Post-Pre-training Stage):在预训练阶段结束后,生成器被舍弃,而提取器则利用学习到的潜在表示进行下游任务。此时,不再使用双重掩码策略
Point Cloud Sequencer
在点云领域,与自然语言处理(NLP)领域不同,点云缺乏预定义的词汇表,并且点云是一种稀疏结构,具有无序性的特点。为了克服这些挑战并获得一个有序的点云序列,其中每个组成单元捕捉到丰富的几何信息,论文中采用了一个三阶段的过程,包括点块划分、排序和嵌入。
- 点块划分(Point Patch Partitioning):该阶段将点云划分为不规则的点块。通过将点云分割成块状的子集,可以将点云的结构分解成更小的部分,以便更好地进行处理。
- 排序(Sorting):划分的点块按照 Morton 排序进行排序。Morton 排序是一种用于多维数据的排序方法,通过将多维数据转换成一维的比特串,实现了对多维数据的排序。通过 Morton 排序,点块的顺序得到了定义,形成了有序的点块序列。
- 嵌入(Embedding):排序后的点块序列被嵌入到模型中,用于后续的预训练和任务学习。嵌入可以将点块的几何信息转化为模型能够理解和处理的向量表示。
通过这个三阶段的过程,点云被划分为有序的点块序列,并经过嵌入转换为模型可处理的表示形式。这样做的目的是克服点云领域缺乏预定义词汇表和无序性的问题,为后续的预训练和任务学习提供有序的输入。
点云序列
PointGPT 的预训练流程包括使用点云序列模块构建有序的点块序列,提取器学习点块的潜在表示,生成器自回归生成点块序列。在预训练后阶段,生成器被舍弃,提取器利用学习到的表示进行下游任务。这个流程旨在通过自回归生成任务来学习点云数据的特征表示,并为后续任务提供更好的表示能力。
点块分割
考虑到点云的固有稀疏性和无序性,输入点云通过最远点采样(FPS)和K近邻(KNN)算法处理,以获取中心点和点块。给定一个包含M个点的点云X,我们使用FPS初始采样n个中心点C。然后,利用KNN算法从X中选择k个最近的点构建n个点块P。
排序
为了解决点云的固有无序性,获得的点块根据它们的中心点被组织成一个连贯的序列。具体而言,使用Morton编码[34]将中心点的坐标编码到一维空间中,然后进行排序以确定这些中心点的顺序O。然后,将点块按照相同的顺序排列。
嵌入
在 PointGPT 中,采用了嵌入(Embedding)步骤来提取每个点块的丰富几何信息。与论文中引用的 Point-MAE 和 PointNet 方法类似,这里使用了 PointNet 网络来进行几何信息的提取。
具体而言,对于每个点块,使用 PointNet 网络对其进行处理,以提取其中的几何信息。PointNet 是一种常用的点云处理网络,能够对点云数据进行特征提取和学习。通过应用 PointNet 网络,可以从每个点块中提取丰富的几何特征。
为了促进训练的收敛性,对每个点的坐标进行了归一化处理,相对于其所在点块的中心点进行归一化。这样做可以减小数据的尺度差异,帮助模型更好地进行训练。在嵌入步骤中,使用 PointNet 网络对每个点块进行处理,提取其中的几何信息,并对点的坐标进行归一化处理,以促进训练的收敛性。
Transformer Decoder with a Dual Masking Strategy
论文中提到,将 GPT 直接应用到点云数据的方法是利用基本的 Transformer 解码器来自回归地预测点块,并对所有预训练参数进行微调以进行下游任务。然而,由于点云数据的信息密度有限以及生成和下游任务之间存在差距,这种方法在低级语义方面存在问题。
为了解决这个问题,论文提出了一种双重掩码策略,以促进对点云的全面理解。这个策略能够帮助模型更好地处理点云数据,提高语义的表达能力。
此外,论文还引入了提取器-生成器 Transformer 架构,其中生成器更专注于生成任务,并在预训练后被丢弃,从而增强了提取器学习到的潜在表示的语义水平。这种架构设计使得提取器能够更好地学习点云的语义信息,提高模型的表示能力。
为了应对点云数据的低级语义和生成任务与下游任务之间的差距,论文提出了双重掩码策略和提取器-生成器 Transformer 架构。这些方法能够提高模型对点云数据的理解能力,并增强潜在表示的语义水平。
Dual masking strategy?????
The vanilla masking strategy in the transformer decoder enables each token to receive information from all the preceding point tokens. To further encourage the learning of useful representations, the dual masking strategy is proposed, which additionally masks a proportion of the attending preceding tokens of each token during pre-training. The resulting dual mask M d is illustrated in Fig. 2(b),
双重屏蔽策略,该策略在预训练期间另外屏蔽了每个标记的一部分先前标记。得到的双掩码M d 如图2(b)所示
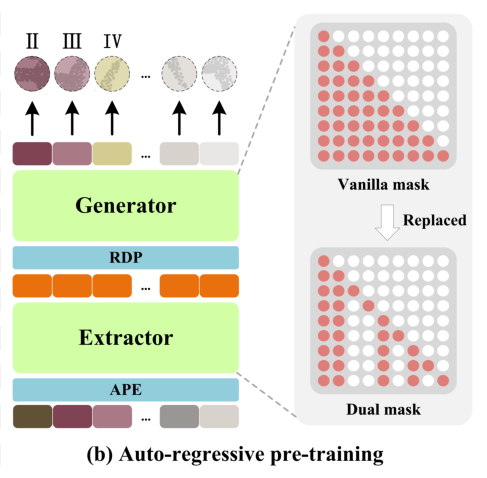
Extractor-generator
Extractor
- 提取器完全由 Transformer 解码器块组成,并采用双重掩码策略,得到潜在表示 T。在这里,每个点的令牌只与前面未被掩码的令牌相互关联。
- 考虑到点块是用归一化坐标表示的,并且全局结构对于点云的理解至关重要,论文中采用正弦位置编码(Sinusoidal Positional Encodings)将排序后的中心点的坐标映射到绝对位置编码(Absolute Positional Encoding)。
- 在每个 Transformer 块中添加位置编码,以提供位置信息和整合全局结构信息。
Generator
- 生成器的架构与提取器类似,但包含较少的 Transformer 块。它以提取的令牌 T 作为输入,并生成用于后续预测头的点令牌 Tg。
- 然而,由于中心点采样过程可能会影响点块的顺序,这在预测后续点块时会引入不确定性。这使得模型难以有效地学习有意义的点云表示。
- 为了解决这个问题,在生成器中提供了相对于后续点块的方向信息(RDP, relative direction prompts ),作为提示而不暴露被掩码的点块的位置和整体点云对象的形状。
Prediction head
预测头用于在坐标空间中预测后续的点块。它由一个两层的多层感知机(MLP)组成,包含两个全连接(FC)层和修正线性单元(ReLU)激活函数。预测头将令牌 Tg 投影到向量空间,其中输出通道的数量等于一个点块中的坐标总数。然后,这些向量被重新组织成预测的点块 。
Generation Target
在每个点patch的生成目标是预测后续点patch内点的坐标。
给定预测的点patch 和与排序后的点patch序列中最后 n0 个点patch对应的真实点patch ,生成损失 Lg 使用 Chamfer 距离(CD)的 L1 形式和 L2 形式进行定义,分别记为 Lg1 和 Lg2。
生成损失:
提示
Chamfer 距离(倒角距离)
是一种衡量两个点云之间距离的指标,用于评估生成的点块与真实点块之间的差异。Lg1 表示使用 L1 形式计算的 Chamfer 距离,而 Lg2 表示使用 L2 形式计算的 Chamfer 距离。
具体而言,生成损失 Lg1 和 Lg2 可以通过计算预测的点块 Ppd 与真实点块 Pgt 之间的 Chamfer 距离来获得。这些损失函数用于衡量生成结果与真实结果之间的差异,以指导生成器的训练。
Experiment
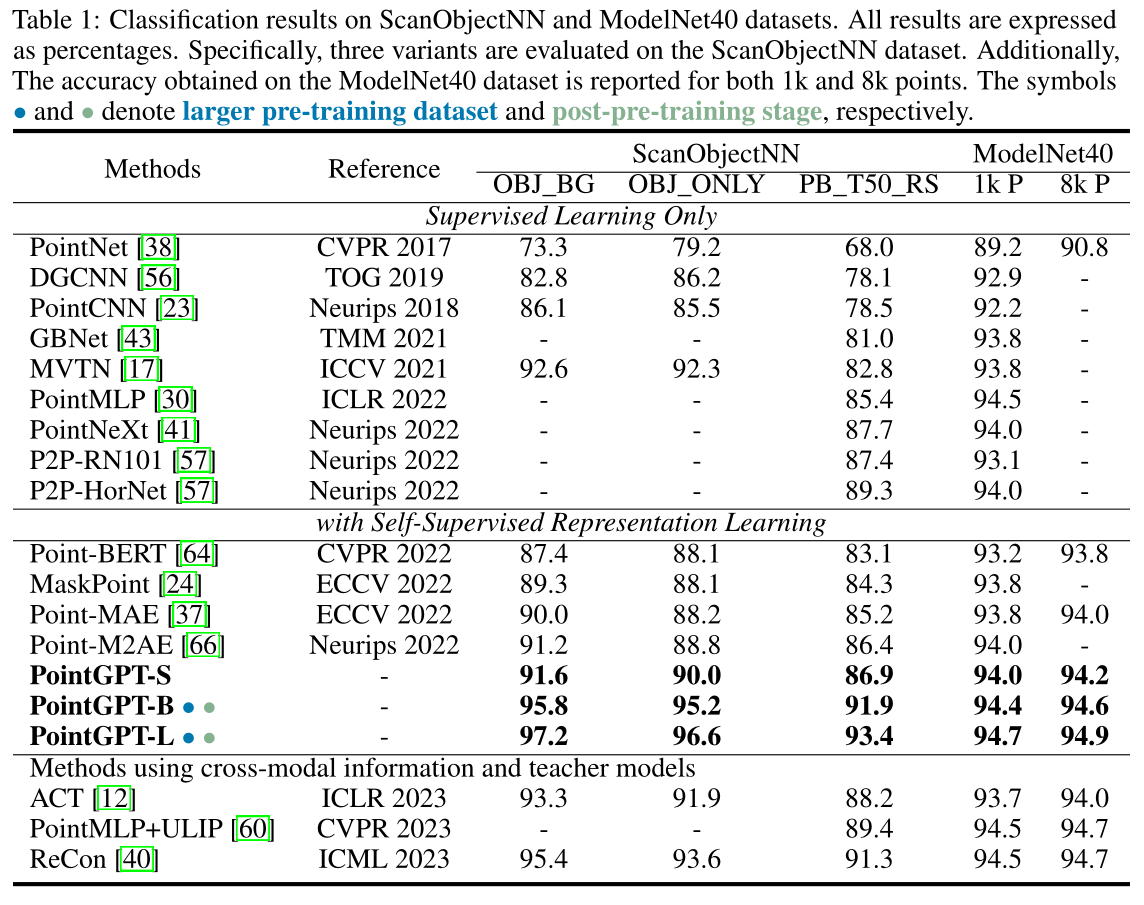
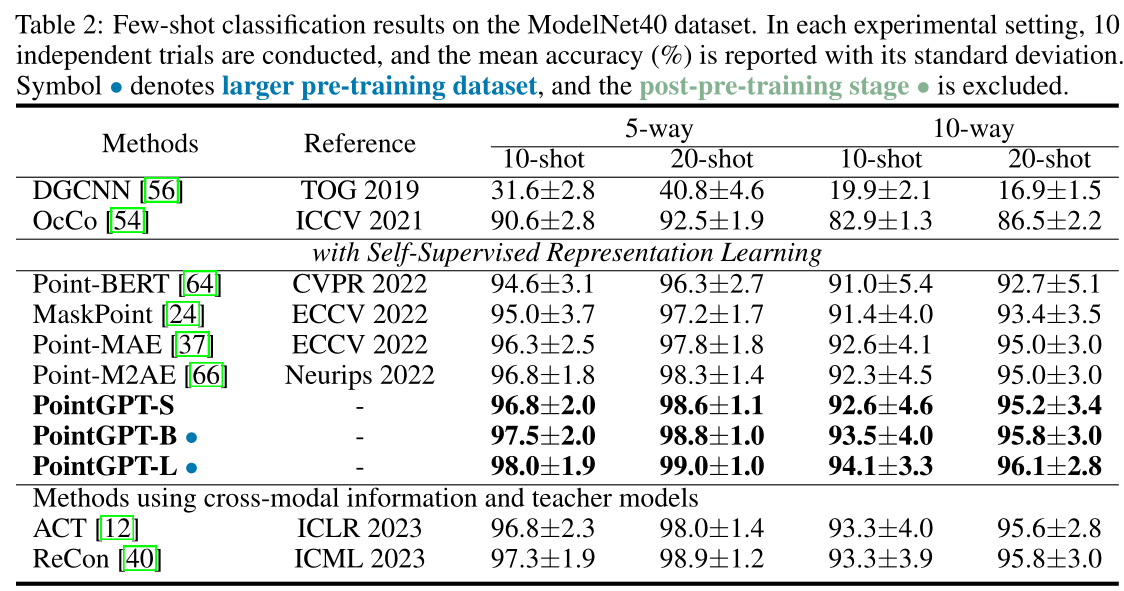
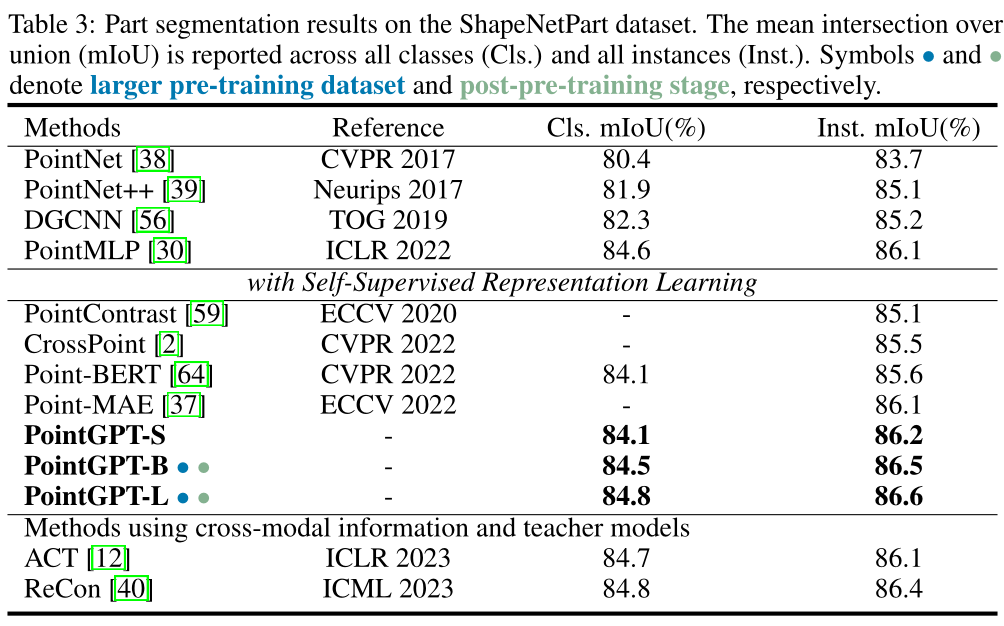
结论
本文介绍了PointGPT,这是一种将GPT概念扩展到点云领域的新方法,解决了点云的无序性、信息密度差异和生成任务与下游任务之间的差距等挑战。
在各种任务上验证了其有效性和强大的泛化能力,表明我们的PointGPT在模型容量相似的单模态方法中表现优异。此外,我们的大规模模型在各种下游任务上取得了SOTA的性能,无需跨模态信息和教师模型的参与。
尽管PointGPT表现出了良好的性能,但其探索的数据和模型规模仍然比NLP [5; 10]和图像处理 [65; 27] 领域小几个数量级。