
OneFormer3D
OneFormer3D
CVPR 2023
LargeKernel3D: Scaling up Kernels in 3D Sparse CNNs | Papers With Code
摘要:对于3D点云的语义分割、实例分割和全景分割已经分别使用了特定设计的任务模型进行了研究。因此,所有分割任务的相似性和它们之间的隐含关系并未得到有效利用。本文提出了一个统一、简单而有效的模型,共同解决了所有这些任务。该模型被命名为OneFormer3D,使用一组可学习的核心一致地执行实例和语义分割,其中每个核心负责为实例或语义类别生成掩码。这些核心通过一个基于transformer的解码器进行训练,其中统一的实例和语义查询作为输入传递。这样的设计使得能够在单次运行中端到端地训练模型,从而在同时实现所有三个分割任务的最佳性能。具体而言,我们的OneFormer3D在ScanNet测试排行榜中获得了第一名,并取得了新的最先进水平(+2.1 mAP50)。我们还展示了在ScanNet(+21 PQ)、ScanNet200(+3.8 mAP50)和S3DIS(+0.8 mIoU)数据集的语义分割、实例分割和全景分割方面的最先进结果。
解决的问题:
该论文要解决的问题是点云分割的问题,即如何将三维点云中的每个点分配到不同的语义或实例类别,从而实现对点云的理解和分析。点云分割是三维计算机视觉中的一个重要和具有挑战性的任务,它有着广泛的应用,如机器人导航、自动驾驶、增强现实等。点云分割的难点主要有以下几个方面:
- 点云的表示方式多样,如稀疏体素、八叉树和点云,每种表示方式都有其优缺点,如何设计一个通用的模型,可以适应不同的点云表示,是一个关键的问题。
- 点云的数据量大,且具有不规则和无序的特点,如何有效地处理点云的数据结构,提取点云的特征,是一个核心的问题。
- 点云的分辨率和密度不均匀,且受到噪声和遮挡的影响,如何提高点云分割的鲁棒性和精度,是一个实际的问题。
该论文的目标是提出一个基于Transformer的模型,可以统一处理不同的点云表示,利用自注意力机制和跨注意力机制,捕捉点云的局部和全局上下文信息,同时引入一个动态的点云采样模块,可以根据点云的密度和复杂度,自适应地调整采样率,从而解决点云分割的问题。
主要贡献:
- 它设计了一个通用的点云编码器,可以将不同的点云表示转换为一致的特征向量,从而实现跨表示的点云分割。
- 它提出了一个基于Transformer的点云解码器,可以利用自注意力机制和跨注意力机制,有效地捕捉点云的局部和全局上下文信息。
- 它引入了一个动态的点云采样模块,可以根据点云的密度和复杂度,自适应地调整采样率,从而提高模型的效率和鲁棒性。
- 它在多个点云分割的数据集上进行了实验,包括S3DIS、ScanNetv2、ShapeNetPart和PartNet,并在所有数据集上取得了最先进的性能,证明了其模型的优越性和通用性。
架构
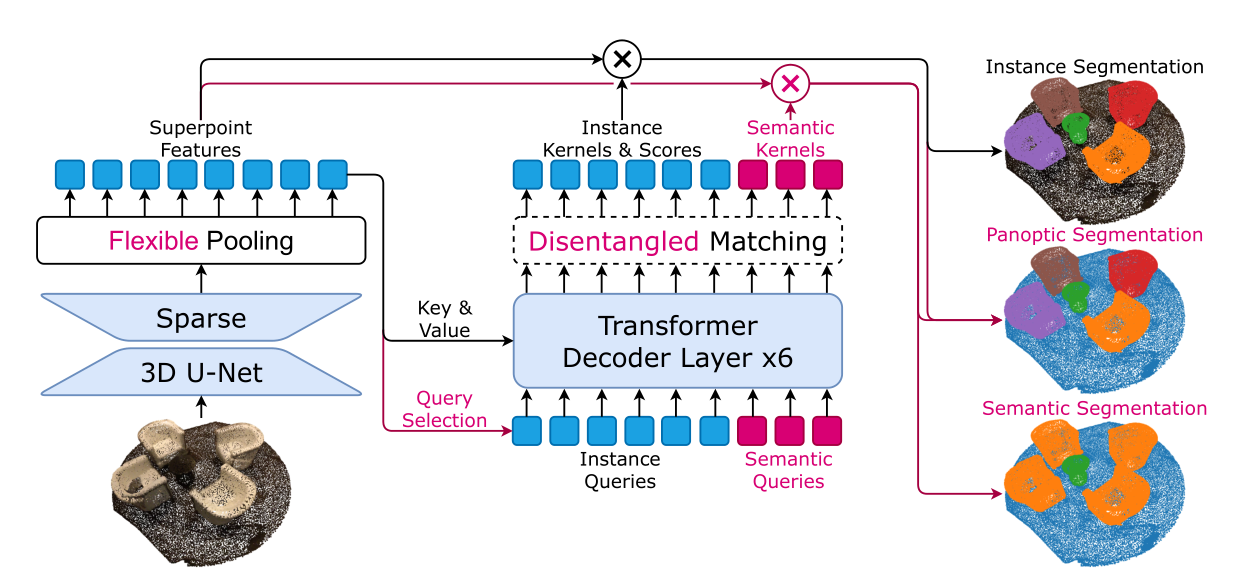
OneFormer3D 框架基于 SPFormer(蓝色),但具有许多改进(红色)。一旦获得 3D 点云作为输入,我们训练的模型就可以解决 3D 实例、3D 语义和 3D 全景分割任务。虚线描绘了仅在训练期间应用的组件。
- First, a sparse 3D U-net extracts point-wise features
- Then, these features pass through a flexible pooling, that obtains superpoint features through simply averaging features of points in a superpoint. Superpoint features serve as keys and values for a transformer decoder (Sec. 3.2), that also accepts learnable semantic and instance queries as inputs.
- The decoder captures superpoints information via a cross-attention mechanism, and outputs a set of learned kernels, each representing a single object mask of an instance identity (from an instance query) or a semantic region (from a semantic query.
- A disentangled matching strategy is adopted to train instance kernels in an end-to-end manner (Sec. 3.3). As a result, a trained OneFormer3D can seamlessly solve semantic, instance, and panoptic segmentation (Sec. 3.4).
- 然后,这些特征通过flexible pooling灵活的池化,通过简单地平均超点中点的特征来获得Superpoint feature超点特征。 Superpoint 特征充当transformer解码器的key和value(第 3.2 节),它也接受可学习的语义和实例queries作为输入。
- 解码器通过交叉注意机制捕获超点信息,并输出一组学习内核,每个内核代表实例身份(来自实例查询)或语义区域(来自语义查询)的单个对象掩码。
- 解缠结匹配策略采用端到端的方式训练实例内核(第 3.3 节)。因此,经过训练的 OneFormer3D 可以无缝解决语义、实例和全景分割问题(第 3.4 节)。
Sparse 3D U-Net.
假设输入点云包含N个点,则输入可以表示为。每个 3D 点都用三种颜色 r、g、b 和三个坐标 x、y、z 进行参数化。按照[6],我们对点云进行体素化,并使用由稀疏 3D 卷积组成的类似 U-Net 的主干来提取逐点特征
Query Decoder
查询解码器将 $K_{ins} + K_{sem} $查询作为输入,并将其转换为 内核。然后,超点特征与这些内核进行卷积,分别生成 实例和 语义掩码。
Semantic queries语义查询是随机初始化的,与现有的 3D 实例分割方法相同?
通过交叉注意力学习
Query selection
最先进的 2D 对象检测和 2D 实例分割方法 [19,45,50] 使用高级策略初始化查询,通常称为查询选择。具体来说,输入查询使用来自转换器编码器的特征进行初始化,并根据对象分数进行采样。该分数是由同一模型估计的,该模型由训练期间额外的客观性损失引导。事实证明,所描述的技术可以加快训练速度,同时共同提高整体准确性。然而,据我们所知,类似的方法从未应用于 3D 对象检测或 3D 分割。
因此,我们的目标是通过适用于 3D 数据的查询选择的简化版本和非变换器编码器来缩小这一差距。特别是,我们在灵活池化后使用骨干特征初始化查询。通过查询选择,我们仅随机选择一半的初始化查询,以在训练期间进行额外的增强。在推理过程中,我们类似地初始化查询,但不过滤查询以保留所有输入信息。