
Clio
https://github.com/MIT-SPARK/Clio
标题:Clio: 实时任务驱动的开放集3D场景图
摘要: 现代工具,如类无关图像分割(例如SegmentAnything)和开放集语义理解(例如CLIP),为机器人感知和映射提供了前所未有的机会。虽然传统的封闭集度量-语义地图被限制在数十或数百个语义类别,我们现在可以构建包含大量对象和无数语义变体的地图。这让我们面临一个基本问题:机器人的地图表示中应该包含的对象(以及更一般地,语义概念)的正确粒度是什么?尽管相关工作通过调整对象检测的阈值隐式选择了粒度级别,我们认为这样的选择本质上是任务依赖的。
本文的第一贡献是提出了一个任务驱动的3D场景理解问题,其中机器人被赋予自然语言中的任务列表,并且必须选择粒度和保留在地图中的对象和场景结构的子集,以足以完成任务。我们展示了这个问题可以使用信息瓶颈(Information Bottleneck, IB ),一个建立的信息理论框架来讨论任务相关性。
第二贡献是基于聚合IB方法的任务驱动3D场景理解算法,能够将环境中的3D原语聚类成与任务相关的对象和区域。
第三贡献是将我们的任务驱动聚类算法集成到一个实时流水线中,名为Clio,它在线构建环境的层次化3D场景图,并且仅使用机载计算。
我们最后的贡獻是通过广泛的实验活动表明,Clio不仅允许实时构建紧凑的开放集3D场景图,而且还通过限制地图仅包含相关语义概念来提高任务执行的准确性。
1. 引言:
机器人学中的一个基本问题是如何创建一个对机器人有用的场景地图表示,其中“有用性”是通过机器人使用地图来完成任务的能力来衡量的[1, 2]。包括[3–7]在内的最新研究工作通过检测对应于封闭语义集的对象和区域来构建度量-语义3D地图。然而,封闭集检测在概念集的表示上存在固有的局限性,并且不能很好地处理自然语言的内在模糊性和多样性。为了克服这些限制,一系列新的方法[8, 9]开始利用视觉-语言基础模型来实现开放集的语义理解。这些方法使用类无关的分割网络[10](例如SegmentAnything或SAM)来生成图像的细粒度分割,然后应用基础模型[11]来获取描述每个分割的开放集语义的嵌入向量。对象是通过将嵌入向量在预定义的相似性阈值内的片段关联起来构建的。然而,这些方法留给用户一个困难的任务,即调整合适的阈值来控制从场景中提取的片段数量以及用于决定两个片段是否应该聚类在一起的阈值。更重要的是,这些方法没有捕捉到这样一个直觉,即地图中的语义概念选择不仅仅是由语义相似性驱动的,而是本质上是任务依赖的。
例如,考虑一个被指派在房间里移动钢琴的机器人。机器人几乎不需要通过区分所有的琴键和琴弦的位置来获得价值(gains almost no value),而是可以通过将钢琴视为一个大对象来完成任务。另一方面,一个被指派弹钢琴的机器人必须将钢琴视为许多对象(即琴键)。一个被指派调音钢琴的机器人必须将钢琴视为更多的对象——考虑琴弦、调音销等。同样,像一堆衣服应该被表示为一个单独的堆还是作为单独的衣服,或者森林应该被表示为单一的景观区域还是作为树枝、树叶、树干等,这些问题在没有指定表示必须支持的任务之前都是未定义的。
我们提出Clio,一种新颖的方法,用于实时构建任务驱动的3D场景图,并嵌入开放集语义。我们从经典的信息瓶颈原理中汲取灵感,通过自然语言任务(比如“阅读棕色教科书”)对对象原语进行任务相关的聚类——并通过聚类场景到任务相关的语义区域,如“小厨房”或“工作区”。人类不仅在(有意识或无意识地)决定哪些对象要表示以及如何表示时考虑任务,而且还能够相应地忽略与任务无关的场景部分[12]。
贡献。
- 我们的第一个贡献(第III节)是提出任务驱动的3D场景理解问题,其中机器人被赋予自然语言中的任务列表,并需要构建一个最小的地图表示,足以完成给定的任务。更具体地说,我们假设机器人能够在环境中感知到任务不可知的原语,以大量的3D对象片段和3D无障碍地点的形式存在,并且必须将它们聚类成一个任务相关的压缩表示,其中只包含相关对象和区域(例如,房间)。这个问题可以自然地使用经典信息瓶颈(IB)理论来表述,该理论也提供了任务驱动聚类算法的方法。
- 我们的第二个贡献(第IV节)是将[14]中的聚合IB算法应用于任务驱动的3D场景理解问题。特别是,我们展示了如何使用CLIP嵌入来获得算法[14]所需的概率密度,并展示了结果算法可以随着机器人探索环境而增量执行,计算复杂度不随环境大小增加。
- 我们的第三个贡献(第V节)是将提出的任务驱动聚类算法集成到一个实时系统中,名为Clio(见图1)。Clio在操作开始时接收一个用自然语言指定的任务列表:例如,这些可以是机器人在其生命周期中或在其当前部署期间被设想要执行的任务。然后,随着机器人的操作,Clio实时创建环境的层次地图,即3D场景图,其中表示只保留任务相关的对象和区域。与当前的开放集3D场景图构建方法(例如[9])不同,这些方法在查询大型视觉-语言模型(VLMs)[15]和大型语言模型(LLMs)[16]时仅限于离线操作,Clio实时运行并且仅依赖于轻量级基础模型,如CLIP[11]。
我们在Replica数据集[17]和四个真实环境中(第VI节)——一个公寓、一个办公室、一个隔间和一个大规模建筑场景——展示了Clio的性能。我们还在携带机械臂的波士顿动力Spot四足机器人上展示了Clio的实时机载映射(见图2)。Clio不仅允许实时开放集3D场景图构建,而且还通过限制地图仅包含相关对象和区域来提高任务执行的准确性。我们在https://github.com/MIT-SPARK/Clio上开源了Clio以及我们的定制数据集。
2. 相关工作:
机器人视觉和视觉-语言模型。
最近视觉-语言模型[11, 15, 18]和大型语言模型[16]的出现,导致了众多探索它们在3D场景理解[19, 20]和机器人规划[21–23]中潜力的工作。许多工作调查了基础模型的现状及其局限性[24–26]。类无关分割网络[10, 27]已经与基础模型结合,以实现开放集图像分割[28–33]。最近的工作还探索了直接的类无关3D分割[34]。显著性检测被用来识别人类可能首先注意到的图像部分[35]。这里,我们不是关注视觉显著性,而是希望创建任务驱动的场景地图。
基础模型用于3D映射。
最近的工作将基础模型与神经辐射场[36]和高斯溅射[37]结合起来。Kerr等人[38]提出了LERF,它构建了一个可以渲染场景密集CLIP向量的辐射场。LERF可以通过文本查询,并估计场景中最相似于查询的部分,使用增强的余弦相似度分数。Qin等人[39]开发了LangSplat,它在LERF的基础上使用高斯溅射创建了一个3D场景语言地图,并显著提高了速度。Blomqvist等人[40]提出了一种增量构建神经语义地图的方法,用于SLAM。Kim等人[41]构建了一个分层神经地图,可以在不同的粒度级别渲染,聚类和划分对象。Taioli等人[42]使用CLIP构建了一个可以通过文本查询的隐式网格图。几项工作将开放集检测纳入场景的3D地图中[43–48]。Chang等人[49]执行开放词汇映射,结合了在封闭集上训练的图神经网络来映射对象及其关系。Takmaz等人[50]开发了一种开放集实例分割的方法。Jatavallabhula等人[8]生成了一个语义3D点云,其中每个点都被分配了CLIP向量。
与我们最相似的是ConceptGraphs[9],它构建了一个3D对象图,通过LLM[16]分配的关系连接对象。ConceptGraphs使用CLIP和SAM聚类场景中的对象,定义了它们之间的语义和几何相似性。可选地,ConceptGraphs使用多个对象视图查询大型视觉-语言模型[15],以计算对象的简洁描述。然后可以使用CLIP的余弦相似度或LLM来查询对象。同时,Werby等人[51]展示了大规模开放集语义使用分层3D场景图,但不在实时运行。
任务驱动的表示。
经典的信息瓶颈[13]旨在压缩给定信号,同时保留压缩表示与另一个感兴趣信号之间的互信息。最初的工作[13]已经扩展为一个自下而上的聚类方法,称为聚合 IB (Agglomerative IB)[14]。我们基于IB理论构建,目标是将场景表示压缩成相关对象和区域的聚类,以适应给定的一组任务。Gordon等人[52]将信息瓶颈扩展到将一组单独的图像压缩成聚类,以便每个聚类保留包含在聚类中的图像的上下文信息。Wang等人[53]使用IB进行VLMs的图像和文本输入之间的归因,实验使用CLIP进行。Larsson 等人[54, 55]利用聚合 IB 获得最优占据图压缩,适用于资源有限的代理。Soatto和Chiuso[1]推导出最小充分场景表示的表达式,这些表示保留了关于某些任务的兴趣信息,[56]围绕构建物理场景的基础模型理论。Eftekhar等人[57]以任务相关的方式压缩视觉观察。他们的工作使用了一个学习到的码本模块,该模块接收当前代理的行动以及任务和传感器数据,并输出一个行动,以朝向目标迈进以进行导航。另一项工作基于可供性[58]检测图像中的感兴趣区域,并创建场景中对象的可供性3D地图[59]。
3. 问题表述:任务感知 3D 场景理解
尽管许多研究人员会同意地图表示必须是任务依赖的,但迄今为止还没有一个通用框架来确定机器人的度量-语义3D地图中包含的语义概念的正确粒度。这种差距部分是由于提供丰富的任务描述的困难,导致现有的视觉和机器人学中的任务驱动表示框架要么太狭窄,要么计算成本太高[60]。
在本文中,我们利用两个关键见解。
首先,视觉-语言模型的进步以前所未有地将视觉信息和文本描述结合起来。这极大地简化了任务描述问题:我们只需将任务陈述为机器人在其生命周期或当前部署期间预期执行的语言指令列表(例如,“洗碗”,“叠衣服”,“捡起玩具并放在架子上”),并使用视觉-语言模型将这些指令与视觉数据关联起来。以下,我们用符号 表示任务列表。
其次,现代的基础模型为任务不可知分割提供了一种方式,可以过度分割图像成可能大量的片段,我们可以将其重新投影到3D。类似地,使用几何分割技术,我们可以轻松地将环境分割成大量无障碍的地方[6]。以下,我们将任务不可知的3D片段和地方称为任务不可知原语,并用 X 表示;直观地说,这些为我们想要保留在地图中的提供了一个概念的超集。
使用这些见解,我们将任务感知3D场景理解表述为将任务不可知原语 压缩成任务相关概念的簇 的问题,这些概念对任务Y具有最大的信息量。这自然引出了信息瓶颈原理。
任务感知3D场景理解作为信息瓶颈。类似于著名的信息瓶颈(IB)[13]的设置,我们有一个原始信号 (即任务不可知原语的集合),它为信号 (即任务列表)提供了一些信息。我们的目标是找到一个更紧凑的信号 ——代表任务相关概念——压缩 的同时保留任务相关信息。
数学上,我们将定义任务相关聚类 ,使用概率分布,这代表一个任务不可知原语在 中属于聚类在 中的概率。IB将计算任务相关聚类 (或等价地,概率)表述为以下优化问题的解:
其中 表示两个随机变量之间的互信息(the mutual information between two
random variables)。直观上,问题(1)
- 通过最小化原始信号 和压缩信号 之间的互信息来压缩 ,
- 同时通过压缩信号 和任务 之间的互信息来奖励压缩表示的任务相关性。
参数 控制这两个项之间的期望平衡(即,压缩量)。
(1)的结果是一组聚类:直观上,这些聚类在正确的粒度下根据任务要求将3D片段组合成对象,将 3D places 组合成区域(例如,房间)。
以下,我们讨论可以更好地利用我们问题的结构的算法,并阐明如何在实践中计算(1)中出现的分布和互信息项。
重要
互信息是衡量两个随机变量之间相互依赖程度的量,它量化了一个随机变量包含关于另一个随机变量的信息量。互信息可以告诉我们在已知一个随机变量的情况下,对另一个随机变量的不确定性减少了多少。数学上,两个随机变量 和 之间的互信息 定义为:
其中:
- 是 和 的联合概率分布,
- 是 的边缘概率分布,
- 是 的边缘概率分布,
- 对数通常以2为底,此时互信息的单位是比特。
互信息也可以用条件熵来表示:
其中 和 分别是 和 的熵,而 和 分别是给定 时 的条件熵和给定 时 的条件熵。
互信息是信息论中的一个基本概念,在机器学习、信号处理、通信系统等多个领域都有应用。它被用来评估变量之间的依赖性、在数据分析中选择特征,以及评估信息检索系统的性能等。
4. 任务驱动聚类
在我们的问题中,任务不可知原语具有几何属性,这为我们的聚类提供了强大的归纳偏置(即,我们可能想要合并附近的片段,并避免合并相距甚远的片段)。为了强化这种归纳偏置,我们考虑并扩展了聚合IB方法[14],它通过迭代合并相邻原语来形成任务相关聚类。在本节中,我们首先提供有关聚合IB的相关背景,然后提出一个增量版本的聚合IB算法以支持实时映射,最后将IB表述适应于使用开放集视觉-语言特征进行任务感知场景理解。
聚合信息瓶颈
聚合IB方法是一种自下而上的合并方法,用于解决IB问题[14]。该方法将任务相关聚类 初始化为任务不可知原语 ;然后,在每次迭代中,它使用任务驱动的度量(task-driven metric)合并相邻聚类。特别是,它计算每个可能合并相邻聚类 和 的权重:
其中 是杰森-香农散度。直观上,权重 是两个聚类的概率分布差异的度量。具体来说,算法迭代合并具有最小权重的聚类,从而以贪婪的方式解决 IB。
这个过程可以被理解为迭代合并图中的邻近节点,其中图的边代表允许的合并。正如[14]中建议的,在每次迭代 ,我们还计算
作为合并操作对应的信息损失的分数度量,并在 超过阈值 时终止算法。 调节压缩量,其中值为 0 返回原始原语集合,值为1返回完全合并的原语,与方程(1)中的参数 扮演类似的角色。算法的伪代码在附录A中给出。
重要
在信息瓶颈(Information Bottleneck, IB)算法的上下文中,"合并操作对应的信息损失的分数度量"(fractional loss of information corresponding to a merge operation)是指在将两个或多个对象原语(primitives)合并成一个聚类时,所导致的关于任务信息的损失量。这个度量用于评估每次合并操作对保留任务相关信息的影响。
具体来说,这个分数度量是通过计算合并前后的互信息(mutual information)差异来得到的。互信息是衡量两个随机变量之间共享信息量的指标。在IB算法中,我们希望找到一个压缩表示(即聚类),它在尽可能减少表示的复杂度的同时,保留尽可能多的关于任务(Y)的信息。
合并操作的信息损失分数度量的计算公式如下:
其中:
- 是在第k次合并操作后,压缩表示 与任务 之间的互信息。
- 是在第k次合并操作前,压缩表示 与任务 之间的互信息。
- 是原始表示 与任务 之间的互信息。
表示第 次合并操作导致的互信息减少量占原始互信息总量的比例。这个比例越小,说明合并操作导致的信息损失越小,即保留的任务相关信息越多。
在IB算法中,这个分数度量用于决定是否执行合并操作。如果 超过一个预设的阈值 ,则停止合并操作,认为当前的聚类已经足够好,能够保留关于任务的足够信息。这个阈值 是一个超参数,用于控制压缩表示的粒度和信息保留量之间的平衡。
综上所述,合并操作对应的信息损失的分数度量是IB算法中一个关键的评估指标,用于指导算法在压缩表示的同时,尽可能保留关于任务的有用信息。
增量聚合IB。
在我们的问题中,我们预计地图将随着时间的推移而增长,因此至关重要的是要限制聚合IB的计算复杂度。为了实现这一目标,我们提出了一个增量版本的算法,可以在线执行,随着机器人探索环境。
我们的关键观察是,如果输入算法的原语图有多个连通分量(例如,不同房间中的3D对象片段),则聚类可以在每个连通分量上独立执行(直观上,不同分量之间没有边,因此没有潜在的合并)。
此外,可以很容易地证明,方程(3)中的变量 可以独立于不受新测量影响的连通分量进行计算,并且不需要为不受影响的连通分量重新计算。这允许机器人在映射环境时增量聚类,同时支持实时流的新原语。我们报告了我们增量算法的伪代码在附录B中,而接下来我们讨论如何设置所需的分布。
重要
在本文中提到的“独立于不受新测量影响的连通分量进行计算”是指在信息瓶颈(IB)算法的增量版本中,算法只会对那些受到新测量(即新的传感器数据或图像帧)影响的图的连通分量进行更新和计算。这意味着,如果某些连通分量没有受到新数据的影响,那么算法就不会对这些部分进行重新计算或聚类,从而节省计算资源并提高效率。
具体来说,这里的几个关键概念包括:
连通分量(Connected Components):
- 在图论中,连通分量是指图中的一组顶点,这些顶点之间相互可达,与其他顶点则不连通。在3D场景理解中,连通分量可能代表不同的物理区域或对象群组。
新测量的影响:
- 当新的测量数据(如新的RGB-D图像帧)到来时,只有与这些数据直接相关的连通分量需要被更新。例如,如果新帧中只出现了新的对象或场景的一部分,那么只有与这些新出现的对象或场景部分相关的连通分量需要被考虑。
独立计算:
- 对于那些没有受到新测量影响的连通分量,算法不需要重新计算它们的聚类或更新它们的表示。这样可以避免不必要的计算,特别是在动态环境中,新数据可能只影响场景的一小部分。
效率提升:
- 这种方法允许算法在实时或近实时系统中高效运行,因为它减少了需要处理的数据量,并且只关注那些真正变化的部分。
实时系统的应用:
- 在机器人或自动驾驶车辆等实时系统中,这种策略特别有用,因为这些系统需要快速响应环境变化,同时处理大量的传感器数据。
综上所述,“独立于不受新测量影响的连通分量进行计算”是一种优化策略,它使得信息瓶颈算法能够更加高效地处理动态环境中的数据流,只对那些真正需要更新的部分进行计算,从而提高了算法的实时性能和计算效率。
任务相关条件分布。
聚合IB算法要求定义条件概率p(y|x),这可以被理解为每个原语的任务相关性。
我们使用CLIP[11]为每个原语 和每个任务 产生嵌入 和 。
对于每个原语 ,我们计算其与所有任务嵌入的余弦相似性分数 。
我们进一步添加一个空任务 ,并分配一个分数 ,这被选为在任何给定任务下原语不相关的余弦相似性的下限。
我们对具有与空任务最高相似性的原语执行预修剪步骤,对于这些原语,我们将 设置为 one-hot 向量,对空任务有1的概率。
此外,为了强调任务相似性的排名,我们将不在前k个最相似任务中的所有任务相似性设置为0,并将前 个任务乘以 。
正式地,给定 个任务,我们首先定义 :
然后以 的形式写出 :
其中 是归一化常数, 仅保留前 个值,将所有其他值设置为 0。这种 的选择有效地为CLIP嵌入中余弦相似性最高的 个任务分配了 中的大值,同时也将不相关的原语分配给空任务。鉴于这种条件概率的选择,聚合IB计算聚类 。
5. Clio: 实时任务驱动开放集3D场景图
本节描述了Clio,我们的实时系统,用于构建任务驱动的开放集3D场景图。图3展示了高层次的架构。Clio由两个主要组件组成:前端,负责构建任务不可知的对象和地点原语,以及后端,执行任务驱动的对象和区域聚类。
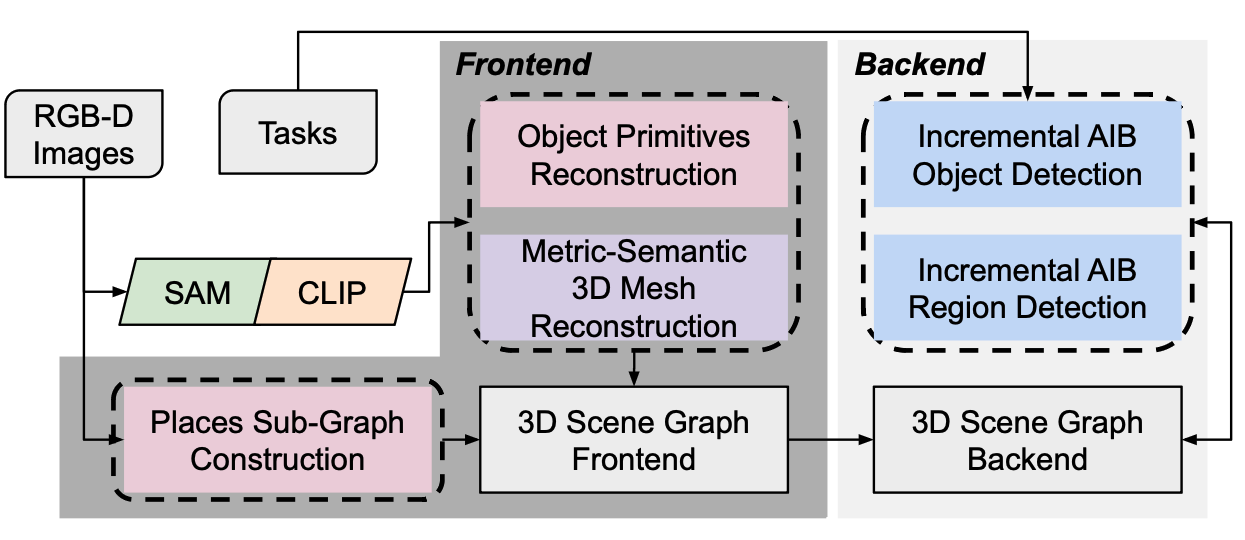
图3. Clio的前端接收RGB-D传感器数据,并构建对象原语的图、地点的图以及背景的度量-语义3D网格。 Clio的后端执行增量聚合IB(Iterative Bundle Adjustment,迭代捆绑调整)来根据用户指定的任务列表对对象和区域进行聚类。
A. Clio前端
3D对象原语。
我们遵循Khronos[61]的方法进行3D网格重建和对象原语提取。
给定RGB-D图像流和姿态,我们运行FastSAM[27]和CLIP以获得每个图像的语义分割。
然后,我们在时间窗口 内将分割segments与现有track关联起来。
- 为了保持一致性,候选track需要与segment的余弦相似度高于阈值 ,并且与segment的3D IoU至少为 。
- 每个新segment然后贪婪地关联到 最高的候选轨迹。如果没有关联,就创建一个新的track。
- 最后,如果一个track在 秒内没有被关联,它将被终止。然后,每个轨迹根据轨迹中的所有帧重建成3D对象原语,并通过平均计算最终的CLIP特征。
同时,对每个传入的帧进行背景的粗糙重建。
- 这种方法允许我们以有限的计算量增量构建密集的3D模型,同时保持对象原语的高细节。
3D地点原语
我们遵循Hydra[7]的方法构建地点子图。
- 我们递增地计算场景的广义Voronoi图Generalized Voronoi Diagram,并将其稀疏化为地点图。
- 为了获得地点的语义特征,我们为提供给Clio的每个输入图像计算CLIP嵌入向量。
- 然后,每个地点节点被分配一个特征,该特征是所有输入图像中节点中心可见的CLIP嵌入的平均值。
我们在第VI-C节验证了这些设计选择。
B. Clio后端
任务驱动对象检测。
Clio在前端过度分割的3D对象原语上运行我们的聚合IB方法。作为IB的输入,我们构建一个图,其中节点是对象原语,并在相应的原语的3D边界框有非零重叠时添加边。我们如方程(5)中所述计算 。在这种情况下,空任务可以被视为背景任务无关对象。我们设置 。
重要
这句话是在描述信息瓶颈(Information Bottleneck, IB)算法中图的构建过程。具体来说,这句话的意思是:
在将信息瓶颈算法应用于任务驱动的3D场景理解时,首先需要构建一个图(graph),这个图的节点(nodes)代表的是3D场景中的对象原语(object primitives)。对象原语是指在场景中识别出的基本对象单元,它们是任务驱动聚类的基础。
接着,对于这些对象原语,算法会在它们之间添加边(edges),这条边表示两个对象原语之间存在一定的空间关系。在这里,边是在两个节点之间添加的,如果这两个节点对应的对象原语的3D边界框(3D bounding boxes)有非零的重叠区域,即它们的物理空间有交集。换句话说,如果两个对象在3D空间中相互接触或接近到一定的程度,算法就会认为它们之间存在关系,并在图的相应节点之间添加一条边。
这样的图表示方法可以帮助算法理解和学习对象之间的空间关系,进而在信息瓶颈框架下进行任务相关的聚类和压缩,以构建出既紧凑又能够保留完成任务所需信息的3D场景图。
我们提供两个版本的Clio。
第一个,Clio-batch,假设所有原语的整个场景已经生成,然后使用方程(3)聚类所有对象片段。
第二个,Clio-online,实时接收图像流并使用我们的增量IB算法构建地图,其中仅对受最新测量影响的连通分量再次执行聚类。
任务驱动地点聚类。
Clio在每个后端更新时执行聚合IB,将地点原语节点聚类成区域,其中地点图中的每条边被视为潜在的合并对象。我们以与对象相同的方式计算任务和地点节点之间的p(y|x)。
6. 实验
我们的实验表明,Clio(i)构建了更简洁且有用的地图表示(第VI-A节),(ii)在任务由封闭词典隐式指定的封闭集设置中与最新技术持平(第VI-B节),(iii)能够将环境聚类成有意义的语义区域(第VI-C节),并且(iv)能够在真实机器人上支持任务执行(第VI-D节)。
A. 开放集对象聚类评估
实验设置
为了在真实多样的场景中测试Clio,我们收集了四个数据集,涵盖办公室、公寓、隔间和大型大学建筑,包括五个楼层,包括机器车间、教室、休息室、会议室、杂乱的工作区和飞机库。
对于办公室、公寓和隔间数据集,我们手动注释了与给定任务集相关联的对象的3D边界框。为了评估目的,选择的任务是对于构成任务最佳对象集有明确定义的,以减少对构成对象的主观推理。任务的完整列表在附录D至G中提供。
指标
由于传统的指标如精确度和召回率不能完全捕捉开放集对象检测的性能,我们引入了两个新指标:开放集召回率(osR)和开放集精确度(osP)。
对于osR,我们为每个任务查询n个最佳对象,其中n是与任务相关的真值对象的数量,并报告正确检测的数量除以真值对象的数量。我们定义osP为至少有90%余弦相似度得分的任务最相似对象的总正确检测数除以总检测数。对于两个指标,我们说如果估计对象的边界框包含真值边界框的质心,并且真值对象的边界框包含估计边界框的质心,则检测是严格的;如果至少满足这两个条件中的一个,则检测是宽松的。直观上,在最坏情况下,宽松的检测可以用无限大的估计边界框满足,而严格的检测可以排除与真值有实质性重叠的估计。
我们报告两个标准的F1分数,并包括平均IOU的顶部n个最相关估计对象、估计对象的总数(Objs)和每帧处理的平均运行时间(TPF)。
Compared Techniques
由于我们的查询不包括否定或多步可供性,我们运行ConceptGraphs,仅使用CLIP代替LLava+GPT,因为在[9]中显示CLIP对这些类型的查询具有类似的性能。
除了运行ConceptGraphs和Clio,我们还测试了:Khronos,它执行[61]中描述的聚类,参数θtrack = 0.7和γ = 0.4,以及Clio-Prim,它只计算Clio输入的3D对象原语集合,参数θtrack = 0.9和γ = 0.6;本质上,ClioPrim是Clio前端的输出,因此这种比较允许评估Clio中IB聚类的有效性。
为了显示任务驱动的重要性,我们进一步包括了基线的的任务感知版本:Khronos-task和ConceptGraphs-task,它们取Khronos和ConceptGraphs的结果,并移除与提供的任务列表中至少一个任务的余弦相似度不够高(α = 0.23)的映射对象。我们包括了Clio-batch的结果,它接收场景的所有原语,并在映射会话结束时只执行一次,以及Clio-online,它实时接收原语以进行实时映射。我们使用CLIP模型ViT-L/14,并使用RTX 3090 GPU和Intel i9-12900K CPU生成结果。结果如表I所示。使用OpenCLIP模型ViT-H-14的结果包括在附录H中。
结果
首先,我们观察到任务感知方法(表I中蓝色阴影行)导致开放集精确度提高,并保留了更少的对象数量(“Objs”列);这激励了我们的观点,即度量-语义映射需要是任务驱动的。特别是,在某些情况下,Clio与任务不可知基线相比保留了一个数量级更少的对象(与ClioPrim中的对象数量相比,后者本质上是没有信息瓶颈任务驱动聚类的Clio)。我们观察到任务感知基线Khronos-task和ConceptGraphs-task在开放集召回率上严格比它们的任务不可知版本差,因为两者都使用任务感知来过滤掉不相关的对象(提高了开放集精确度),但无法在形成对象时考虑任务(例如,确定一堆笔记本是一个对象还是多个)。这激励了我们的任务感知聚类方法,因为我们观察到Clio通常在所有数据集和所有指标上都优于基线,Clio-batch和Clio-online在除了2个案例之外的所有情况下都排名第一或第二,即办公室数据集中的IOU和严格开放集召回率。办公室数据集中的许多对象(例如,订书机,自行车头盔)通常被检测为孤立的原语,因此我们可以看到任务知识对这一数据集的影响较小,尽管仍然在所有其他指标上提高了性能。
第三,我们观察到Clio可以在几分之一秒内运行,比ConceptGraphs快约6倍;Khronos和Clio-Prim也在实时运行,但在其他指标上表现不佳。
最后,Clio-batch和Clio-online在大多数情况下性能相似。它们的性能差异是由于Clio-online实时执行,可能需要丢弃帧以跟上图像流。这种差异有时有助于性能指标,有时则有害。
例如,Clio能够使用任务信息形成适当的场景表示,图4显示了Clio针对两组不同任务的检测对象的子集。对于涉及获取所有调味品包的任务,Clio将不同类型的调味品包集体表示为一个对象,而对于需要特定类型调味品的替代任务集,Clio将堆表示为按酱类型区分的多个对象,从而得到更灵活和有用的场景表示。大型五层建筑数据集的定性结果包括在视频附件中。
B. 封闭集对象评估
虽然Clio旨在进行开放集检测,但我们在封闭集Replica[17]数据集上包括结果,使用[8, 9]执行的评估方法,以表明我们的任务感知映射表述不会降低封闭集映射任务的性能。在这里,我们的任务列表是每个Replica场景中出现的每个对象标签,其中每个标签被更改为“{class}的图像”,遵循[9]。在创建场景图之后,我们为每个检测到的对象分配
具有最高余弦相似度的标签。为了提高CLIP在Replica数据集的低纹理区域的可靠性,我们为Clio包括了[62]中的密集CLIP特征的全局上下文CLIP向量。我们报告准确性作为类别平均召回率(mAcc)和频率加权平均交并比(f-mIOU)。表II显示Clio在mAcc上实现了与领先方法相当的性能,表明我们的任务感知聚类不会降低封闭集任务的性能。OpenMask3D[50]利用3D分割网络,因此在fmIOU方面性能优越,但需要访问场景的完整3D重建,限制了实时应用。
C. 开放词汇地点聚类
由于手动标记开放集3D区域是一项高度主观的任务,我们通过代理封闭集任务评估Clio的区域性能,其中Clio被提供场景的可能房间标签作为任务。我们在三个数据集:办公室、公寓和建筑中标记房间。我们没有分析隔间或Replica[17],因为它们只包含一个房间。我们设置α = 0,以禁用分配给空任务,因为每个地点都与至少一个房间标签相关。
数据集 方法 精确度↑ 召回率↑ F1↑
公寓 Hydra 0.93 ± 0.01 0.87 ± 0.01 0.90 ± 0.00 Clio (最近) 0.87 ± 0.06 0.78 ± 0.02 0.82 ± 0.01 Clio (平均) 0.98 ± 0.02 0.54 ± 0.00 0.69 ± 0.00
办公室 Hydra 0.61 ± 0.03 0.84 ± 0.03 0.70 ± 0.01 Clio (最近) 0.67 ± 0.03 0.79 ± 0.01 0.72 ± 0.01 Clio (平均) 0.73 ± 0.01 0.80 ± 0.00 0.76 ± 0.01
建筑 Hydra 0.87 ± 0.01 0.71 ± 0.02 0.78 ± 0.01 Clio (最近) 0.72 ± 0.04 0.82 ± 0.01 0.77 ± 0.02 Clio (平均) 0.79 ± 0.02 0.84 ± 0.01 0.81 ± 0.01
表III。几何房间分割准确性比较。
我们使用[7]中介绍的精确度和召回率指标来评估我们提出的CLIP嵌入向量关联策略Clio(平均)的预测房间的几何准确性。我们将其与替代策略Clio(最近)进行比较,该策略使用地点节点可见的最近图像中的嵌入向量,以及Hydra[7]的纯几何房间分割方法。结果比较在表III中展示,也包括了F1分数作为总结统计量。表III中的结果在5次试验中平均,报告了所有指标的标准差。我们注意到我们选择的关联策略在办公室和建筑场景中优于Hydra[7]的纯几何方法和更简单的Clio(最近),但在公寓中的F1分数表现相对较差。这是由于场景的性质;办公室和建筑场景包含标记的开放式平面房间,需要语义知识才能检测(例如,办公室场景中的小隔间或建筑场景中的楼梯井)。公寓主要包含几何上不同的房间,这些房间用[7]中的几何方法很容易分割,而Clio则过度分割,从我们方法的高精确度但低召回率中可以看出。另一方面,语义相似但相连的区域,如办公室中的场景,导致欠分割和比Hydra[7]更低的召回率。图5定性展示了Clio在办公室场景中产生任务相关区域的能力。我们比较了两种不同粒度的任务;第一种类似于封闭集代理评估中提供的房间标签,而第二种更细粒度且以对象为导向。结果区域反映了这种粒度差异,尽管Clio使用相同的一组参数产生。附录J中提供了更多支持Clio区域聚类有意义性的可视化。
D. 在Spot上的在线评估
为了演示Clio在机器人上的实时使用,我们使用装有手臂和夹持器的波士顿动力Spot四足机器人进行了移动操作实验。在实验中,机器人实时构建Clio地图,同时探索场景,然后被指派导航到并抓取与提供的自然语言提示匹配的对象(例如,图2)。然后我们通过Dijkstra算法计算通过地点节点到达目标对象的最短路径。到达目标对象后,我们选择当前输入语义片段中与提示嵌入余弦相似度最高的像素质心作为输入到Spot API抓取命令。我们使用Spot的前置左和前置右RGB-D摄像机和里程计作为Clio的输入。我们在一台可以安装在机器人上的笔记本电脑上运行Clio,该笔记本电脑配备了Intel i9-13950HX CPU,具有24个核心,64GB的RAM,以及NVIDIA GeForce RTX 4090笔记本电脑GPU。我们进行了7次移动操作实验。每次试验包括一个映射阶段和一个规划阶段。
在映射阶段,我们远程操作Spot观察场景中的所有对象(由两个类似房间的区域组成,通过一个走廊连接)。映射阶段结束后,我们将Spot移动到规划阶段的起始位置,在那里我们命令抓取3个随机目标对象,总共进行了21次独特的抓取尝试。Clio在每次试验期间一直运行,没有对3D场景图进行后处理。我们在图6中展示了21次试验的分解。总体上,我们实现了57%的抓取成功率,如果我们不考虑Spot未能实际抓取正确识别对象的情况,成功率为71%。值得注意的是,Clio在场景图中仅选择了一次错误的目標对象(即“错误对象”失败类别)。视频附件还展示了一个涉及4次拾放动作的更大区域的拾放实验,其中Spot在笔记本电脑机载操作。这些实验共同强调了Clio适用于实际机器人平台。
VII. 限制
尽管实验结果令人鼓舞,但我们的方法有多个限制。
首先,虽然我们的方法可以零样本学习,不受任何特定基础模型的约束,但它确实继承了实现中使用的基础模型的一些限制,例如对提示调整的强大敏感性。例如,在附录H中,我们讨论了不同CLIP模型对性能的影响。
其次,我们目前平均CLIP向量时合并两个原语,但考虑更基础的方法来组合语义描述将是有趣的。
第三,Clio可能会过度聚类,如果两个原语单独对同一个任务有类似的余弦相似度,但任务要求将它们区分为不同的对象(例如,我们可能想要在设置餐桌时区分叉子和刀子,即使它们可能对任务有类似的相关性)。
最后,我们目前考虑的是相对简单的单步任务。然而,将提出的框架扩展到一组高级、复杂的任务将是可取的,包括需要对对象部分有大量理解的任务。
VIII. 结论
我们提出了一个任务驱动的3D度量-语义映射表述,其中机器人被提供了自然语言任务列表,并且必须创建一个地图,其粒度和结构足以支持这些任务。我们已经展示了这个问题可以用经典的信息瓶颈来表达,并开发了一个增量版本的聚合信息瓶颈算法作为解决策略。我们将得到的算法集成到了一个实时系统中,Clio,它在机器人探索环境时构建一个3D场景图——包括任务相关对象和区域。我们还通过展示Clio可以实时在Spot机器人上执行并支持捡取和放置移动操作任务,来证明Clio与机器人的相关性。