
Hydro
Hydra: A Real-time Spatial Perception System for 3D Scene Graph Construction and Optimization
摘要
3D场景图最近作为一种强大的3D环境高级表示形式出现。3D场景图将环境描述为一个分层图,其中节点代表多个抽象层次的空间概念(从低层次的几何形状到包括对象、地点、房间、建筑物等高层次的语义),边缘代表概念之间的关系。尽管3D场景图可以作为机器人的高级“心智模型”,但如何在实时构建这样的丰富表示仍然是未知领域。
本文描述了一个实时空间感知系统,这是一套算法,用于从传感器数据中实时构建3D场景图。
我们的第一个贡献是开发实时算法,以增量方式构建场景图的层,因为机器人探索环境;这些算法在机器人当前位置周围构建局部欧几里得有符号距离函数(ESDF),从ESDF中提取地点的拓扑图,然后使用受社区检测技术启发的方法将地点分割成房间。
我们的第二个贡献是研究3D场景图中的环路闭合检测和优化。我们展示了3D场景图允许定义层次化的环路闭合检测描述符;我们的描述符捕获跨场景图层次的统计数据,从低层次的视觉外观到关于对象和地点的汇总统计数据。
然后我们提出了第一个算法,以响应环路闭合来优化3D场景图;我们的方法依赖于嵌入式变形图,同时校正场景图的所有层。
我们将提出的空间感知系统实现到一个高度并行化的架构中,命名为Hydra1,它结合了快速的早期和中级感知过程(例如,局部映射)与更慢的高级感知(例如,场景图的全局优化)。我们在模拟和真实数据上评估Hydra,并表明它能够在线重建3D场景图,精度与批量离线方法相当。
索引术语—机器人感知、3D场景图、定位和映射、实时场景理解。
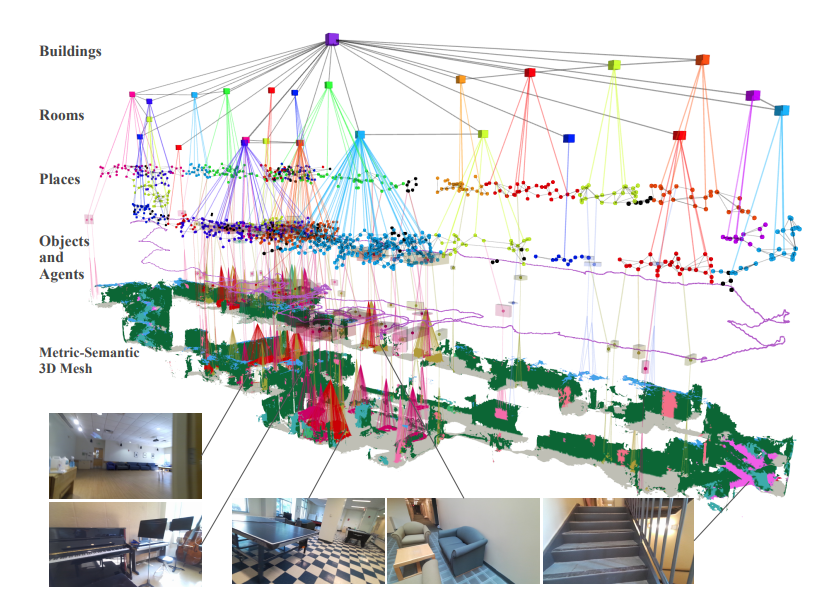
图1. 我们展示了Hydra,一个高度并行化的架构,用于实时从传感器数据构建3D场景图。图中显示了示例输入数据和Hydra在大型真实环境中创建的3D场景图。
I. 引言
下一代机器人和自主系统将需要实时构建未知环境的持久性高级表示。对于机器人来说,高级表示是理解和执行人类指令(例如,“把我留在餐厅桌子上的茶杯拿给我”)所必需的;高级表示还使得快速规划成为可能(例如,通过允许在紧凑的抽象上进行规划,而不是密集的低级几何形状)。这些表示必须实时构建以支持即时决策制定。此外,这些表示必须是持久的,以支持长期自主性:(i)它们需要扩展到大型环境,(ii)它们应该允许机器人收集新证据时进行更正,(iii)它们的大小应该只随着它们建模的环境的大小增长。3D场景图[4, 26, 49, 50, 63, 67]最近作为一种强大的3D环境高级表示形式出现。3D场景图(图1和图6)是一个分层图,其中节点代表多个抽象层次的空间概念(从低层次的几何形状到对象、地点、房间、建筑物等)和边缘代表概念之间的关系。Armeni等人[4]在计算机视觉中首次使用3D场景图,并提出了将度量语义3D网格解析为3D场景图的首批算法。Kim等人[26]重建了对象及其关系的场景图。Rosinol等人[49, 50]提出了一种新的3D场景图模型,该模型(i)直接从传感器数据构建,(ii)包括地点子图(对机器人导航有用),(iii)模拟对象、房间和建筑物,以及(iv)捕获环境中的移动实体。更多近期的工作[22, 25, 63, 67]从点云、RGB-D序列或对象检测中推断对象和关系。
尽管3D场景图(scene graphs)可以作为机器人的高级“心智模型”,但如何在实时构建这样的丰富表示仍然是未知领域。作品[26, 63, 67]允许实时操作,但仅限于“平面”3D场景图,主要关注对象及其关系,同时忽视了图1中的顶层。
49: 3D DSG
如下缺点所写,非实时系统
使用 Voxblox 构建全局 ESDF,使用 [78] 从 esdf 中抽象出 拓扑图 作为 “place”
不同语义实例:跟踪和关联同一实例,以确保其在 3d dsg 中的一致性
50: Kimera DSG
作品[4, 49, 50],重点关注构建真正的层次化表示,离线运行需要几分钟来构建3D场景图([4]甚至假设事先已经构建了正确且完整的环境度量语义网格)。
前作的缺点
将==我们之前的工作[49, 50]==扩展到实时操作并不平凡。
- 这些工作使用整个环境的欧几里得有符号距离函数(ESDF)来构建3D场景图。不幸的是,ESDF所需的内存随着环境大小的增加而扩展得很差[43]。
- 此外,[49, 50]中提取地点和房间的方法涉及批处理算法,这些算法处理整个ESDF,其计算成本随着时间的推移而增加,与实时操作不兼容。
- 最后,ESDF是根据机器人轨迹估计重建的,而轨迹估计会随着环路闭合而不断变化。因此,[49, 50]中的方法将需要在每次环路闭合后从头开始重建场景图,这与实时操作相冲突。
本文的主要动机是克服这些挑战,开发第一个实时空间感知系统,这是一套算法和实现,用于从传感器数据中实时构建分层的3D场景图,如图1所示。
我们的第一个贡献是开发实时算法,以增量方式重建机器人探索环境时的场景图层。提出的算法重建机器人周围的局部ESDF,并增量地将ESDF转换为度量语义3D网格以及可以从中快速提取地点拓扑图的广义Voronoi图。这种计算是增量的,无论环境的大小如何,都以恒定时间运行。我们的算法还使用受社区检测启发的快速且可扩展的房间分割方法,将地点图聚类成房间,仅需几毫秒。
我们的第二个贡献是研究3D场景图中的环路闭合检测和优化。我们提出了一种新颖的层次化环路闭合检测方法:提出的方法涉及(i)自上而下的环路闭合检测,使用层次化描述符(捕获场景图中各层的统计数据)来寻找假定的环路闭合和(ii)自下而上的几何验证,通过注册假定匹配来尝试估计环路闭合姿态。然后,我们提出了第一个算法,以响应环路闭合来优化3D场景图;我们的方法依赖于嵌入式变形图,同时校正场景图的所有层,即3D网格、地点、对象和房间。
我们最后的贡獻是开发实时架构和实现,并在具有挑战性的模拟和真实数据上演示结果的空间感知系统。特别是,我们提出了一个高度并行化的实现,命名为Hydra,它结合了快速的早期和中级感知过程(例如,局部映射)与更慢的高级感知(例如,场景图的全局优化)。我们在几个异构环境中评估Hydra,包括公寓大楼、办公楼和地铁站。
我们的实验表明,
(i)我们可以实时重建大型真实环境的3D场景图,(ii)我们的在线算法在精度上与批量离线方法相当,以及(iii)我们的环路闭合检测方法在检测到的环路闭合的数量和质量方面优于基于词袋和视觉特征匹配的标准方法。Hydra的源代码在https://github.com/MIT-SPARK/Hydra上公开可用。
II. 相关工作
度量语义和层次化映射
近年来,度量语义映射的兴趣激增,这一趋势同时受到传统3D重建和SLAM技术的成熟,以及深度学习为语义理解提供的新机会的触发。文献集中于基于对象的地图[10, 14, 41, 42, 53, 56]和密集地图,包括体积模型[23, 38, 40]、点云[6, 32, 61]和3D网格[48, 51]。一些方法结合了对象和密集地图模型[31, 39, 54, 68]。这些方法不关心估计更高层次的语义(例如,房间)并且通常返回可能不直接适用于导航的密集模型[44]。
第二条研究线专注于构建层次化地图模型。层次化地图自从机器人学的诞生以来就普遍存在[12, 28, 29, 62]。早期工作集中在2D地图上,研究层次化地图在度量和拓扑表示之间的明显分歧[18, 52, 70]。最近,3D场景图被提出作为3D环境的表达性层次化模型。Armeni等人[4]将环境建模为包括低层次几何形状(即度量语义网格)、对象、房间和相机位置的图。Rosinol等人[49, 50]在模型中增加了地点的拓扑图,以及描述环境中动态实体的层。[4, 49, 50]中的方法设计为离线使用。其他论文专注于重建对象及其关系的图[26, 63, 67]。Wu等人[67]使用图神经网络实时预测对象和关系。Izatt和Tedrake[25]使用混合整数规划将对象和关系解析到场景文法模型中。Gothoskar等人[22]使用MCMC方法。
一个有些平行的研究线调查了如何从2D或3D数据中解析建筑物布局。大量工作集中在解析2D地图[9],包括基于规则的[27]和基于学习的方法[34]。Friedman等人[16]从2D占用网格计算Voronoi图,然后使用条件随机场进行标记。最近的工作集中在3D数据上。Liu等人[34]和Stekovic等人[57]将3D点云投影到2D地图上,但这并不直接适用于多层建筑。Furukawa等人[17]结合多视图立体和曼哈顿世界假设从图像中重建楼层平面。Lukierski等人[37]使用从全方位相机的密集立体视觉拟合立方体到对象和房间。Zheng等人[71]通过在3D度量语义模型上执行区域增长来检测房间。
环路闭合检测和优化
机器人中视觉环路闭合检测的成熟方法可以追溯到计算机视觉中的地点识别和图像检索技术;这些方法在SLAM流程中被广泛采用,但已知会受到外观和视点变化的影响[36]。最近的方法研究了使用图像序列[20, 55]或深度学习[3]进行地点识别。与我们的提议更相关的是利用语义信息进行环路闭合检测的一系列论文。Gawel等人[21]使用从2D图像构建的随机游走描述符执行基于对象图的环路闭合检测。Liu等人[35]使用类似的基于对象的描述符,但是从3D重建中构建的。Lin等人[33]采用基于随机游走的对象描述符,然后通过对象注册计算环路闭合姿态。Qin等人[45]提出了一种基于子图相似性匹配的基于对象的方法。Zheng等人[71]提出了一个房间级别的环路闭合检测器。
环路闭合检测后,需要相应地校正地图。虽然在稀疏(例如,基于地标)表示中这个过程很简单[11],但在使用密集表示时实时执行这个操作是非平凡的。Stückler和Behnke[58]以及Whelan等人[66]优化了一个由surfels组成的地图,以避免需要校正结构化表示(例如,网格或体素)。Dai等人[13]在每次环路闭合后重新整合体积地图。Reijgwart等人[47]通过将地图分解为可以在环路闭合后刚性对齐的子图来校正体积表示中的漂移。Whelan等人[65]提出了一个两步优化,首先校正机器人轨迹,然后使用变形图方法[59]校正地图(表示为点云或网格)。Rosinol等人[50]将两个步骤统一为单一的姿态图和网格优化。这些工作都不涉及同时校正多个层次化表示。
III. 实时增量3D场景图层构建
本节描述了如何根据机器人轨迹的里程计估计(例如,来自视觉-惯性里程计)构建3D场景图的层。然后,第IV节讨论了如何响应环路闭合来校正图。我们专注于室内环境,并采用[49]中引入的3D场景图模型,并在图1和图6中可视化。在这个模型中,
- 第1层是一个度量语义3D网格。
- 第2层是对象和代理的子图;每个对象都有一个语义标签、一个质心和一个边界框,而每个代理由一个姿态图描述其轨迹(在我们的情况下,机器人本身是唯一的代理)。
- 第3层是一个地点的子图(基本上是一个拓扑图),其中每个地点是一个无障碍位置,地点之间的边表示直线可达性。
- 第4层是一个房间的子图,每个房间都有一个质心,边连接相邻的房间。
- 第5层是一个建筑物节点,连接到所有房间(我们假设机器人映射一个单一建筑物)。边连接每个层内的节点(例如,模拟地点或房间之间的可达性)或跨层(例如,模拟网格顶点属于一个对象,一个对象在某个房间,或一个房间属于一个建筑物)。
接下来,我们介绍如何构建第1-3层的方法(第III-A节)以及如何将地点分割成房间(第III-B节)。
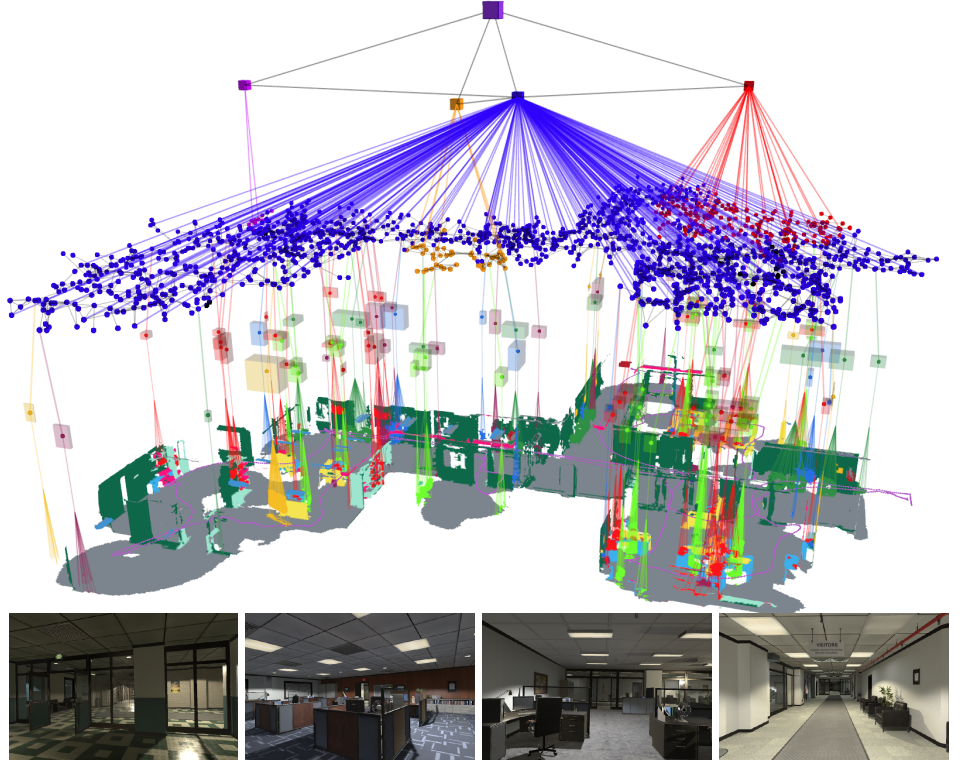
图6. Hydra在uH2办公室数据集中创建的3D场景图。
A. 第1-3层:网格、对象和地点
网格和对象
度量语义3D网格(3D场景图的第1层)的实时构建是Kimera[50]的扩展,有一些小但重要的修改。Kimera[50]使用Voxblox[43]将语义标记的点云集成到环境中的截断有符号距离场(TSDF)和ESDF中,同时还对每个体素的语义标签进行贝叶斯推断。
与Kimera[50]不同,我们在实现[43]的基础上,对TSDF和ESDF进行空间窗口化,并且只在用户指定的半径内(我们实现中为8米)形成机器人周围环境的体积模型;选择这个半径是为了限制ESDF使用的内存量。在这个“活动窗口”内,我们使用Voxblox的Marching Cubes实现提取3D度量语义网格和地点;当网格和地点移出活动窗口时,它们被传递到场景图前端(第IV节)。我们还修改了Marching Cubes算法,对对应于零交叉的TSDF体素进行标记(即,包含表面的体素);我们称这些体素为“父体素”,并跟踪相应的网格顶点。然后,对于每个ESDF体素——它已经存储了到最近障碍物的距离——我们还跟踪哪个父体素最接近体素。当从ESDF提取地点时,我们使用父体素将每个地点与3D网格中最近的顶点关联起来。
在活动窗口内提取3D网格后,我们通过对3D度量语义网格顶点进行欧几里得聚类来分割对象(3D场景图的第2层);具体来说,我们独立地对每个语义类别的顶点进行聚类。像Kimera[50]一样,欧几里得聚类的结果被用来估计每个假定对象的质心和边界框。在增量操作期间,如果一个假定的对象与场景图中相同语义类别的现有对象节点重叠,我们通过向先前的对象节点添加新的网格顶点将它们合并在一起;如果新对象不对应现有的对象节点,则作为新节点添加。
地点
Kimera[50]构建了一个整体ESDF环境,然后使用[44]提取地点子图(3D场景图的第3层)。
我们则实现了一种增量提取地点子图的方法,使用在ESDF集成过程中实时构建的广义Voronoi图(a Generalized Voronoi Diagram,GVD,如图2a所示)。
https://www.cnblogs.com/Zhouce/p/18525734
https://www.cnblogs.com/ticmis/p/17582154.html
GVD是与至少2个障碍物(“基点”或“父体素”)等距的体素集合,直观地形成了环境的骨架[44]。我们按照[30]中的方法,在活动窗口内ESDF集成过程中获得GVD作为副产品。特别是,属于GVD的体素可以很容易地从用于更新ESDF的刷火算法的波前中检测到。
在计算活动窗口的GVD后,我们通过修改[44]的批处理方法,增量地将GVD稀疏化为地点子图。直观地说,我们选择GVD的一个子集作为地点节点,并用边连接它们以形成地点图。
节点:
- 在GVD更新后,我们遍历每个新的GVD体素成员,如果有足够的基点(我们实现中为3个),则创建节点或边。如果新的GVD体素要么有足够的基点(即,≥4),或者如果体素的邻域与[44]提出用于识别角体素的模板匹配,则体素被视为节点。
为了识别节点之间的边,我们交替进行两个阶段。
- 首先,我们从上一次ESDF集成产生的标签开始,通过洪水填充将GVD体素标记为最近的节点ID,生成来自所有邻近节点ID的假定边集。addNeighborToFrontier
- 作为第二阶段,我们通过在GVD体素上插入一个新节点来分割假定边,其中直线边偏离连接两个节点的GVD体素太远,该GVD体素具有最大偏差。在第一阶段(洪水填充)期间,我们还合并附近的节点。经过固定次数的两个阶段迭代后,我们向稀疏图添加识别的边,并移除任何断开连接的节点。
- 最后,我们在活动窗口内添加额外的边以连接断开的组件,使地点子图连接。
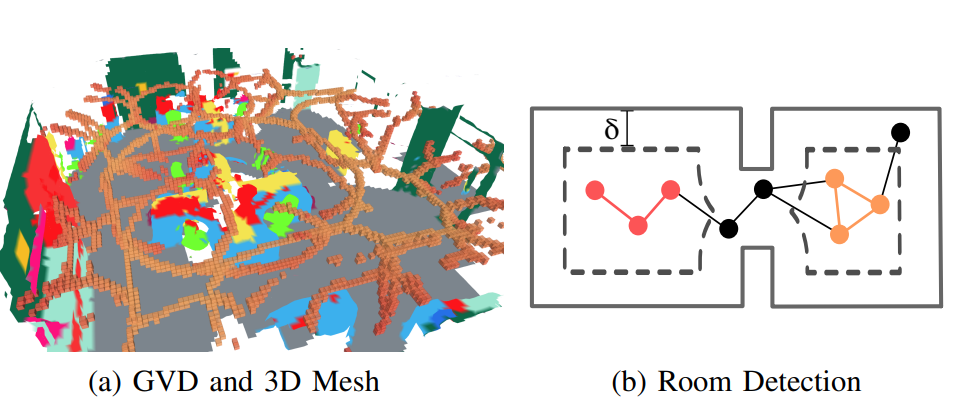
图2. (a) GVD(橙色块)和活动窗口内的网格。 (b) 房间检测:通过膨胀距离δ(墙壁以灰色显示,膨胀的墙壁以虚线显示,膨胀后消失的地方以黑色显示)在地点的子图中诱导的连通分量(橙色和红色)。
B. 第4层:房间检测
房间检测方法在Kimera[50]中需要整个环境的体积表示,并对房间几何形状做出假设(例如,天花板高度),这些假设不容易扩展到任意(可能是多层)建筑物。为了解决这些问题,我们提出了一种直接从地点稀疏子图分割房间的新方法来构建3D场景图的第4层。
我们的方法基于两个关键见解。
第一个是,对基于体素的地图进行膨胀操作有助于暴露环境中的房间:如果我们膨胀障碍物,环境中的小孔(即门)将逐渐关闭,自然地将基于体素的地图划分为断开的组件(即房间)。
第二个见解是,我们的地点子图中的每个节点都存储了到最近障碍物的距离(第III-A节);因此,对基于体素的地图进行膨胀操作可以直接映射到Gp中的拓扑变化。更精确地说,如果我们通过距离δ膨胀地图,每个障碍物距离小于δ的地方都将从图中消失(因为它将不再在自由空间中)。
图2b给出了这个想法的可视化。这些见解激发了我们检测房间的方法。我们通过增加距离δ(例如,在[0.45, 1.2]m中均匀间隔的10个距离)来膨胀地图。对于每个膨胀距离,我们通过丢弃距离小于δ的节点(及其边)来修剪地点子图;我们称修剪后的子图为Gp,δ。我们计算Gp,δ中的连通分量数量(直观地说,对于合适的δ选择,连通分量将对应于环境中的房间)。然后我们计算连通分量的中位数数量nr(以增强对δ选择的鲁棒性),并选择具有nr连通分量的最大Gp,δ*。*
最后,由于Gp,δ可能错过了原始图Gp中的一些节点,我们通过部分种子聚类技术对这些未标记的节点进行分配。具体来说,我们使用[8]中的贪婪模度基于社区检测方法,该方法涉及迭代地尝试将图中的每个节点分配给社区(即房间),以实现模度的最大增加。我们将初始社区设置为Gp,δ中检测到的连通分量,并且只迭代未标记的节点。这不仅产生了一致的结果,而且比相关技术(例如,谱聚类是聚类图的流行方法,但需要更昂贵的特征值分解的拉普拉斯算子Gp)具有更好的扩展性。
我们的新房间检测方法提供了两个优势。首先,对3D自由空间而不是2D占用网格(例如,[27])进行推理减少了环境中杂物的影响。其次,该方法的参数可以设置为适用于各种环境(即,两个主要参数是房间之间的最小和最大开口大小)。同时,我们的房间检测只对环境的拓扑进行推理;因此,它将无法分割在开放式平面图中语义上不同的房间。
IV. 持久表示:环路闭合检测和3D场景图优化
尽管上一节描述了如何增量构建一个“里程计”3D场景图(这些层是基于当前里程计估计构建的),本节描述了如何检测环路闭合(第IV-A节)以及如何在环路闭合后校正场景图(第IV-B节)。
A. 环路闭合检测和几何验证
我们通过使用场景图中的多个层来增强视觉环路闭合检测和几何验证。
自上而下的环路闭合检测。
3D场景图中的代理层存储了描述机器人轨迹的姿态图;我们称这些姿态为代理节点。
在我们的实现中,我们为每个代理节点存储了一个关键帧,从中可以提取外观信息。
环路闭合检测的目标是找到一个过去的代理节点,该节点与(即观察到与)当前机器人姿态对应的最新代理节点(最新代理节点)相同的场景部分。
对于每个代理节点,我们构建了一个描述节点周围环境的统计信息的层次化描述符,从低层次的外观到对象语义和地点几何。
描述符仅在新代理节点实例化时计算一次。
在最低层次,我们的层次化描述符包括标准的DBoW2外观描述符[19]。
我们用基于对象的描述符和基于地点的描述符来增强外观描述符(从代理节点周围半径内的对象和地点计算得出)。
前者是计算代理节点周围对象标签的直方图,直观地描述了附近的对象集合。
后者是计算与代理节点周围每个地点相关联的距离的直方图,直观地描述了节点附近地图的几何形状。
在计算描述符时,我们还跟踪了代理节点周围对象和地点的ID,这些ID用于几何验证。
在环路闭合检测时,我们比较当前(查询)节点与所有过去代理节点描述符的层次化描述符,寻找匹配项。在执行环路闭合检测时,我们从地点描述符走到对象描述符,再到外观描述符,一路向下比较描述符。
具体来说,当我们比较两个节点的描述符时,我们比较地点描述符,如果描述符距离低于阈值,我们继续比较对象描述符,然后是外观描述符。如果任何描述符比较返回一个假定的匹配项,我们执行几何验证;见图3的可视化总结。
自下而上的几何验证。
在我们在查询和匹配代理节点(比如说i和j)之间有一个假定的环路闭合之后,我们尝试通过执行自下而上的几何验证来计算两个之间的相对姿态。具体来说,每当我们在给定层有一个匹配项时(例如,在代理层的外观描述符之间,或在对象层的对象描述符之间),我们尝试注册框架i和j。对于视觉特征的注册,我们使用标准的基于RANSAC的几何验证,如[48]中所述。
如果失败,我们尝试使用 TEASER++[69] 注册对象,丢弃那些也未能通过对象注册的环路闭合。这种自下而上的方法的好处是,那些未能通过基于外观的几何验证的假定匹配项(例如,由于视点或光照变化)可以在基于对象的几何验证期间成功地导致有效的环路闭合。第VI节实际上表明,提出的层次化描述符提高了检测到的环路闭合的数量和质量。
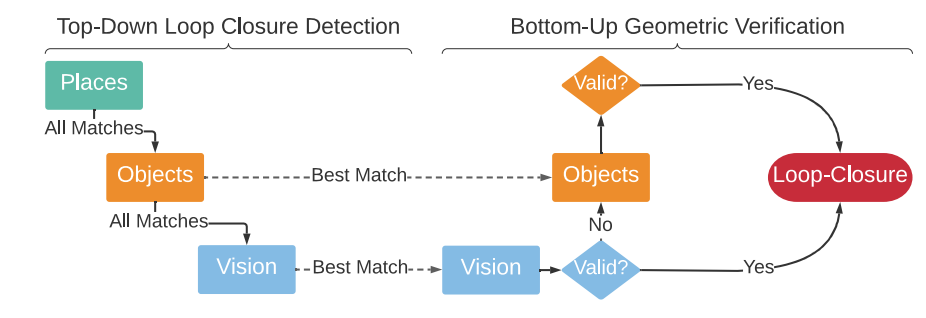
图3. 环路闭合检测(左图)和几何验证(右图)。为了找到匹配项,我们“下降”3D场景图的层级,比较描述符。然后我们“上升”3D场景图的层级,尝试注册。
B. 3D场景图优化
为了响应环路闭合,场景图前端“组装”第III节描述的模块的输出到一个单一的3D场景图中,然后场景图后端(i)使用变形图方法优化图,以及(ii)后处理结果以移除对应于机器人多次访问同一位置的冗余子图。
场景图前端。
前端构建了一个未校正漂移的初始估计的3D场景图。更准确地说,前端将第III节描述的模块的结果作为输入:最新的网格、地点子图、对象和代理的姿态图(全部窗口化到当前机器人姿态周围的半径内)。相应的节点和边被增量地添加到3D场景图数据结构中(存储直到当前时间的整个场景图)。然后,前端使用nanoflann[7]从每个对象或代理节点到活动窗口中最近的地点节点填充层间边。最后,前端计算一个简化版本的网格,该网格将在下面的变形图方法中被优化。通过基于八叉树的顶点聚类网格简化方法计算简化的网格,得到一个较小的节点子集(我们称之为网格控制点)和表示节点之间连接性的边。
场景图后端。
当检测到环路闭合时,后端优化由前端场景图构建的嵌入式变形图[59],然后通过插值重建场景图的其他节点,如[59](图4)中所述。更准确地说,我们通过以下方式形成变形图:(i)代理层,由包括里程计和环路闭合边的姿态图组成,(ii)网格控制点和相应的边,以及(iii)地点层的最小生成树。通过构造,这些层通过前端添加的层间边形成一个连接的子图。使用地点层的最小生成树的选择主要是出于计算原因:使用生成树保留了图的稀疏性。
嵌入式变形图方法将局部框架(即姿态)与变形图中的每个节点关联起来,然后解决一个优化问题,以调整局部框架,以最小化与每个边相关联的变形(包括环路闭合)。从长远来看,这一步将3D场景图的一个子图转换为一个因子图[11],其中需要最小化的边缘势能。我们参考[59]中关于优化的详细信息,并注意到我们使用了[50]中刚性变换的变形图重构(而不是[59]中的仿射变换),以获得一个标准的姿态图优化问题,适合现成的求解器。特别是,我们使用了GTSAM[2]中的Graduated Non-Convexity(GNC)求解器,它也能够拒绝错误的环路闭合作为异常值。
优化完成后,地点节点会更新到新的位置,并且整个网格将根据变形图方法[59]进行插值。然后我们重新计算对象的质心和边界框,根据新变形网格中相应顶点的位置。在更新过程中,还会合并重叠的节点:对于地点节点,我们在距离阈值内(我们实现中为0.4米)合并节点;对于对象节点,如果相应的对象具有相同的语义标签,并且一个节点包含在另一个节点的边界框内,则合并节点。我们维护一个场景图的版本,其中节点没有合并;这使得如果一个被接受的环路闭合后来被GNC视为异常值,可以撤销错误的环路闭合。最后,我们使用第III节中描述的方法,从合并的地点重新检测房间。
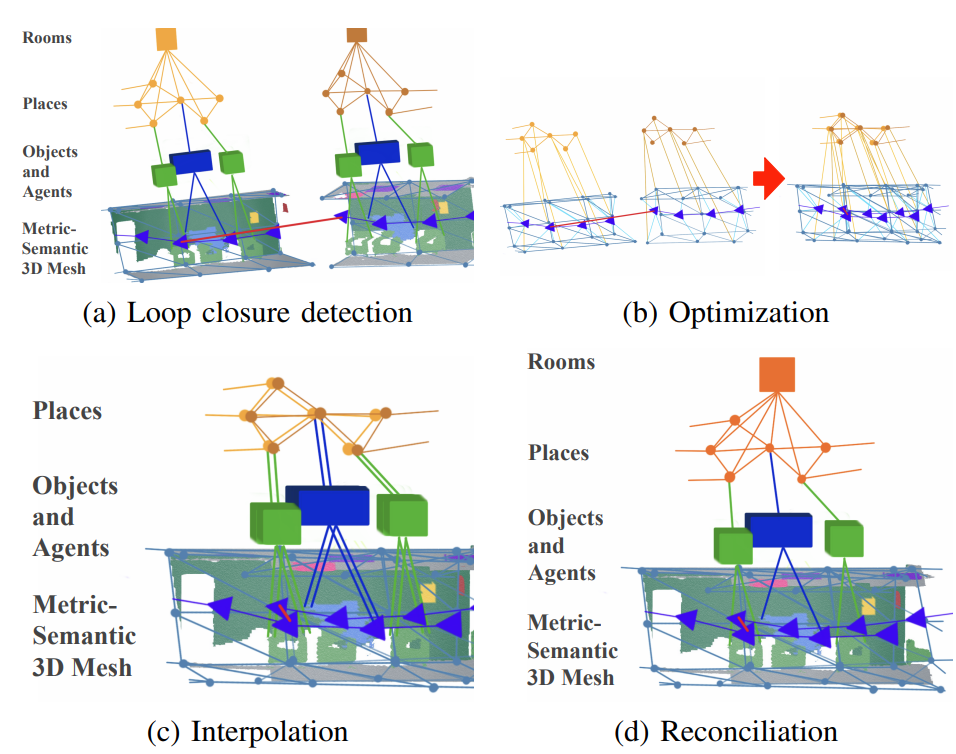
图4. 环路闭合检测和优化: (a) 在检测到环路闭合后, (b) 我们提取并优化3D场景图的子图——变形图——包括代理姿态、地点和网格顶点的一个子集。 (c) 然后我们通过插值重建图的其他部分,如[59]中所述,并且 (d) 协调重叠的节点。
V. 快速思考与慢速思考:Hydra架构
我们将空间感知系统实现为一个高度并行化的架构,命名为Hydra。
Hydra涉及一系列以传感器速率(例如,视觉-惯性里程计的前端)运行的过程,以亚秒速率(例如,网格和地点重建)运行的过程,以及以更慢速率(例如,场景图优化,其复杂度取决于地图大小)运行的过程。因此,这些过程需要被组织起来,以使慢但少有的计算(例如,场景图优化)不会妨碍更快的过程。
我们在图5中可视化Hydra。图中的每个块表示与前面章节讨论相匹配的算法模块。Hydra从快速的早期感知过程(图5,左)开始,执行诸如特征检测和跟踪(以帧速率)、2D语义分割和立体深度重建(以关键帧速率)等低级感知任务。早期感知过程的结果是传递给中级感知过程(图5,中)。这些包括算法,它们增量地构建(里程计版本的)代理层(例如,视觉-惯性里程计后端)、网格和地点层以及对象层。中级感知还包括场景图前端,它将其他模块的结果收集到一个“未优化”的场景图中。最后,高级感知过程执行环路闭合检测,执行场景图后端优化,并执行房间检测。这导致了一个全局一致的、持久的3D场景图。Hydra在多核CPU上实时运行;唯一依赖GPU计算的模块是2D语义分割,它使用标准的现成深度网络。在CPU上运行的优点是(i)将GPU留给面向学习的成分,以及(ii)与当前移动机器人所面临的功率限制兼容。
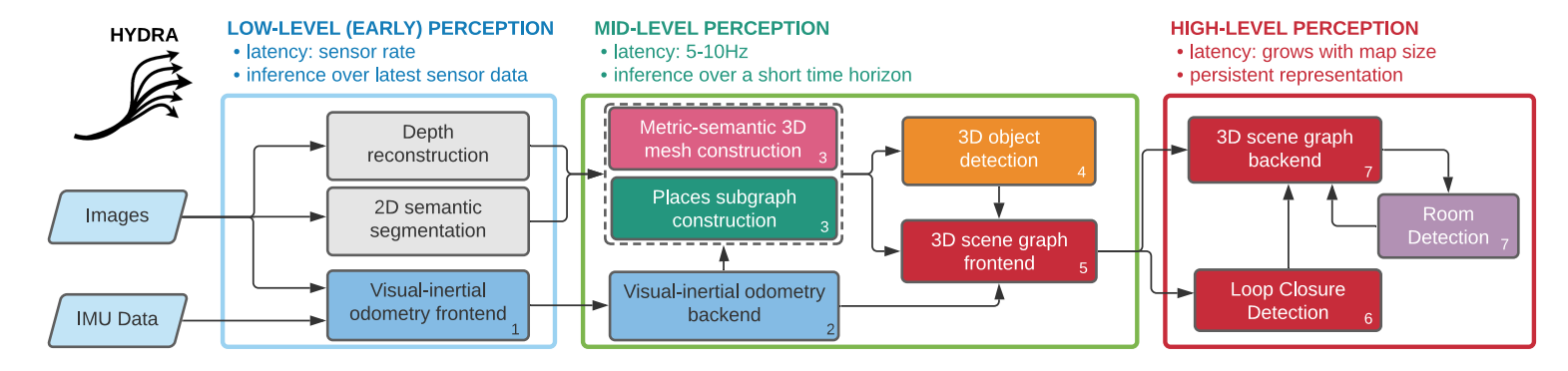
图5. Hydra的功能块图。我们将三个不同的功能块分组概念化为:低级感知、中级感知和高级感知,按延迟时间递增的顺序排列。每个功能块都标有数字,标识模块所属的“逻辑”线程。
VI. 实验
本节展示了Hydra能够实时构建3D场景图,并且精度与批量离线方法相当。
A. 实验设置
数据集。我们使用两个数据集进行实验:uHumans2(uH2)[50]和SidPac。uH2数据集是一个基于Unity的模拟数据集[50],包括三个场景:一个小公寓、一个办公室和一个地铁站。
数据集提供视觉-惯性数据以及地面真实深度和2D语义分割。数据集还提供了地面真实机器人轨迹,我们用于基准测试。
SidPac数据集是在研究生宿舍楼中使用视觉-惯性手持设备收集的真实数据集。我们使用Kinect Azure相机作为主要收集设备,并将Intel RealSense T265刚性地连接到Kinect以提供外部里程计输入。数据集包括两个独立的记录。第一次记录涵盖了两层楼(1楼和3楼),我们穿过研究生住所的一楼的公共休息室、音乐室和娱乐室,上楼梯,穿过长长的走廊以及三楼的学生公寓,然后下另一楼梯重新访问音乐室和公共休息室,最后回到起点。第二次记录也涵盖了两层楼(3楼和4楼),我们测绘学生公寓以及在两层都复制的休息室和厨房区域。这些场景特别具有挑战性,因为场景的规模(平均行走约400米)、玻璃和强烈阳光在场景区域的普遍存在(导致Kinect的部分深度估计)以及走廊中的特征贫乏区域。我们通过手动调整的姿态图优化和额外的高度先验获得了两个SidPac数据集的地面真实轨迹的代理,以减少漂移并定性地匹配建筑平面图。Hydra。对于真实数据集,我们使用Kinect的深度重建(见图5),我们使用HRNet[64]进行2D语义分割,使用MIT场景解析挑战[72]的预训练模型。虽然存在更新和更高性能的网络(例如,[5, 15, 24]),但很少有与我们的推理工具链(ONNX和TensorRT)兼容的ADE20k[72]预训练语义分割模型。
对于模拟数据集,我们使用提供的深度和分割。对于真实和模拟数据集,我们都使用Kimera-VIO[48]进行视觉-惯性里程计,并且在真实场景中我们将Kimera-VIO估计与RealSense T265的输出融合以提高里程计轨迹的质量。所有剩余的图5中的块都用C++实现,遵循本文中描述的方法。在实验中,我们使用了一个装有AMD Ryzen9 3960X的24核和两个Nvidia GTX3080的工作站,尽管我们还在本节末尾报告了在嵌入式计算机(Nvidia Xavier NX)上的计时结果。
B. 结果和消融研究
我们对实时方法的准确性和运行时间进行了广泛的评估,并与[50]中的批量离线场景图构建方法进行了比较。准确性评估:对象和地点。图7评估了对象和地点层,通过比较Hydra的三种不同配置。第一种配置(“GT轨迹”)使用地面真实姿态增量构建场景图。第二和第三种配置(“VIO+V-LC”和“VIO+SG-LC”)分别使用视觉-惯性里程计(VIO)进行里程计估计,然后使用基于视觉的环路闭合(VIO+V-LC)或提出的场景图环路闭合(VIO+SG-LC)。对于对象和地点的评估,我们考虑使用[50]从地面真实姿态构建的批量场景图作为地面真实场景图。对于对象层,我们报告两个指标:地面真实场景图中具有正确语义标签的估计对象的百分比(“%找到”)和估计场景图中具有正确语义标签的地面真实对象的百分比(“%正确”)。对于地点层,我们测量估计地点节点到地面真实GVD中最近体素的平均距离(“位置误差”)。图7中一些重要的趋势是,当使用GT-Trajectory时,Hydra的性能接近地面真实场景图(80-100%找到和正确的对象,亚25厘米地点位置误差)。这表明,给定轨迹,Hydra的实时场景图与批量和离线方法相当。其次,VIO+V-LC和VIO+SG-LC在对象和地点的准确性上保持了合理的水平,并在小型到中型场景(例如,公寓,办公室)中取得了可比的性能。在这些场景中,漂移很小,环路闭合策略不会显著影响性能(差异在标准差内,显示为黑色置信条)。然而,在更大的场景(例如,SidPac)中,环路闭合更为重要,VIO+SG-LC在对象准确性方面大大优于VIO+V-LC。重要的是,使用VIO+SG-LC通常会导致结果的标准差降低,证实了提出的场景图环路闭合检测方法可以带来更可靠的环路闭合结果(更多细节和消融在下面)。地点位置误差对于VIO+SG-LC和VIO+V-LC保持相似,并在包括更大开放空间和更远离地点子图中的节点的地铁站数据集中更大。
准确性评估:房间。图8评估了房间检测性能,使用[9]中定义的精度和召回率指标(这里我们在3D体素上而不是2D像素上计算精度和召回率)。更正式地,这些指标定义如下:
其中Re是估计房间的集合,Rg是地面真实房间的集合,|·|返回集合的基数;这里,每个房间re(或rg)被定义为一组自由空间体素。我们从环境的地面真实重建中手动标记地面真实房间Rg。具体来说,我们为每个房间手动定义一组边界框,并将落在每个房间内的独特(地面真实)标签分配给自由空间体素。对于估计的房间Re,我们从每个估计的房间中包含的地点派生出自由空间体素。在方程(1)中,精度然后测量每个估计房间与地面真实房间的最大重叠体素,召回率测量每个地面真实房间与估计房间的最大重叠体素。直观地说,低精度对应于欠分割,即更少且更大的房间估计,低召回率对应于过分割,即更多且更小的房间估计。为了基准测试,我们还包括[50]中的方法(Kimera)作为评估的基线。
图8显示,尽管Kimera[50]对办公室场景(唯一的单层场景)的房间分割估计与Hydra(GT-Trajectory)相似,Hydra在多层环境中表现出色。对于分层的公寓场景,我们实现了比Kimera更高的精度和召回率。对于SidPac楼层3-4,差异特别显著,Kimera只分割了10个地面真实房间中的2个,精度为0.88,召回率仅为0.06。总的来说,我们的方法估计了一个房间分割,精度和召回率一致(如果略有过分割),而Kimera在低精度和高召回率估计(即,极端欠分割)或高精度和低召回率估计(即,未能分割大多数房间)之间振荡。这些差异源于为Kimera设置适当的高度以尝试分割房间的困难。最后,值得注意的是,尽管存在漂移,我们的方法的房间分割方法仍然能够为VIO+SG-LC和VIO+V-LC保持相似的精度和召回率水平。
运行时间评估。图9报告了Hydra与[50]中的批量方法的运行时间。该图显示了批量方法的运行时间随时间增加而增加,并需要超过40秒来生成中等场景大小的整个场景图;正如我们提到的,批量方法[50]中的大多数过程涉及处理整个ESDF(例如,地点提取和房间检测),导致随着ESDF增长,运行时间线性增加。另一方面,我们的场景图前端(Hydra中级在图9中)具有固定的计算成本。在图9中,Hydra高级的运行时间略有上升趋势,由房间检测和场景图优化计算成本驱动,尽管仍然远低于批量处理。Hydra高级运行时间的显著峰值(例如,在1400秒)对应于在添加新的环路闭合时执行3D场景图优化。
表I报告了在单个试验中每个层的增量创建的计时分解。对象层的运行时间由活动窗口中的网格顶点数决定,因此SidPac场景的计算成本高于其他场景。房间层的运行时间由地点的数量决定(结合了场景的复杂性和大小);这就是为什么尽管办公室场景比SidPac场景小,但其房间的计算成本最高。虽然表I中的计时结果是基于相对强大的工作站获得的,但我们再次声明Hydra可以在通常用于机器人应用的嵌入式计算机上实时运行。为了实现这一目标,我们还在Nvidia Xavier NX上测量了uHumans2办公室场景的计时统计。Hydra处理对象的时间为75 ± 35毫秒,地点为33 ± 6毫秒,房间为55 ± 41毫秒。请注意,这些层的目标“实时”速率为关键帧速率(5 Hz)。虽然仍有优化计算的空间(见结论),但这些初步结果强调了Hydra在构建3D场景图方面的实用性和实时能力。环路闭合消融研究。最后,我们仔细研究了层次环路闭合检测方法提出的环路闭合候选者的质量,并与传统基于视觉的方法在办公室场景上进行了比较。具体来说,我们将我们的方法与使用DBoW2进行地点识别和ORB特征匹配的基于视觉的环路闭合检测进行了比较,如[50]中所述。图10显示了检测到的环路闭合数量与估计环路闭合姿态的误差(即,查询和匹配计算的相对姿态)对于三种不同的环路闭合配置:(i)“SG-LC”:提出的场景图环路闭合检测,(ii)“V-LC(名义)”:具有名义参数的传统基于视觉的环路闭合检测(与图7相同),以及(iii)“VLC(宽容)”:具有更宽容参数的基于视觉的环路闭合检测(即,降低了得分阈值和更少限制性的几何验证设置)。我们在附录中报告了这次评估中使用的参数。正如预期的那样,使基于视觉的检测参数更宽容会导致更多的但质量较低的环路闭合。另一方面,场景图环路闭合方法在10厘米误差和1度误差内的环路闭合数量大约是宽容的视觉方法的两倍。提出的方法在定量和定性上都比两个基线更好。
VII. 结论
本文介绍了Hydra,这是一个实时空间感知系统,可以从传感器数据中实时构建3D场景图。Hydra得益于新颖的在线算法和高度并行化的感知架构,能够以传感器速率运行。此外,它通过一种新颖的3D场景图优化方法,允许构建环境的持久表示。虽然我们认为提出的方法为机器人的高级3D场景理解迈出了重要一步,但Hydra可以在许多方向上进行改进。首先,一些在重建的3D场景图中的节点未标记(例如,本文中的算法能够检测房间,但无法将给定房间标记为“厨房”或“卧室”);未来的工作包括将Hydra与基于学习的方法[60]结合起来,用于3D场景图节点标记。其次,对3D场景图的节点和边进行更丰富的关系和可供性标记将是有意义的,基于[67]进行构建。第三,我们的场景图优化方法与姿态图优化之间的联系提供了通过利用最近的姿态图稀疏化进展来提高优化效率的机会。最后,使用3D场景图进行预测、规划和决策的含义大多未被探索(见[1, 46]为早期示例),这为未来的工作开辟了进一步的途径。
免责声明
研究由美国空军研究实验室和美国空军人工智能加速器赞助,并在合作协议号FA8750-19-2-1000下完成。本文件中的视图和结论是作者的观点,不应被解释为代表美国空军或美国政府的官方政策,无论是明示的还是暗示的。美国政府被授权为政府目的复制和分发重印本,尽管此处有任何版权声明。
致谢
这项工作部分由AIA CRA FA875019-2-1000、ARL DCIST CRA W911NF-17-2-0181和ONR RAIDER N00014-18-1-2828资助。