
3d自监督
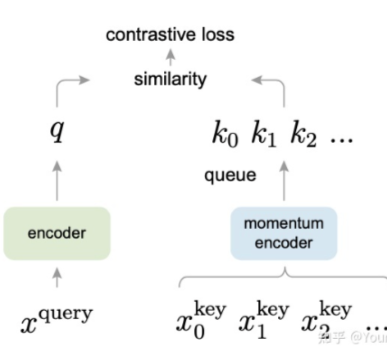
InfoNCE Loss
10.文本相似度/语义相似度/文本匹配之对比学习和SimCSE以及InfoNCE loss - 知乎 (zhihu.com)
InfoNCE loss与交叉熵损失的联系,以及温度系数的作用-CSDN博客
PointContrast
ECCV 2020
PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding | Papers With Code
Motivation
目前点云领域的自监督学习并没有取得很好的成果。作者认为原因可能是以下几点:
1、相较于2D领域,3D领域缺少高质量、大规模的数据集,这是由于收集3D数据的成本更高
2、缺乏统一的Backbone,目前点云特征提取的框架仍在快速发展
3、缺乏高层次的评价方式
基于以上几个问题,作者的研究主要涵盖了以下几个重要因素:
1、选择了一个大型数据集用于预训练
2、选用了一个可以用于多种下游任务的backbone
3、评估预训练效果的方法
4、定义了一组用于不同下游任务的评估办法
总的来说,作者认为这篇工作的贡献可以被总结为以下几点:
1、首次评估了3D点云的高级表达在不同场景中的转移性
2、实验结果表明,无监督预训练可以有效提高不同下游任务、数据集的性能
3、在无监督学习的加持下,在6种不同的评价基准上取得了最佳效果
4、本文的成功可以推动更多在相关方面的研究
方法
shapenet 有监督预训练测试
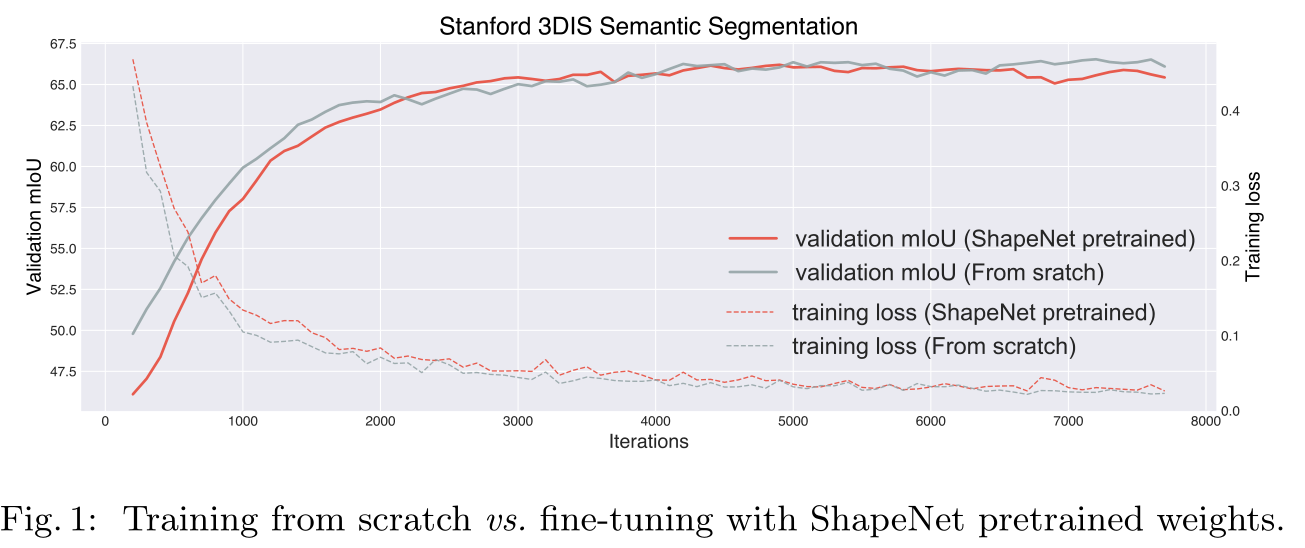
预训练几乎没有给下游任务带来任何收益,反倒看上去有一定的反作用。
源数据与目标数据之间的域差距(Domain gap)。预训练是在ShapNet上进行的,这个数据集本身是经过了归一化,对齐的干净数据集,并且缺乏场景信息。这导致了预训练数据集和微调数据集在数据分布上有较大的差距。
点级别(Point-level)的表示很重要。在3D点云的深度学习中,局部的特征表示是非常重要。所以直接进行instance level的全局级别的表示是不够的。(这里额外提一下,DepthContrast同样认为局部特征的学习比较重要,选择使用了随机丢弃的方式来强迫网络学习到局部特征)
基于以上的思考,以下两个点将是预训练过程中需要着重考虑的。
- 针对Domain gap,可以在具有复杂场景的数据集中训练,而不是ShapeNet那样的"干净"的数据集
- 为了捕获点级别的信息,需要相应的任务和框架,这个框架不仅仅是基于实例/全局表示的,而且可以在点级别捕获密集/局部的特征
算法
对一个点云进行两种变换(旋转、平移和尺度缩放),然后使用contrastive loss对两种视角下点云的点进行对比学习,最小化匹配的点对之间的距离,同时最大化不匹配的点之间的距离,网络需要学习到几何变换下的不变性。

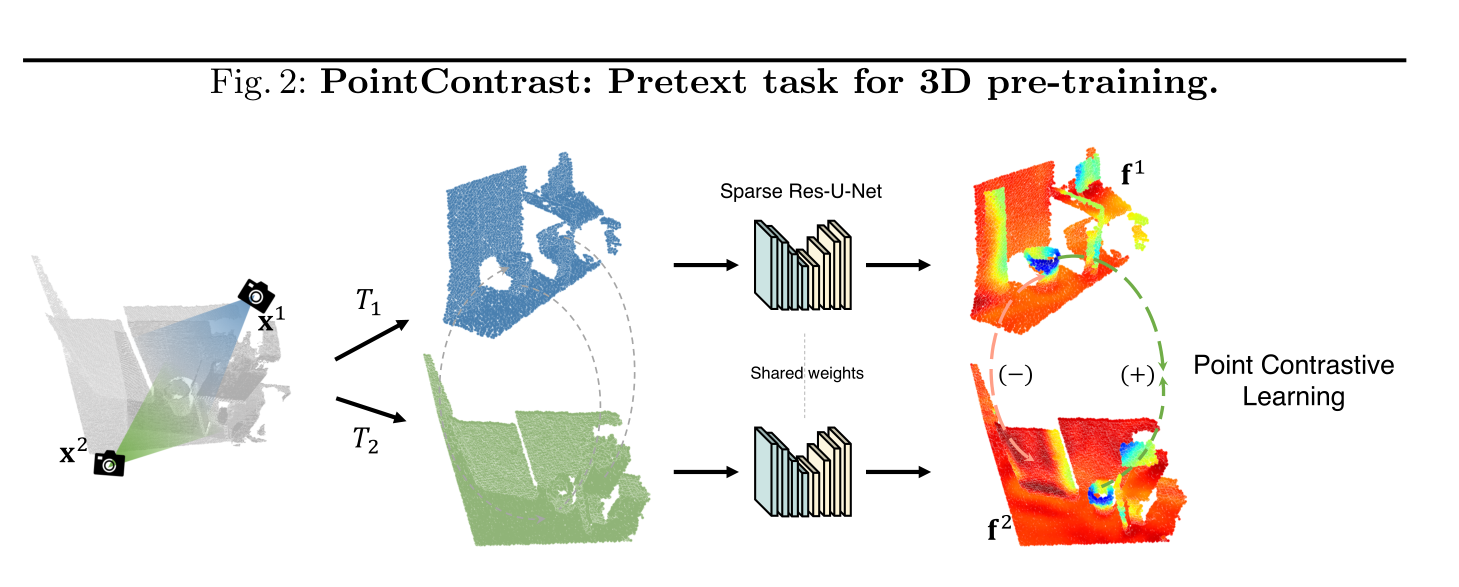
算法流程如下:
- 对一个点云x,从两个不同的相机视角生成两个视角下的点云x1和x2(这一步是算法有效的关键),
- 然后分别对x1和x2进行随机刚体变换T1和T2,进一步将两个点云变成不同的视角加大任务的难度,
- 然后分别对两个点云进行编码,进行对比学习训练。
结果
关于监督预训练?
We deem this a very encouraging signal that suggests that the gap between supervised and unsupervised representation learning in 3D has been mostly closed (cf. years of effort in 2D).
预训练是否可以被拉长训练回合替代?
在迭代次数分别为20K和30K的时候,分割任务的mIoU分别为66.7%和66.1%。
This suggests that potentially many of the 3D datasets could fall into the “breakdown regime”[24] where network pre-training is essential for good performance.
单视角设定下PointContrast是否也可以发挥作用?
单视角+数据增强:在S3DIS上最好的mIoU为68.35%,仅仅比不进行预训练的68.17%
作者认为,这可能是因为multi-view可以让训练样本更多样,相机不稳定而产生的自然噪声让模型变得更加鲁棒。
DepthContrast
ICCV 2021
Self-Supervised Pretraining of 3D Features on any Point-Cloud | Papers With Code
四个贡献点:
1、该方法证明了,仅仅使用单视图的三维深度扫描信息就足以使用自监督学习获得有效的特征表示了(因为前面性能最好的算法是PointContrast,其使用了Mutil View的视图)
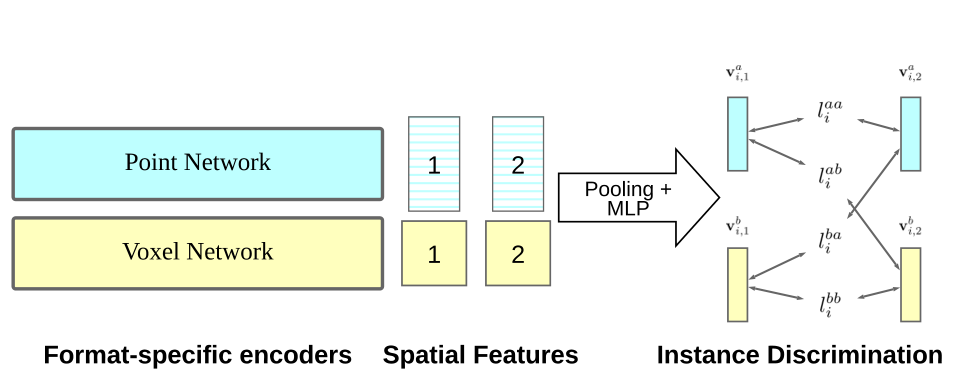
2、发现使用不同的输入表示,比如点云和体素,进行联合训练会有一个比较好的结果,远优于使用单个输入表示。
3、该算法适用于不同的模型框架,室内/室外的3D数据,单视角/多视角的3D数据。同时该算法可以用于预训练高容量的3D框架,并应用于检测、分割等下游任务。
4、该算法在多个下游任务上取得了最佳的表现效果
方法
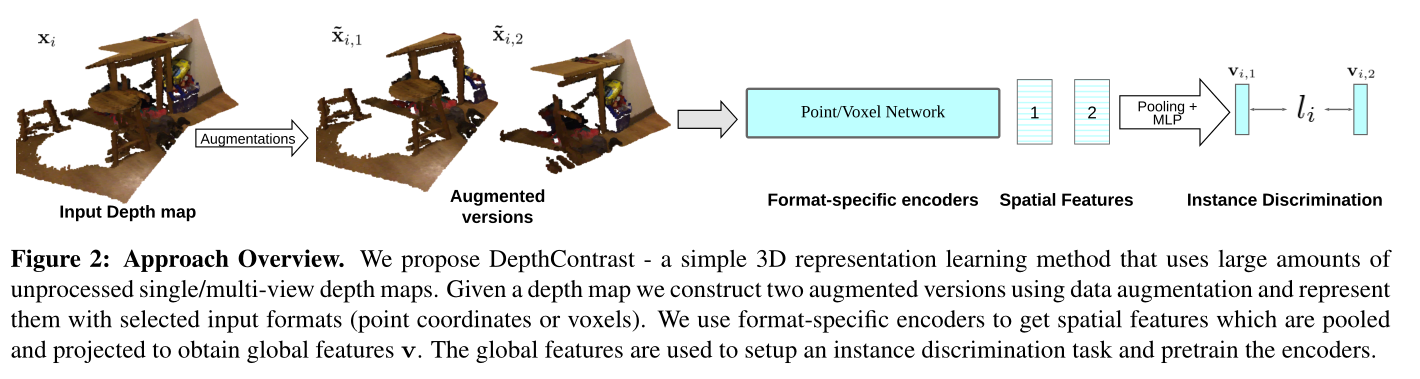
获取单帧深度图 ,转换为点云信息,使用数据增强获得两个增强视图
分别使用Voxel-based的网络和Point-based的网络为两个增强视图提取特征,得到4个特征
将这4个特征互相之间视为Positive pair,两两取出来使用Info-nce loss计算损失。
提示
Point-based的方法下作者选用了PointNet++
Voxel-based的方法下作者选用了U-Net
新的增强方法
- random crop
- random drop patches 。
这两个方法灵感来源于图像领域。其中random crop指随机从视图中挖出一块作为正样本,rondom drop paches指随机丢弃视图中的一部分(这样可以强迫网络关注局部形状特征)。
结果
略,取得了sota
无分割任务,本文针对检测
总结
- 未考虑分割任务。
- 与 pointcontrast 相比,无需多视图信息,(无需相机位置)
- 跨输入格式,将Voxel-based额 Point-based的方法结合了起来。
Masked Scene Contrast
A Scalable Framework for Unsupervised 3D Representation Learning
CVPR 2023
Approch
对比学习
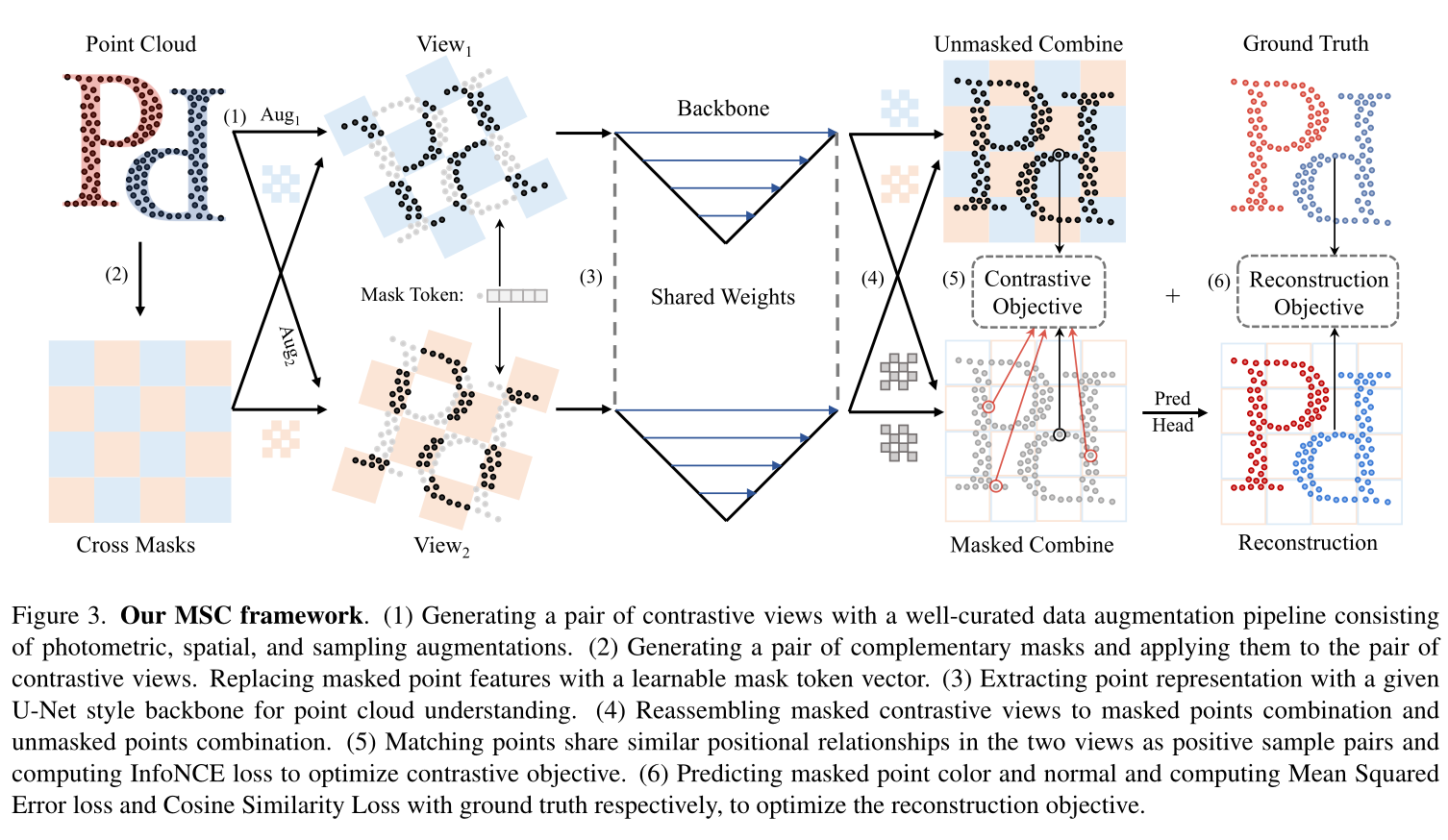
我们的对比学习框架直接对点云数据进行操作。给定一个点云,对比学习框架可以总结如下:
- 视图生成。对于给定的点云 X,我们使用一系列随机数据增强(包括光度、空间和采样增强)生成原始点云的查询视图 Xr 和关键视图 Xk。
- 特征提取。使用 U-Net 风格的主干 ζ(·) 将点云特征 Fr 和 Fk 分别编码为 ˆFr 和 ˆFk。
- 点匹配。对比学习的正样本是两个视图中空间位置接近的点对。对于属于查询视图的每个点,我们计算到关键视图的点的对应映射 P,如果 (i, j) ∈ P 则点 (pi, ci) 和点 (pj, cj) 在两个视图上构造一对。
- 损失计算。计算两个视图 ^Fr 和 ^Fk 的表示以及对应映射 P 的对比学习损失。编码的查询视图应该与其关键视图相似。
数据增强
详见论文,
重建学习
点云的特征由两部分组成,决定几何结构的坐标和表示纹理特征的颜色。我们分别为这两组特征建立重建目标。点云纹理的重建很直接,我们用线性投影预测每个点的光度值。我们计算重建的颜色和原始颜色之间的均方误差(MSE)作为颜色重建损失
点坐标在描述点云的几何结构中起着重要的作用,值得注意的是,直接重建掩蔽点的坐标是不合理的,因为掩蔽点只是从3D物体表面而不是连续表面本身采样的。重建点坐标会导致过拟合的表示。为了克服这个挑战,我们引入了surfel重建的概念。Surfel???是离散拓扑文献[26]和基元渲染[36]中的表面元素或表面体素的缩写。对于每个掩蔽点,我们重建相应surfel的法向量,并计算估计值和surfel法向量之间的平均余弦相似性作为对比损失

MACARONS
CVPR 2023
Mapping And Coverage Anticipation with RGB Online Self-Supervision
MACARONS: Mapping And Coverage Anticipation with RGB Online Self-Supervision | Papers With Code
未开源
NBV 问题,有点不相关
学习如何有效地探索场景并仅使用 RGB 传感器重建
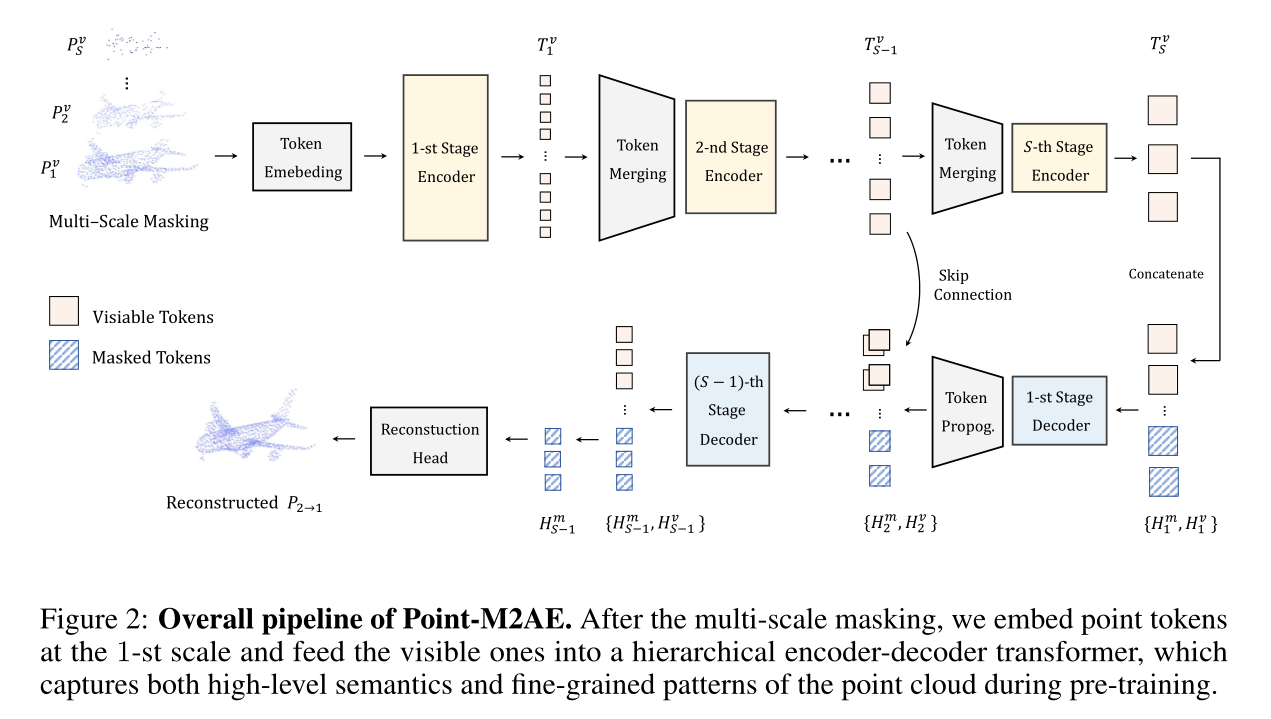
Point-M2AE:
NeurIPS 2022
Multi-scale Masked Autoencoders for Hierarchical Point Cloud Pre-training
一种用于对 3D 点云进行自监督预训练的多尺度掩码自编码器
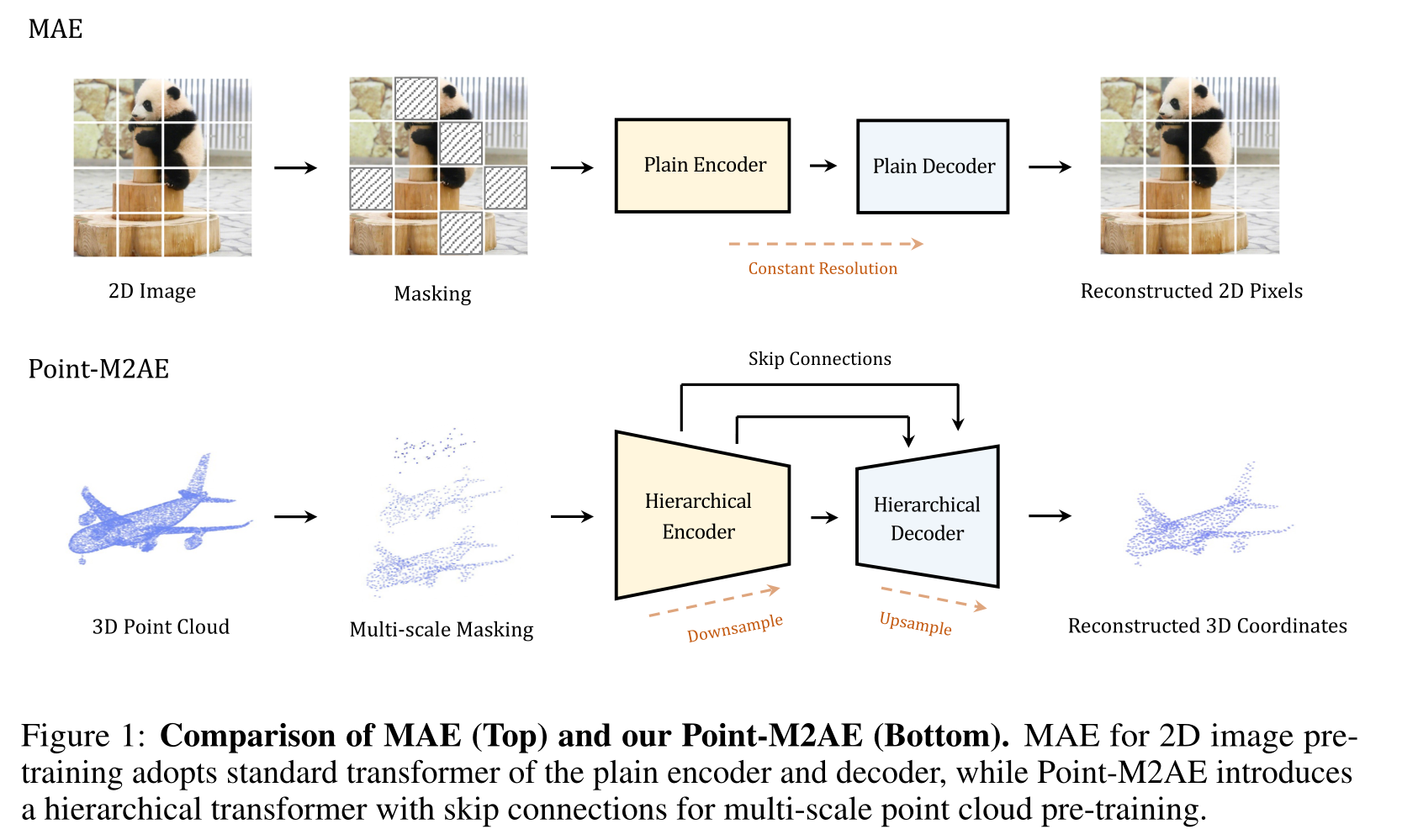
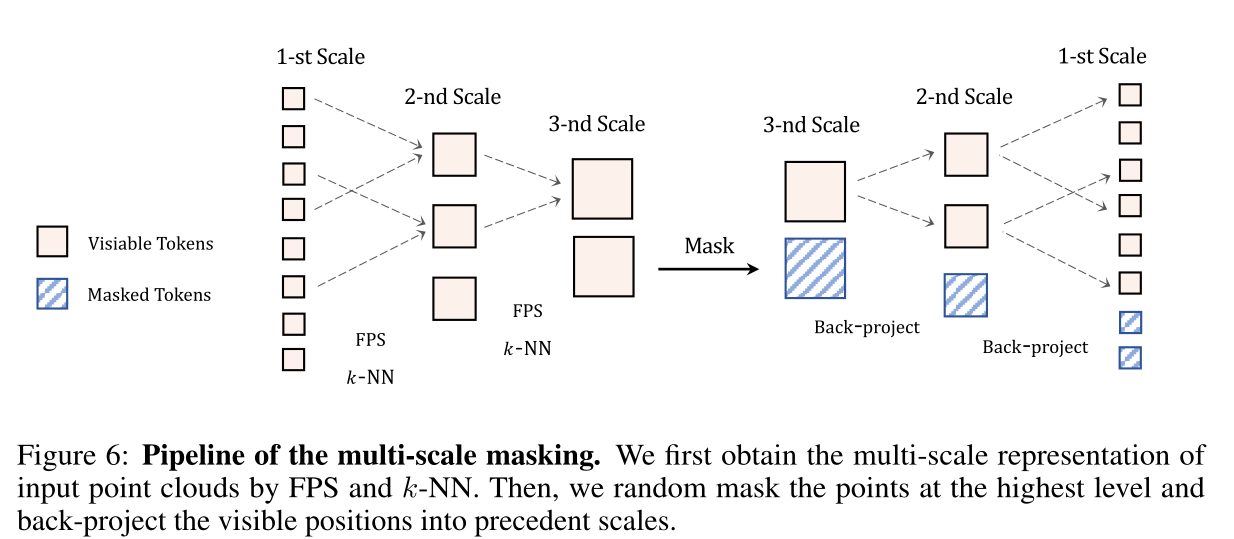
token emebeding:pointnet++
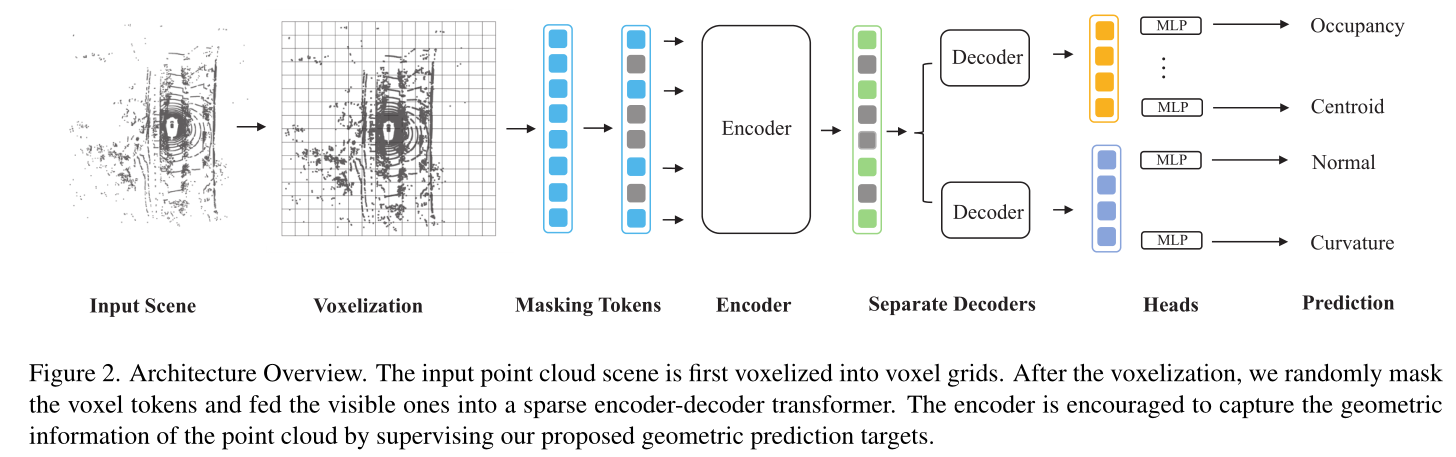
GeoMAE
CVPR 2023
Masked Geometric Target Prediction for Self-supervised Point Cloud Pre-Training
引入点统计和表面属性预测目标来指导模型学习点云的几何特征。
我们应该利用什么好的信号来从没有注释的点云中学习特征?为了回答这个问题,我们引入了基于几何特征重建的点云表示学习框架。与最近直接采用掩模自动编码器(MAE)并仅从掩模点云预测原始坐标或占用率的论文相比,我们的方法重新审视图像和点云之间的差异,并识别点云特有的三个自监督学习目标,即质心预测、法线估计和曲率预测。这三个目标相结合,产生了一项重要的自监督学习任务,并相互促进模型更好地推理点云的细粒度几何形状。
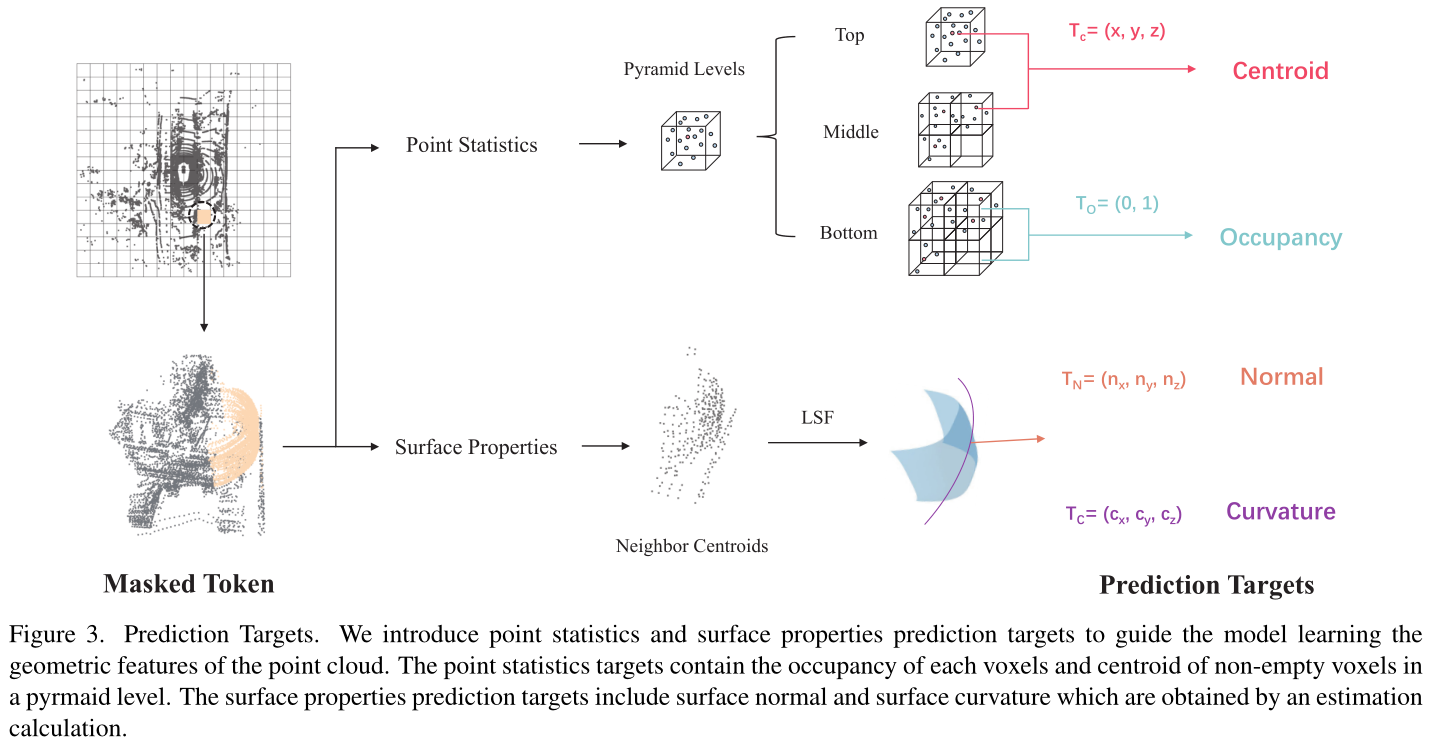
Embracing Single Stride 3D Object Detector with Sparse Transformer | Papers With Code