
Kimera
Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs
摘要:
人类能够形成他们所处环境的复杂心理模型。这种心理模型捕捉场景的几何和语义方面,描述环境在多个抽象层次(例如,对象、房间、建筑物),包括静态和动态实体及其关系(例如,在给定时间一个人在房间里)。相比之下,当前机器人的内部表征仍然只能提供对环境的部分和碎片化的理解,无论是以几何原语的稀疏或密集集合(例如,点、线、平面、体素)的形式,还是作为一系列对象的集合。
- 本文试图通过引入一种新的表示方法——3D动态场景图(DSG),来缩小机器人和人类感知之间的差距,DSG能够无缝捕捉动态环境的度量和语义方面。DSG是一个分层图,其中节点代表不同抽象层次的空间概念,边代表节点之间的时空关系。
- 我们的第二项贡献是Kimera,这是一个完全自动的方法,可以从视觉-惯性数据构建DSG。Kimera包括准确的算法,用于视觉-惯性SLAM、度量-语义3D重建、对象定位、人体姿态和形状估计以及场景解析。
- 我们的第三项贡献是对Kimera在真实生活数据集和照片级逼真模拟中的全面评估,包括我们新发布的uHumans2数据集,该数据集模拟了一系列拥挤的室内和室外场景。我们的评估表明,Kimera在视觉-惯性SLAM中取得了竞争性能,能够实时估计准确的3D度量-语义网格模型,并在几分钟内构建一个复杂室内环境的DSG,其中包含数十个对象和人类。
- 我们最后的贡獻是展示如何使用DSG进行实时分层语义路径规划。
Kimera 的核心模块已经开源发布。
1 引言
高级场景理解是机器人和自动驾驶车辆安全长期运行以及与人机有效交互的先决条件。下一代机器人必须能够理解和执行高级指令,例如“在二楼寻找幸存者”或“去厨房拿起购物袋”。它们必须能够在长距离和长时间范围内规划和行动以支持终身运行。此外,它们需要对场景的整体理解,以便推理不一致性、因果关系和被遮挡的对象。
像人类一样,我们不费吹灰之力地执行所有这些操作:我们理解高级指令,规划长距离(例如,计划从波士顿到罗马的旅行),并对环境进行高级推理。例如,像人类一样,我们可以很容易地推断,如果前面的车突然在人行横道附近停在路上,即使被前面的车遮挡,也很可能是有行人正在过马路。这与今天机器人的能力形成了鲜明对比:机器人通常被发出几何命令(例如,“到达坐标XYZ”),没有适当的表征(也没有推理算法)来支持在多个抽象层次上的决策制定,并且没有因果关系或高级推理的概念。
对3D动态场景的高级理解涉及三个关键要素:
- 理解场景的几何、语义和物理,
- 在多个抽象层次上表示场景,
- 捕捉实体(对象、结构、人类)之间的时空关系。我们在下面讨论每个方面的重要性,并强调当前方法的不足之处。
==第一个要素,度量-语义理解,是将语义概念(例如,幸存者、购物袋、厨房)归结为空间表示(即,度量地图)的能力。==几何信息对机器人安全导航和操纵对象至关重要,而语义信息为机器人理解和执行人类指令(例如,“给我拿一杯咖啡”)提供了理想的抽象层次,并为人类提供了易于理解的环境模型。尽管在几何重建(例如,SLAM(Cadena等人,2016年)、从运动中恢复结构(Enqvist等人,2011年)和多视图立体视觉(Schöps等人,2017年))和基于深度学习的语义分割(例如,(Garcia-Garcia等人,2017年;Krizhevsky等人,2012年;Redmon和Farhadi,2017年;Ren等人,2015年;He等人,2017年;Hu等人,2017年;Badrinarayanan等人,2017年))方面取得了前所未有的进展,这两个领域的研究传统上是分开进行的,并且在这些领域的交叉点上最近的研究越来越多(Bao和Savarese,2011年;Cadena等人,2016年;Bowman等人,2017年;Hackel等人,2017年;Grinvald等人,2019年;Zheng等人,2019年;Davison,2018年)。
第二个要素是提供对场景的可操作理解的能力,这种理解在多个抽象层次上。对抽象的需求主要是由计算和通信限制所驱动的。像人类一样,当我们计划长途旅行时,我们以城市或机场为单位进行推理,因为这比以笛卡尔坐标系推理更为(计算上)方便。同样,当被要求在建筑物中指路时,我们发现列出走廊、房间和楼层比绘制一条精确的度量路径更为方便。同样,机器人通过在多个抽象层次上进行规划来分解决策的复杂性,从高层次的任务规划到运动规划和轨迹优化,再到低层次的控制和障碍物避让,每个抽象层次都在模型保真度和计算效率之间进行权衡。支持分层决策制定和规划要求机器人感知能够构建一系列一致的抽象层次,以提供任务规划、运动规划和反应性控制所需的信息。早期关于机器人地图表示的工作,例如(Kuipers,2000年,1978年;Chatila和Laumond,1985年;Vasudevan等人,2006年;Galindo等人,2005年;Zender等人,2008年),主要研究了2D中的分层表示,并假设环境是静态的;此外,这些工作是在“深度学习革命”之前提出的,因此它们无法负担高级的语义理解。另一方面,关于度量-语义映射的日益增长的文献(Salas-Moreno等人,2013年;Bowman等人,2017年;Behley等人,2019年;Tateno等人,2015年;Rosinol等人,2020a年;Grinvald等人,2019年;McCormac等人,2017年)侧重于“平面”表示(对象组合、度量-语义网格或体积模型),这些表示本身并不是分层的。
==高级理解的第三个要素是描述场景中的静态和动态实体并推理它们之间的关系的能力。==在对象及其(几何和物理)关系层面上的推理对于解析高级指令(例如,“从桌子上拿起玻璃杯”)至关重要。这对于保证安全运行也很重要:在许多应用中,从自动驾驶汽车到工厂地板上的协作机器人,仅仅识别障碍物并不足以保证安全有效的导航/行动,而且变得至关重要的是捕捉场景中的动态实体(特别是人类),并预测他们的行为或意图(Everett等人,2018年)。最近的工作(Armeni等人,2019年;Kim等人,2019年)**试图通过丰富的表示,即3D场景图,来捕捉对象之间的关系。**场景图是计算机图形和游戏应用中常用的数据结构,由图组成,其中节点代表场景中的实体,边代表节点之间的空间或逻辑关系。虽然(Armeni等人,2019年;Kim等人,2019年)在机器人视觉领域开创性地使用了3D场景图(先前的工作集中在2D场景图上,这些场景图在图像空间中定义(Choi等人,2013年;Zhao和Zhu,2013年a;Huang等人,2018年b;Jiang等人,2018年)),但它们有明显的缺点。Kim等人(2019年)只捕捉对象,错过了多个抽象层次。Armeni等人(2019年)提供了一个对可视化和知识组织有用的层次模型,但没有捕捉到关键的可操作信息,例如可通行性,这对于机器人导航至关重要。最后,Kim等人(2019年)和Armeni等人(2019年)都没有考虑到或建模环境中的动态实体,这对于在人类居住环境中移动的机器人至关重要。
贡献
虽然设计和实现一个有效地包含所有这些要素的机器人感知系统只能是一个长期研究议程的目标,但本文通过提出一种新的环境表示和实用的算法来推断数据,提供了第一步。特别是,本文提供了四项贡献。
第一项贡献(第2节)是可操作空间感知的统一表示:3D动态场景图(DSG)。DSG是一个分层有向图,其中节点代表(例如,对象、房间、代理)的空间概念,边代表节点之间的成对时空关系。
- 与知识库(Krishna,1992年)不同,空间概念是空间基础的语义概念(换句话说,我们DSG中的每个节点都包括空间坐标和形状或边界框信息作为属性)。
- DSG是一个分层图,即节点被分组成对应于场景的不同抽象层次的层(即,DSG是一个层次表示)。我们在DSG中选择的节点和边也捕捉到了地点及其连通性,因此为导航和规划提供了严格概括了拓扑地图的概念(Ranganathan和Dellaert,2004年;Remolina和Kuipers,2004年),使DSG成为可操作的表示。
- 最后,DSG中的边捕捉时空关系,并显式建模场景中的动态实体,特别是人类,我们估计他们的3D姿态随时间变化(使用姿态图模型)和密集网格模型。
第二项贡献(第3节)是Kimera,这是第一个从机器人收集的视觉-惯性数据构建DSG的空间感知引擎。Kimera有两组模块:Kimera-Core和Kimera-DSG。Kimera-Core(Rosinol等人,2020a年)负责场景的实时度量-语义重建,包括以下模块:
- Kimera-VIO(第3.1节)是一个视觉-惯性里程计(VIO)模块,用于快速和局部准确的3D姿态估计(定位)。
- Kimera-Mesher(第3.2节)重建用于避障的快速局部3D网格。
- Kimera-Semantics(第3.3节)使用体积方法(Oleynikova等人,2017年)构建全局3D网格,并使用2D像素级语义分割和3D贝叶斯更新对3D网格进行语义注释。Kimera-Semantics使用Kimera-VIO的姿态估计。
- Kimera-PGMO(姿态图和网格优化,第3.4节)通过同时优化描述机器人轨迹的姿态图和Kimera-Semantics的全局度量-语义网格,执行视觉回路闭合。这个新模块概括了Kimera-RPGO(鲁棒姿态图优化,Rosinol等人,2020a年),后者只优化描述机器人轨迹的姿态图。像Kimera-RPGO一样,Kimera-PGMO包括一个拒绝异常回路闭合的机制。
Kimera-DSG负责构建场景的DSG,并在Kimera-Core之上工作。Kimera-DSG包括以下模块:
- Kimera-Humans(第3.5节)在场景中重建人类的密集网格,并使用姿态图模型估计他们的轨迹。密集网格使用Loper等人(2015年)的Skinned Multi-Person Linear Model(SMPL)进行参数化。
- Kimera-Objects(第3.6节)为未知形状的物体估计边界框,并使用TEASER++(Yang等人,2020年)将CAD模型拟合到度量-语义网格中已知形状的物体上。
- Kimera-BuildingParser(第3.7节)将度量-语义网格解析为地点(即无障碍位置)的拓扑图,分割房间,并识别包围房间的结构(即,墙壁、天花板)。
空间感知引擎的概念扩展了SLAM,使其成为一个模块,并增强了它以捕获空间概念的层次结构及其关系。除了Kimera中许多模块的新颖性(例如,Kimera-PGMO、Kimera-Humans、Kimera-BuildingParser),我们的空间感知引擎(i)是第一个从传感器数据构建场景图的引擎(与Armeni等人,2019年相比,后者假设给定了注释的网格模型),(ii)提供了一个轻量级和可扩展的基于CPU的解决方案,以及(iii)对动态环境和错误的地方识别具有鲁棒性。Kimera的核心模块已在https://github.com/MIT-SPARK/Kimera上发布。
我们的第三项贡献(第4节)是广泛的实验评估和新照片级逼真数据集的发布。我们在真实和模拟数据集上测试Kimera,包括EuRoC数据集(Burri等人,2016年),以及我们与(Rosinol等人,2020b年)一起发布的uHumans数据集。除了这些数据集,我们发布了uHumans2数据集,它包括拥挤的室内和室外场景,包括公寓、办公楼、地铁站和住宅区。最后,我们在公寓和办公室空间收集的真实数据集上定性评估Kimera。评估表明,Kimera的模块(i)在视觉-惯性SLAM中取得了竞争性能,(ii)能够实时在嵌入式CPU上重建度量-语义网格,(iii)能够正确地变形密集网格以执行回路闭合,(iv)能够准确定位和跟踪对象和人类,以及(v)能够正确地将室内建筑划分为房间、地点和结构。
我们的最后贡献(第5节)是展示可以在DSG上实现的潜在查询,包括层次语义路径规划的示例。特别是,我们展示了机器人如何使用DSG理解和执行高级指令,例如“到达靠近沙发的人”(即,语义路径规划)。我们还演示了DSG允许在利用DSG的层次性质的情况下,以比使用体积方法的规划器少得多的时间计算路径规划查询。
我们通过广泛的文献综述(第7节)和未来工作讨论(第8节)来结束本文。与之前工作(Rosinol等人,2020a,b年)
相比的新颖性。本文将我们之前关于Kimera(Rosinol等人,2020a年)的工作(其模块现在已扩展并包含在Kimera-Core中)和3D动态场景图(Rosinol等人,2020b年)的工作推向成熟,并提供几项新贡献。
- 首先,我们引入了一个新的回路闭合机制,该机制可以变形度量-语义网格(Kimera-PGMO),而(Rosinol等人,2020a年)中的网格没有纳入回路闭合校正的结果。
- 其次,我们在DSG上实现并测试了一个语义层次路径规划算法,这在(Rosinol等人,2020b年)中仅进行了讨论。
- 第三,我们提供了更全面的评估,包括我们自己的真实数据集和新的模拟数据集(uHumans2)。此外,我们在NVIDIA TX2计算机上测试Kimera,并展示它在嵌入式硬件上实时执行。
2 3D动态场景图
3D动态场景图(DSG,图1)是一个可操作的空间表示,它在不同的抽象层次上捕捉场景的3D几何和语义,并模拟对象、地点、结构、代理及其关系。更正式地说,DSG是一个分层有向图,其中节点代表空间概念(例如,对象、房间、代理)和边代表成对的时空关系(例如,“代理A在时间t在房间B”)。
与知识库(Krishna,1992年)不同,空间概念是空间基础的语义概念(换句话说,我们DSG中的每个节点都包括空间坐标和形状或边界框信息作为属性)。DSG是一个分层图,即节点被分组成对应于场景的不同抽象层次的层。每个节点都有一个唯一的ID。
单层室内环境的DSG包括5个层次(从低到高抽象层次):(i)度量-语义网格,(ii)对象和代理,(iii)地点和结构,(iv)房间,以及(v)建筑物。我们在下面讨论每个层次及其相应的节点和边。
2.1 第1层:度量-语义网格
DSG的底层是一个语义注释的3D网格(semantically annotated 3D mesh)(图1底部)。这一层的节点是3D点(网格的顶点),每个节点具有以下属性:(i)3D位置,(ii)法线,(iii)RGB颜色,以及(iv)全景分割语义标签。边连接三个点(即,一个具有3个节点的团)描述网格中的面,并定义环境的拓扑结构。我们的度量-语义网格包括环境中的所有静态元素,而动态对象的网格则存储在一个单独的结构中(见“代理”部分)。
Panoptic segmentation 全景分割(Kirillov等人,2019年;Li等人,2018年a)分割对象(例如,椅子、桌子、抽屉)和结构(例如,墙壁、地面、天花板)。
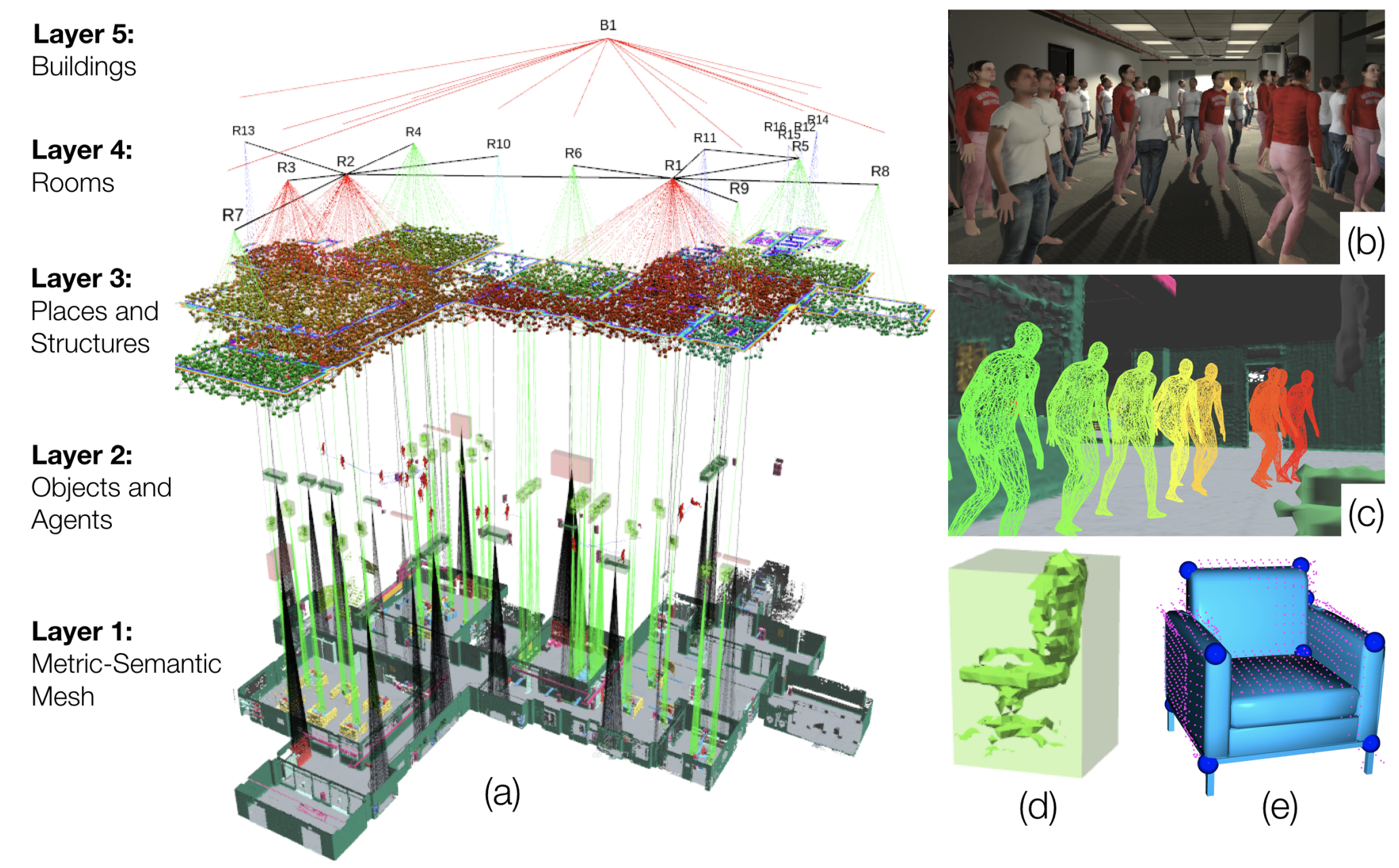
图1.(a)3D动态场景图(DSG)是一个分层和层次化的表示,它将密集的3D模型(例如,度量-语义网格)抽象为更高级别的空间概念(例如,对象、代理、地点、房间),并模拟它们之间的时空关系(例如,“代理A在时间t在房间B”)。Kimera是第一个从视觉-惯性数据重建DSG的空间感知引擎,并且(a)分割地点、结构(例如,墙壁)和房间,(b)对极其拥挤的环境鲁棒,(c)实时跟踪人类代理的密集网格模型,(d)估计未知形状物体的质心和边界框,(e)估计给定CAD模型的对象的3D姿态。
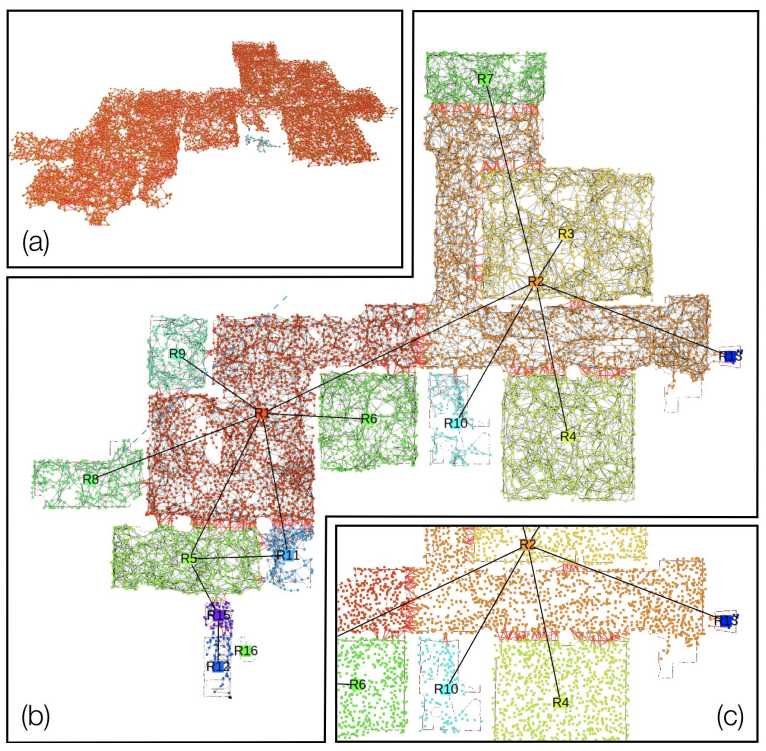
图2. 地点及其连通性显示为图。(a)由(Oleynikova等人,2018年)生成的骨架(地点和拓扑)(侧视图);(b)我们的方法生成的房间解析(俯视图);(c)放大视图;红色边连接不同的房间。
2.2 第2层:对象和代理
这一层包含两种类型的节点:对象和代理。它们的主要区别在于代理是时变实体,而对象是静态的。
对象代表环境中不被认为是结构的静态元素(即,墙壁、地板、天花板、柱子被认为是结构,并不在这一层建模)。每个对象是一个节点,节点属性包括(i)3D对象姿态,(ii)边界框,以及(iii)其语义类别(例如,椅子、桌子)。虽然本文没有调查,但我们建议读者参考(Armeni等人,2019年)以获得更全面的属性列表,包括材料和可供性。对象之间的边描述关系,例如共视性、相对大小、距离或接触(“杯子在桌子上”)。每个对象节点都连接到度量-语义网格中属于该对象的相应点集。此外,每个对象都连接到最近的可达地点节点(见第2.3节)。
代理代表环境中的动态实体,包括人类。通常,可能有许多类型的动态实体(例如,户外环境中的动物、车辆或自行车)。在本文中,我们专注于两类:人类和机器人。我们的方法依靠定义哪些标签被认为是2D图像语义分割中的动态标签来跟踪动态代理。
人类和机器人节点都有三个属性:(i)描述他们随时间的轨迹的3D姿态图,(ii)描述他们(非刚性)形状的网格模型,以及(iii)语义类别(即,人类、机器人)。姿态图(Cadena等人,2016年)是一系列时间戳的3D姿态,其中边模拟成对相对测量。收集数据的机器人也在这一层被建模为代理。
2.3 第3层:地点和结构
这一层包含两种类型的节点:地点和结构。直观地说,地点是自由空间的模型,而结构捕捉不同空间之间的分隔符。
地点(图2)对应于自由空间中的位置,地点之间的边代表可通行性(特别是:地点之间是否存在直线路径)。地点及其连通性形成一个拓扑图(Ranganathan和Dellaert,2004年;Remolina和Kuipers,2004年),可用于路径规划。地点属性只包括3D位置,但也可以包括语义类别(例如,房间的背面或前面)和围绕地点位置的无障碍边界框。第2层中的每个对象和代理都与最近的地点连接(对于代理来说,连接是针对每个时间戳的姿态,因为代理从一个地方移动到另一个地方)。属于同一房间的地点也连接到第4层的同一房间节点。图2(b-c)显示了按房间颜色编码的地点的可视化。
结构(图3)包括描述环境中结构元素的节点,例如墙壁、地板、天花板、柱子。结构的概念捕捉了通常在相关工作中被称为“东西”的元素(Li等人,2018年a)。结构节点的属性是:(i)3D姿态,(ii)边界框,以及(iii)语义类别(例如,墙壁、地板)。结构可能与它们包围的房间有边。结构也可能与第3层的对象有边,例如,“框架”(对象)“挂在”(关系)“墙壁”(结构)上,或者“天花板灯安装在天花板上”。
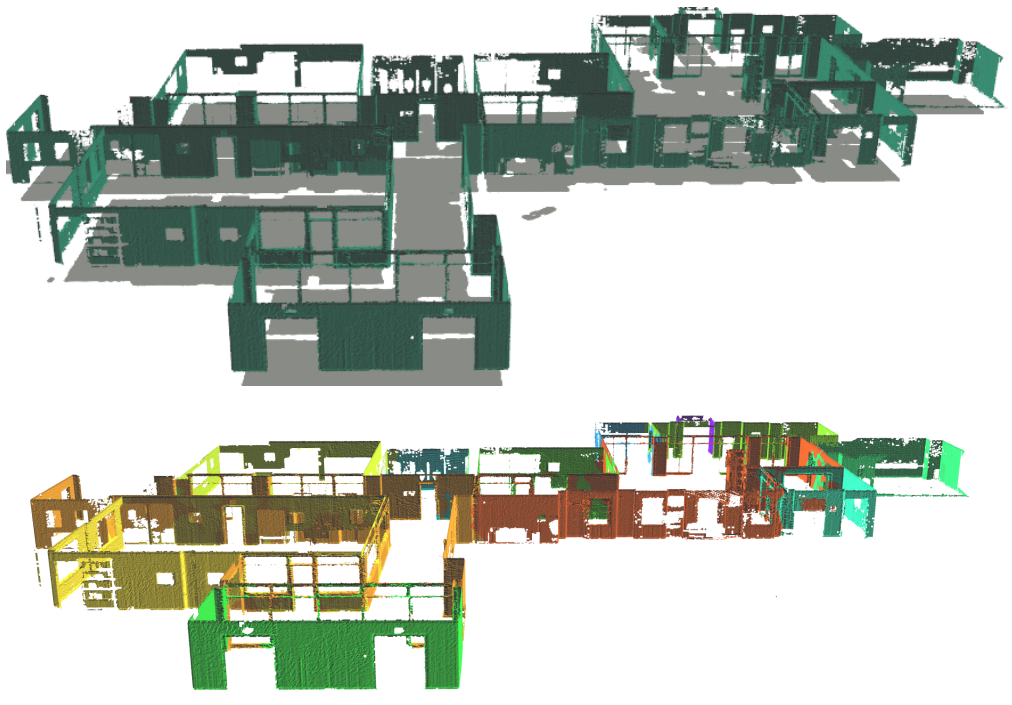
图3. 结构:墙壁和地板的爆炸视图(顶部)。按房间ID分割的墙壁(底部)。
2.4 第4层:房间
这一层包括描述房间、走廊和大厅的节点。房间节点(图2)具有以下属性:(i)3D姿态,(ii)边界框,以及(iii)语义类别(例如,厨房、餐厅、走廊)。如果两个房间相邻(即,它们之间有一扇门连接),则两个房间通过边连接。房间节点有边连接到它包含的地点(第3层)(因为每个地点都连接到附近的对象,DSG也捕捉了每个房间中包含的对象/代理)。所有房间都连接到它们所属的建筑物(第5层)。
2.5 第5层:建筑物
由于我们考虑的是单个建筑物的表示,因此只有一个建筑物节点,具有以下属性:(i)3D姿态,(ii)边界框,以及(iii)语义类别(例如,办公楼、住宅)。建筑物节点有边指向建筑物中的所有房间。
2.6 组合和查询
为什么我们选择这组节点或边,而不是另一组?显然,DSG中节点的选择不是唯一的,并且取决于任务。这里我们首先根据DSG设计的任务和运动规划查询来激励我们选择的节点(见注释1和第5节的更广泛讨论),然后我们展示表示是组合的,这意味着它可以轻松地在DSG的顶部和底部添加更多层,甚至添加中间层(注释2)。
注释1. 规划查询。提出的DSG是针对任务和运动规划查询而设计的。语义节点属性(例如,语义类别)支持从高级规范(例如,“从餐厅的桌子上拿起红色杯子”)进行规划。几何节点属性(例如,网格、位置、边界框)和边用于运动规划。例如,地点可以用作路径规划的拓扑图,边界框可以用作快速碰撞检查。
注释2. DSG的组合。DSG的第二个确保属性是其组合性:可以轻松地在图1(a)的DSG的顶部和底部添加更多层,甚至添加中间层。例如,在多层建筑中,我们可以在“建筑物”和“房间”层之间包含一个“楼层”层。此外,我们可以在顶部添加进一步的抽象或层,例如从建筑物到社区,然后到城市。
3 Kimera:空间感知引擎
本节描述了Kimera,我们的空间感知引擎,它使用传感器数据填充DSG节点和边。Kimera的输入是立体或RGB-D相机的流数据,以及惯性测量单元(IMU)。输出是3D DSG。在我们当前的实现中,度量-语义网格和代理节点是从传感器数据中实时增量构建的,而其余节点(对象、地点、结构、房间)在运行结束时自动构建。
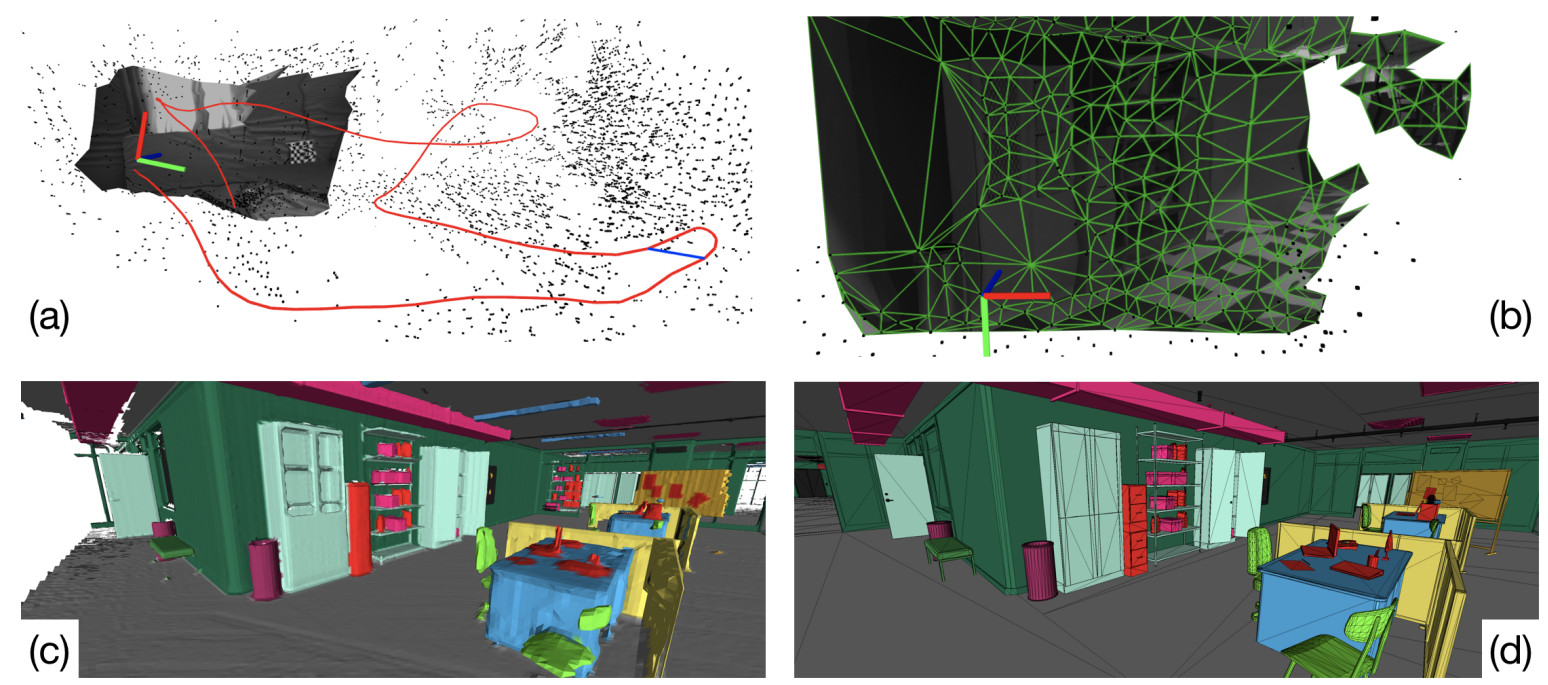
图4. 图 4. Kimera-Core 是一个开源库,用于实时度量-语义 SLAM。它提供(a)以 IMU 速率的状态估计,以及一个全局一致且对异常值鲁棒的轨迹估计(Kimera-RPGO),计算(b)低延迟的局部网格以及(c)基于语义的全局网格,这些网格可以被优化以反映真实的地面模型(d)。
Kimera-Core . 我们使用Kimera-Core(Rosinol等人,2020a年)从视觉-惯性数据中实时重建语义注释的3D网格(图4)。Kimera-Core是开源的,包括四个主要模块:
(i)Kimera-VIO:视觉-惯性里程计模块,实现IMU预积分和固定滞后平滑(Forster等人,2017年),
(ii)Kimera-PGMO:鲁棒姿态图和网格优化器,概括了Kimera-RPGO,后者只优化姿态图。
(iii)Kimera-Mesher:每帧和多帧网格生成器(Rosinol等人,2019年)
(iv)Kimera-Semantics:体积方法,用于产生语义注释网格和基于Voxblox的欧几里得符号距离函数(ESDF)(Oleynikova等人,2017年)。Kimera-Semantics使用2D语义分割的相机图像对3D网格进行标记,使用贝叶斯更新。
我们采用Kimera-Semantics产生的度量-语义网格,并由Kimera-PGMO优化,作为图1(a)中的DSG的第一层。
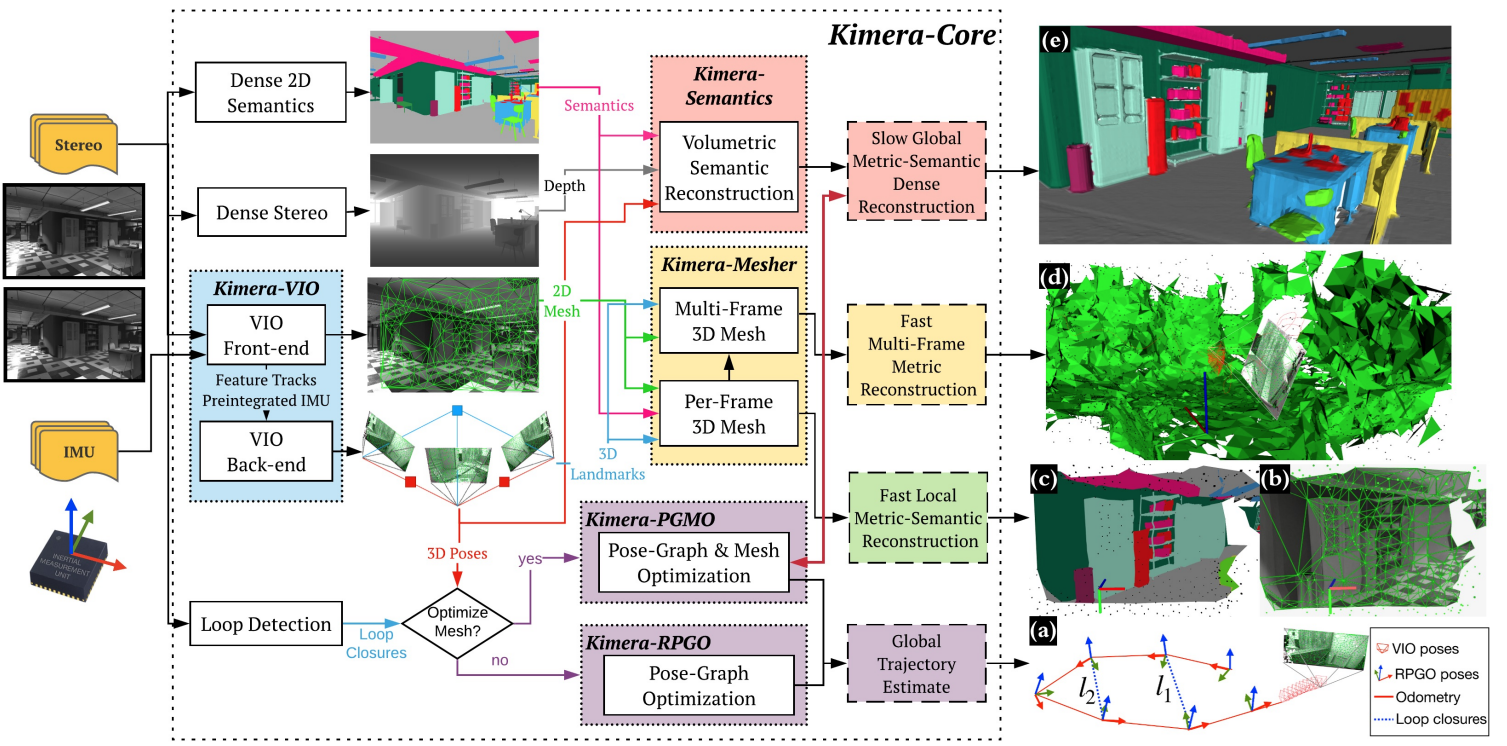
图 5. Kimera-Core 的架构。Kimera-Core 使用立体图像(或 RGB-D)和 IMU 数据作为输入(显示在左侧),并输出(a)姿态估计和(b-e)多种度量-语义重建。Kimera-Core 有四个关键模块:Kimera-VIO、Kimera-PGMO(或者 Kimera-RPGO)、Kimera-Mesher 和 Kimera-Semantics。
图5显示了Kimera-Core的架构。Kimera采用立体帧和高频率惯性测量作为输入,返回
(i)在IMU速率下的高精度状态估计,
(ii)全局一致的轨迹估计,
(iii)多个环境网格,包括快速局部网格和全局语义注释网格。Kimera-Core大量并行化,并使用五个线程来适应不同速率的输入和输出(例如,IMU、帧、关键帧)。
这里我们按线程描述架构,而每个模块的描述在以下各节中给出。
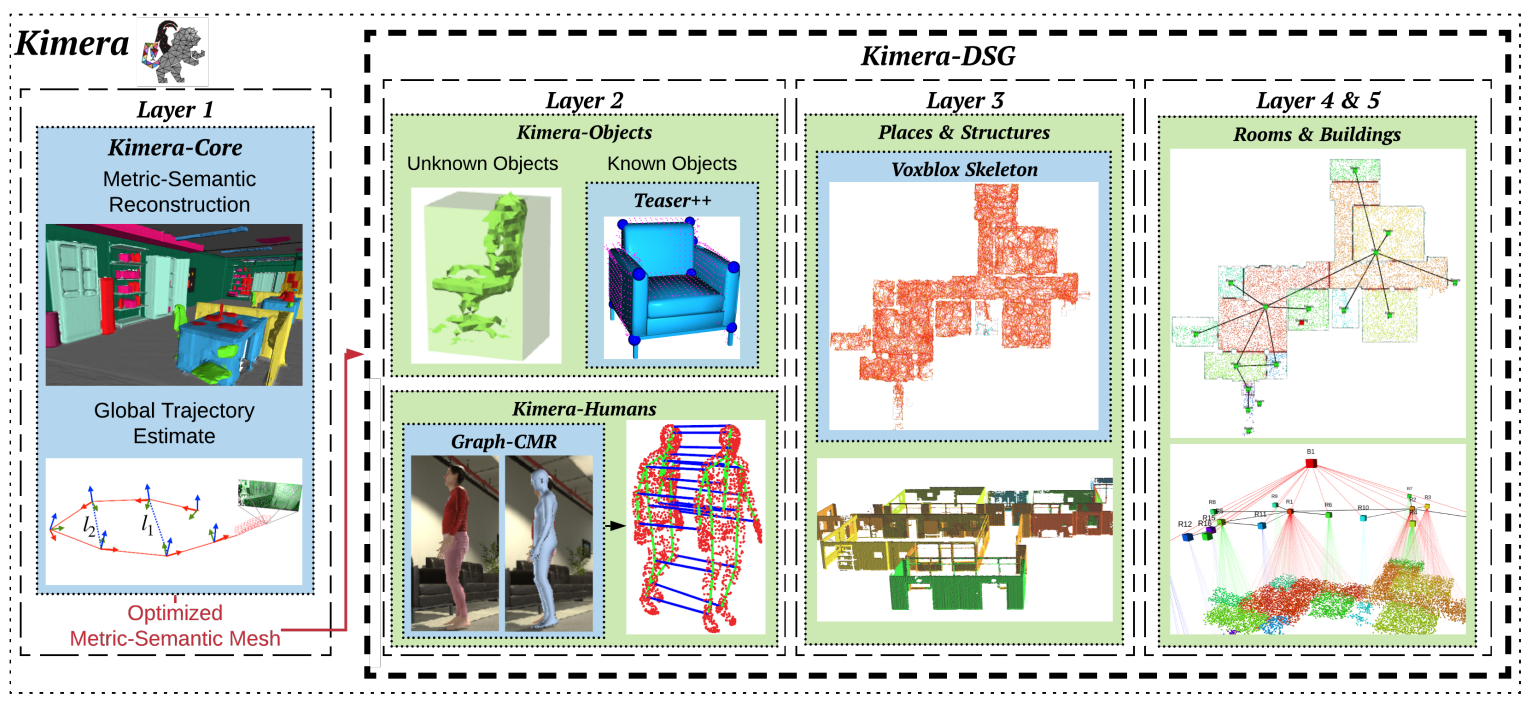
图 6. Kimera 的架构,包括 Kimera-Core 和 Kimera-DSG 作为子模块。Kimera-Core 生成一个全局一致的 3D 度量-语义网格(图 5),它代表 DSG 的第一层,并进一步被 Kimera-DSG 用来构建后续层。Kimera-DSG 进一步包括三个关键模块:Kimera-Objects、Kimera-Humans 和 Kimera-BuildingParser(生成第 3 到 5 层)。
- 第一个线程包括Kimera-VIO前端(第3.1节),它接收立体图像和IMU数据,并输出特征轨迹和预积分的IMU测量值。前端还发布IMU速率的状态估计。
- 第二个线程运行Kimera-VIO的后端,并输出优化后的状态估计(最重要的是,机器人的3D姿态)。
- 第三个线程运行Kimera-Mesher(第3.2节),计算低延迟(<20ms)的每帧和多帧3D网格。这三个线程允许创建图5(b)中的每帧网格(也可以像图5(c)中那样带有语义标签),以及图5(d)中的多帧网格。
接下来的两个线程以较慢的速率运行,旨在支持低频功能,如路径规划。
- 第四个线程包括Kimera-Semantics(第3.3节),它使用RGB-D或密集立体视觉的深度图和2D语义标签来获取度量-语义网格,使用Kimera-VIO的姿态估计。
- 最后一个线程包括Kimera-PGMO(第3.4节),它使用检测到的循环闭合,连同Kimera-VIO的姿态估计和Kimera-Semantics的3D度量-语义网格,来估计全局一致的轨迹(图5(a))和3D度量-语义网格(图5(e))。如图5所示,如果不需要优化的3D度量-语义网格,可以使用Kimera-RPGO代替Kimera-PGMO。
Kimera-DSG。这里我们逐层描述Kimera-DSG的架构,而每个模块的具体描述将在后面的各节中给出。
- 我们使用Kimera-DSG从Kimera-Core生成的全局一致的3D度量-语义网格构建DSG,该网格代表DSG的第一层,如图6所示。
- 然后,Kimera-DSG构建包含对象和代理的第二层。对于对象,Kimera-Objects(第3.6节)要么为未知形状的对象估计一个边界框,要么使用TEASER++(Yang等人,2020年)为已知形状的对象拟合一个CAD模型。
- Kimera-Humans(第3.5节)使用GraphCMR(Kolotouros等人,2019b)重建场景中人类的密集网格,并使用姿态图模型估计他们的轨迹。
- 接着,Kimera-BuildingParser(第3.7节)生成剩余的三层。它首先通过解析度量-语义网格来识别结构(即,墙壁、天花板)生成第3层,并使用(Oleynikova等人,2018年)进一步提取地点的拓扑图。
- 然后,Kimera-BuildingParser通过将第3层分割为房间生成第4层,并通过进一步将第4层分割为建筑物生成第5层。
第3.1节 Kimera-VIO:视觉-惯性里程计
Kimera-VIO实现了Forster等人(2017年)提出的关键帧基础最大后验视觉-惯性估计器。在我们的实现中,估计器可以执行全平滑或固定滞后平滑,具体取决于指定的时间范围;我们通常使用后者以限制估计时间。Kimera-VIO包括(视觉和惯性)前端,负责处理原始传感器数据,以及后端,融合处理后的测量数据以获得传感器状态(即,姿态、速度和传感器偏差)的估计。
VIO前端。我们的IMU前端执行流形预积分(Forster等人,2017年)以从原始IMU数据中获得两个连续关键帧之间相对状态的紧凑预积分测量。视觉前端检测Shi-Tomasi角点(Shi和Tomasi,1994年),使用Lukas-Kanade跟踪器(Bouguet,2000年)在帧间跟踪它们,执行左右立体匹配,并执行几何验证。我们执行单目(5点)RANSAC(Nistér,2004年)和立体(3点)RANSAC(Horn,1987年)验证;代码还提供使用IMU旋转执行单目和立体验证的选项,分别使用2点和1点RANSAC。由于我们的机器人在拥挤(动态)环境中移动,我们用IMU估计的旋转光流向Lukas-Kanade跟踪器提供初始猜测(被跟踪角点的位置),类似于(Hwangbo等人,2009年)。此外,我们默认使用2点(立体)和1点(单目)RANSAC,它使用IMU旋转来修剪特征轨迹中的异常对应关系。特征检测、立体匹配和几何验证在每个关键帧上执行,而我们在中间帧上跟踪特征。
VIO后端。在每个关键帧上,将预积分的IMU和视觉测量值添加到固定滞后平滑器 fixed-lag smoother(因子图)中,它构成了我们的VIO后端。我们使用预积分IMU模型和无结构视觉模型(Forster等人,2017年)。使用iSAM2(Kaess等人,2012年)在GTSAM(Dellaert,2012年)中解决因子图。在每次iSAM2迭代中,无结构视觉模型使用DLT(Hartley和Zisserman,2004年)估计观察到的特征的3D位置,并从VIO状态中解析消除相应的3D点(Carlone等人,2014年)。在消除之前,去除退化点(即,相机后面的点或没有足够的视差进行三角测量的点)和异常值(即,具有大重投影误差的点),提供了额外的鲁棒性层。最后,超出平滑范围的状态使用GTSAM边缘化。
第3.2节 Kimera-Mesher:3D网格重建
Kimera-Mesher可以快速生成两种类型的3D网格:(i)每帧3D网格,以及(ii)跨越VIO固定滞后平滑器中的关键帧的多帧3D网格。
每帧网格 pre-frame mesh。如(Rosinol等人,2019年)所述,我们首先在当前关键帧中成功跟踪的2D特征(由VIO前端生成)上执行2D Delaunay三角剖分。然后,我们使用VIO后端的3D点估计进行反投影,生成3D网格(图5(b))。虽然每帧网格旨在提供低延迟障碍物检测,我们还提供将结果网格进行语义标记的选项,通过将2D标签纹理到网格上(图5(c))。
多帧网格。多帧网格将VIO滞后范围内收集的每帧网格融合到单个网格中(图5(d))。每帧和多帧3D网格都编码为顶点位置列表,以及描述三角形面的顶点ID三元组列表。假设我们在时间t-1有一个多帧网格,对于我们生成的每个新的每帧3D网格(在时间t),我们循环遍历其顶点和三元组,并添加在每帧网格中但不在多帧网格中的顶点和三元组。然后我们循环遍历多帧网格顶点,并根据最新的VIO后端估计更新它们的3D位置。最后,我们移除对应于VIO时间范围之外观察到的旧特征的顶点和三元组。结果是跨越当前VIO时间范围内关键帧的最新3D网格。如果网格中检测到平面表面,将向VIO后端添加规则性因子(Rosinol等人,2019年),这导致VIO和网格正则化之间的紧密耦合,详见(Rosinol等人,2019年)了解更多细节。
第3.3节 Kimera-Semantics:3D度量-语义重建
我们采用了Oleynikova等人(2017年)引入的捆绑射线投射 bundled raycasting 技术,以(i)构建覆盖整个轨迹的准确全局3D网格,以及(ii)对网格进行语义注释。
全局网格。我们的实现基于Voxblox(Oleynikova等人,2017年),并使用基于体素的(TSDF)模型来过滤噪声并提取全局网格。在每个关键帧中,我们使用密集立体视觉(半全局匹配(H. Hirschmüller,2008年))获得深度图,或者如果可用,则从RGB-D获得。然后,我们使用Voxblox(Oleynikova等人,2017年)运行捆绑射线投射。这个过程在每个关键帧重复,并产生一个TSDF,从中使用游行立方体(Lorensen和Cline,1987年)提取网格。
语义注释。Kimera-Semantics使用在每个关键帧产生的2D语义标记图像(可以使用像素级2D语义分割工具获得,例如深度神经网络(Lang等人,2019年;Zhang等人,2019年a;Chen等人,2017年;Zhao等人,2017年;Yang等人,2018年;Paszke等人,2016年;Ren等人,2015年;He等人,2017年;Hu等人,2017年))。在我们的真实实验中,我们使用Mask-RCNN(He等人,2017年)。然后,在捆绑射线投射期间,我们也传播语义标签。使用2D语义分割,我们将标签附加到由密集立体视觉产生的每个3D点。然后,对于捆绑射线投射中的每个射线束,我们从观察到的标签的频率中构建一个标签概率向量。然后,我们仅在TSDF截断距离内沿射线传播此信息,以节省计算量。换句话说,我们节省了更新“空”标签的概率的计算工作。在射线上遍历体素时,我们使用贝叶斯更新来估计每个体素的后验标签概率,类似于(McCormac等人,2017年)。在捆绑语义射线投射之后,每个体素都有一个标签概率向量,从中我们提取最可能的标签。度量-语义网格最终也使用游行立方体(Lorensen和Cline,1987年)提取。结果网格比第3.2节中的多帧网格更准确,但计算速度较慢(≈0.1秒,见第4.8节)。
第3.4节 Kimera-PGMO:带有回路闭合的姿态图和网格优化
Kimera-Semantics生成的网格是基于Kimera-VIO的姿态图构建的,并且随着时间的推移而漂移。回路闭合模块检测回路闭合以纠正全局轨迹和网格。网格通过变形进行校正,这比从头开始重建网格或使用“去集成”(de-integration,Dai等人,2017年)更具可扩展性。这是通过一种新颖的同时姿态图和网格变形方法实现的,该方法利用嵌入式变形图在单次运行中优化环境和机器人轨迹。优化被表述为GTSAM中的因子图。以下,我们回顾各个组件。
回路闭合检测。回路闭合检测依赖于DBoW2库(Gálvez-López和Tardós,2012年),并使用ORB描述符的词袋表示快速检测候选回路闭合。对于每个候选回路闭合,我们使用单目5点RANSAC(Nistér,2004年)和立体3点RANSAC(Horn,1987年)几何验证来拒绝异常回路闭合,并将剩余的回路闭合传递给异常值拒绝和姿态求解器。请注意,由于感知别名(例如,建筑物不同楼层上的两个相同房间),结果回路闭合仍可能包含异常值。虽然大多数开源SLAM算法(例如ORB-SLAM3(Campos等人,2021年)、VINS-Mono(Qin等人,2018年)、Basalt(Usenko等人,2019年))在接受回路闭合时过于谨慎,通过微调DBoW2,我们反而使后端对异常值具有鲁棒性,如下所述。
异常值拒绝。我们使用一种现代的异常值拒绝方法,成对一致测量集最大化(PCM)(Mangelson等人,2018年),我们将其定制为单机器人和在线设置。我们分别存储由Kimera-VIO产生的里程计边和回路闭合(由回路闭合检测产生);每次检测到回路闭合时,我们通过找到一致回路闭合的最大集合来选择内点,使用修改版的PCM。
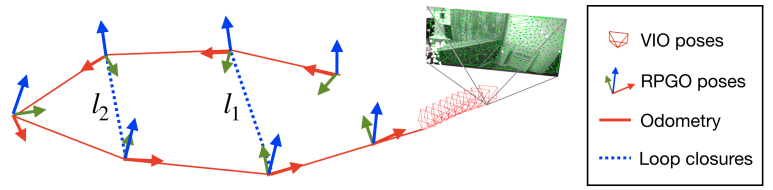
图7. Kimera-RPGO检测视觉回路闭合,拒绝错误回路闭合,并估计全局一致的轨迹。与Kimera-PGMO相比,Kimera-RPGO不优化3D网格。
原始PCM旨在多机器人情况,并只检查机器人间的回路闭合是否一致。我们开发了PCM的实现,它(i)增加了对回路闭合的里程计一致性检查,以及(ii)增量更新一致测量集以实现在线操作。里程计检查验证每个回路闭合(例如,图7中的l1)是否与里程计(红色)一致:在没有噪声的情况下,由里程计和回路l1形成的循环中的位姿必须组合为恒等式。与PCM一样,我们标记为异常值的回路,其在循环中累积的误差与测量噪声不一致,使用卡方检验。如果当前时间t检测到的回路通过里程计检查,我们测试它是否与之前的回路闭合成对一致(例如,检查图7中的回路l1和l2是否彼此一致)。当PCM(Mangelson等人,2018年)从头开始构建邻接矩阵A ∈ RL×L以跟踪成对一致的回路(其中L是检测到的回路闭合数量)时,我们通过增量构建矩阵A来实现在线操作。每次检测到新的回路时,我们向矩阵A添加一行和一列,并且只测试新回路与之前的回路。最后,我们使用(Pattabiraman等人,2015年)的快速最大团实现来计算最大的一致测量集。一致测量集被添加到姿态图中(连同里程计)。
姿态图和网格优化。当回路闭合通过异常值拒绝时,要么Kimera-RPGO优化机器人轨迹的姿态图(图7),要么Kimera-PGMO同时优化网格和轨迹(图8)。用户可以根据计算考虑和对一致地图的需求选择求解器;见注释3。请注意,Kimera-PGMO是Kimera-RPGO的严格概括,如(Rosinol等人,2020a年)所述。对于Kimera-PGMO,由回路闭合引起的网格变形基于变形图(Sumner等人,2007年)。在我们的方法中,我们创建了一个包括简化网格和机器人姿态图的姿态图的统一变形图。我们通过将网格的顶点存储在八叉树数据结构中来简化网格;随着网格的增长,八叉树中相同体素的顶点被合并,去除退化面和边。体素大小根据环境或数据集调整(我们的测试中为1到4米)。
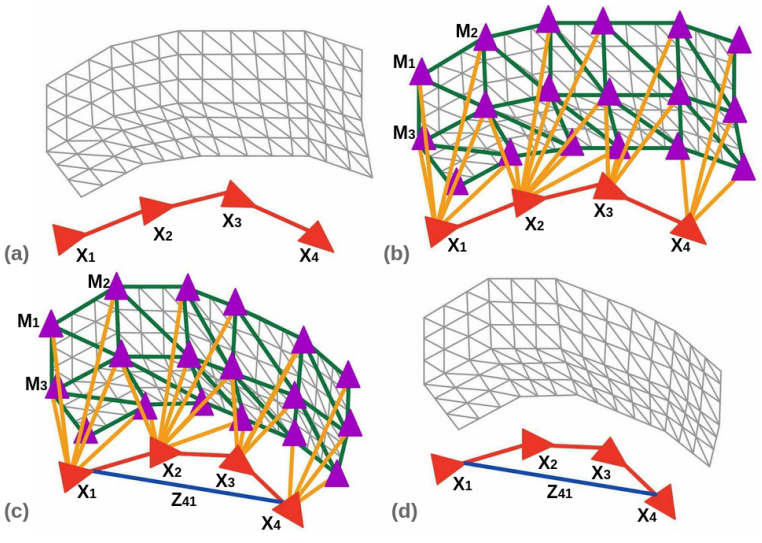
图 8. Kimera-PGMO 的网格变形和姿态图优化。(a) 显示了在检测到循环闭合之前收到的网格和姿态图。(b) 显示了创建变形图时,红色顶点是具有相关变换 X_i 的姿态顶点,紫色顶点是具有相关变换 的网格顶点。绿色边是描述简化网格连通性的边,也就是在变形图中连接网格顶点的边。黄色边是连接姿态顶点和网格顶点的边,基于相机的可见性。(c) 显示了当在姿态图节点 4 和节点 1()之间添加循环闭合时发生变形。基于优化结果更新了 和 。(d) 显示了优化后的网格和姿态图。
我们向变形图中添加了两种类型的顶点:网格顶点和姿态顶点。网格顶点对应于简化网格的顶点,并具有相关的变换,其中 ( k ) 是某个网格顶点。当网格尚未变形时,且,其中 是顶点 ( k ) 的原始世界坐标系位置。从直观上看,这些变换描述了网格上的局部变形: ( R_M^k ) 是围绕顶点 ( k ) 的局部旋转,而 是局部平移。网格顶点通过简化网格的边(图8中的绿色边)相互连接。
然后,我们将机器人的姿态图节点添加到变形图中作为姿态顶点,并具有相关的变换。当网格尚未变形时,只是节点 ( i ) 的里程计姿态。姿态顶点根据姿态图的原始连通性相互连接(图8中的红色边)。如果网格顶点 ( k ) 是由与姿态 ( i ) 相关联的相机可见的,则姿态顶点 ( i ) 与网格顶点 ( k ) 连接。
图8展示了变形图的组成部分和创建过程,包括姿态顶点和网格顶点以及边,以及在检测到循环闭合时发生的变形。基于循环闭合和里程计测量值(Z_{ij}),并且给定(n)个姿态顶点和(m)个网格顶点,变形图优化如下:
其中(NM(i))表示变形图中顶点(i)的邻近网格顶点,(g_i)表示变形图中网格或姿态顶点(i)的未变形(初始)世界坐标系位置, 表示顶点(l)在节点(i)的里程计姿态坐标系中的未变形位置(注意,除非节点(i)的未变形方向为恒等)。
第一项在优化中强制执行姿态图中的里程计和回路闭合测量,这些与标准姿态图优化相同;
第二项改编自(Sumner等人,2007年),并强制执行通过最小化连接网格顶点之间的相对平移来执行网格顶点之间的局部刚性(即,保持连接两个网格顶点的边);
第三项强制执行姿态顶点i和网格顶点l之间的局部刚性,同样通过最小化两个顶点之间的相对平移来执行。请注意,$ ||·||_Ω $ 表示加权的Frobenius范数,。
其中Ω的形式为Ω = ωRI3 0 0 ωt,分别对应于旋转和平移权重,如(Briales和Gonzalez-Jimenez,2017年)中所定义。在以下,我们展示方程(1)可以被表述为一个增强的姿态图优化问题。为此,我们定义了˜ Ri作为变形图中姿态顶点i的初始里程计旋转;然后我们定义,
Gij = I3 gj − gi 0 1 (3)
¯Gij = I3 ˜R−1 i (gj − gi) 0 1 (4)
并将优化重写为,
其中Z是变形图中所有里程计和回路闭合边的集合(图8中的红色和蓝色边),G是简化网格的边集合(图8中的绿色边),¯G是连接姿态顶点和网格顶点的所有边的集合(图8中的黄色边)。我们在
第二和第三项中仅优化平移,因此ΩGij和Ω ¯ Gij的旋转权重ωR被设置为零。进一步观察到这些项都是基于变形图中的边,我们定义Ti为姿态或网格顶点的变换,Eij是对应于变形图中边的变换,其形式为Zij、Gij、¯Gij,取决于边的类型。通过这种重新参数化,我们只剩下一个类似于文献中的姿态图优化问题。
arg min T1,...,Tn+m∈SE(3) ∑ Eij ||T−1 i Tj − Eij||2 Ωij (6)
请注意,变形图方法,如(Sumner等人,2007年)最初提出的,仅当使用旋转代替仿射变换时,等同于姿态图优化。然后,使用GTSAM优化姿态图。优化后,完整网格的顶点位置作为变形图中节点的仿射变换进行更新:
vi = ∑ m ∑ j=1 wj(vi)[RM j (vi − gj) + tM j ] (7)
其中vi表示原始顶点位置,vi表示新的变形位置。权重wj定义为
wj(vi) = (1 − ||vi − gj||/dmax)^2 (8)
然后归一化以总和为一。这里dmax是到k+1个最近节点的距离,如(Sumner等人,2007年)所述(我们设置k = 4)。
注释3. Kimera-RPGO和Kimera-PGMO。Kimera-RPGO是我们在(Rosinol等人,2020a年)中引入的鲁棒姿态图优化器,它使用修改版的成对一致测量集最大化(PCM)(Mangelson等人,2018年)方法来过滤由感知别名引起的错误回路闭合,然后优化机器人的姿态。Kimera-PGMO是Kimera-RPGO的严格概括。Kimera-RPGO和Kimera-PGMO都执行回路闭合检测和异常值拒绝,不同之处在于Kimera-PGMO还额外优化网格,以更大的计算成本解决更大的姿态图。正如我们将在实验部分看到的,Kimera-PGMO的时间几乎是Kimera-RPGO的三倍,因为它优化了一个更大的图。例如,Kimera-PGMO为EuRoC V1_01数据集优化了728个姿态节点和1031个网格节点,而Kimera-RPGO仅优化了728个姿态节点。
第3.5节 Kimera-Humans:人体姿态估计和鲁棒跟踪
机器人节点。在我们的设置中,唯一的机器人代理是收集数据的机器人。因此,Kimera-PGMO直接产生描述机器人在离散时间步的姿态的时间戳姿态图。为了完成机器人节点,我们假设给定了机器人的CAD模型(仅用于可视化)。人类节点。与相关工作不同,这些工作将动态目标建模为一个点或3D姿态(Chojnacki和Indelman,2018年;Azim和Aycard,2012年;Aldoma等人,2013年;Li等人,2018年b;Qiu等人,2019年),Kimera-Humans跟踪一个描述人类随时间变化的密集网格模型的形状。因此,为了创建人类节点,Kimera-Humans需要在相机图像中检测和估计人类的形状,然后随时间跟踪人类。除了用于跟踪外,我们还将人类检测反馈给Kimera-Semantics,以便不在3D网格中重建动态元素。我们通过仅在标记为人类的像素上使用自由空间信息进行深度投影来实现这一点,这种方法我们称之为动态掩蔽(见图16中的结果)。
图9. 人类节点:(a)来自Unity的输入相机图像,(b)使用(Kolotouros等人,2019b)的SMPL网格检测和姿态/形状估计,(c)在最大关节位移之间的时间跟踪和一致性检查。
对于人体姿态和形状估计,我们使用Kolotouros等人(2019b)(GraphCMR)的GraphCNN方法,该方法直接从单个图像中回归SMPL(Loper等人,2015年)网格模型的3D位置。图9(a-b)中显示了一个网格示例。给定像素级的2D分割图像,我们将左侧相机图像裁剪到每个检测到的人类周围的边界框,然后将其作为输入提供给GraphCMR。GraphCMR输出相应人类的3D SMPL网格,以及相机参数(x和y图像位置和对应弱透视相机模型的比例因子)。然后我们使用相机模型将人类网格顶点投影到图像帧中。获得投影后,我们计算整个网格相对于相机的位置和方向,使用PnP(Zheng等人,2013年)基于网格投影到相机框架中的重投影误差来优化相机姿态。从深度图像中恢复平移,用于获得人类骨盆关节在图像中的近似3D位置。最后,我们根据Kimera-VIO输出的世界变换将网格位置转换为全局框架。人体跟踪和监控。上述方法在很大程度上依赖于GraphCMR的准确性,并丢弃了有关人类的有用时间信息。实际上,GraphCMR的输出在几种情况下不可靠,特别是在人类部分遮挡时。在本节中,我们描述了我们的方法,用于(i)维护有关人类轨迹的持久信息,(ii)监控GraphCMR位置和姿态估计以确定哪些估计不准确,以及(iii)通过使用运动先验的位姿图优化来减轻人类位置误差。我们通过为每个遇到的人类维护一个姿态图并使用简单但鲁棒的数据关联更新姿态图来实现这些结果。姿态图。为了维护有关人类位置的持久信息,我们为每个人类构建一个姿态图,其中图的每个节点对应于人类骨盆在离散时间的位置。连续的姿态通过一个因子(Dellaert和Kaess,2017年)连接,该因子模拟人类运动的零速度先验,并具有允许小运动的宽容噪声模型。GraphCMR提供的位置信息被建模为先验因子,为每个时间步提供估计的全局坐标。除了骨盆位置外,我们还持久保存人类的SMPL参数和关节位置的历史记录,用于姿态分析。姿态图系统的优点是双重的。首先,使用每个人类的轨迹的姿态图允许应用姿态图优化技术,以获得平滑且对误检测鲁棒的轨迹估计。GraphCMR的许多检测结果即使没有立即被一致性检查拒绝,也会传播到姿态图中。然而,通过使用Kimera-RPGO和PCM异常值拒绝,人类的位姿图可以定期优化,以平滑轨迹并移除不良检测。PCM异常值拒绝特别适合于移除需要人类以任意速度移动/旋转的检测。其次,使用姿态图来模拟人类和机器人的全局轨迹允许两者之间的统一可视化工具。图10显示了办公室环境中一个人类的位姿图(蓝线),以及与图中的每个位姿相关的检测(彩虹色编码的人类网格)。数据关联。构建姿态图的关键问题之一是将哪些节点归属于同一个人类随时间关联,然后适当地链接它们。我们使用简化的数据关联模型,将新节点与最接近它的节点关联。在人类在两个时间步之间的移动距离小于人类之间的距离的温和假设下,这种形式的数据关联效果很好。我们没有关于人类何时进入画面以及何时离开的信息(尽管我们知道给定画面中的人数)。为了避免将新人类与之前人类的位姿图关联,我们在将位姿添加到位姿图之前,添加了一个时空一致性检查,如下所述。为了检查一致性,我们在时间t-1(来自位姿图)和t(来自当前检测)提取人类骨骼,并检查每个关节的运动是否在该时间间隔内是物理上合理的(即,我们利用关节和躯干运动不能任意快速的事实)。图9(c)中的检查进行了可视化。我们首先确保两个骨架集之间的质心运动速率是合理的。人类的平均步行速度约为1.25 m/s(Schimpl等人,2011年),我们使用保守的3m/s界限对数据关联的可行性进行阈值处理。此外,我们使用保守的3mon最大允许的关节位移来限制不规则的关节运动。通过使用SMPL模型的beta参数(Loper等人,2015年),可以使数据关联检查更加鲁棒,这些参数编码了网格的各种形状属性,用8个浮点参数表示。这些形状参数包括,例如,人类模型的不同特征的宽度和高度。我们检查当前检测的beta参数与时间t-1的骨架的beta参数,并确保每对beta参数之间的平均差异不超过某个阈值(我们实验中为0.1)。这有助于根据外观区分人类。在Kimera-Humans中,beta参数由GraphCMR(Kolotouros等人,2019b)估计。如果质心运动和关节运动在时间步之间在界限内,并且beta参数检查通过,我们将新节点添加到具有最近最终节点的位姿图中,如前所述。如果没有位姿图满足一致性标准,我们初始化一个新的位姿图,其中包含对应于当前检测的单个节点。节点误差监控和缓解。如前所述,GraphCMR的输出对遮挡的
人类非常敏感,并且在这些情况下预测质量较差。为了获得对简单遮挡的鲁棒性,我们将人类边界框接近图像边界或太小(在我们的测试中≤30像素)的检测标记为不正确。此外,我们使用位姿图的大小作为节点误差的代理。当位姿图的节点很少时,这些节点很可能是错误的。我们通过实验结果确定,少于10个节点的位姿图在人类位置误差方面存在极端误差。我们将这些图标记为错误,并从DSG中移除它们,这个过程我们称之为位姿图修剪。这类似于在视觉跟踪中移除短特征轨迹。最后,我们通过在位姿图上运行优化来缓解节点误差,使用静止运动先验,我们可以看到现有误差大大减少。
第3.6节 Kimera-Objects:对象姿态估计
在Kimera-DSG中,Kimera-Objects是从不
经Kimera-PGMO优化的度量-语义网格中提取静态对象的模块。我们为用户提供了灵活性,可以为某些对象类别提供CAD模型目录。如果提供了形状,Kimera-Objects将尝试将网格拟合到(“已知形状的对象”部分),否则它将仅尝试估计质心和边界框(“未知形状的对象”部分)。未知形状的对象。Kimera-PGMO优化的度量-语义网格已经包含语义标签。因此,Kimera-Objects首先提取属于给定对象类别(例如,图1(d)中的椅子)的网格部分;这个网格包含多个属于同一类别的对象。为了将网格分解为多个对象实例,Kimera-Objects执行欧几里得聚类,使用PCL(Rusu和Cousins,2011年)(距离阈值是Kimera-Semantics中使用的体素大小的两倍,为0.05m,即0.1m)。从分割的簇中,Kimera-Objects获得对象的质心(来自相应网格的顶点),并分配一个与世界框架对齐的规范方向。最后,它计算一个与规范方向对齐的边界框。已知形状的对象。如果为对象类别提供了CAD模型,Kimera-Objects将尝试将已知形状拟合到对象网格上。这分为三个步骤。首先,Kimera-Objects从CAD模型和相应的对象网格中提取3D关键点。通过将每个网格转换为点云(通过选择网格的顶点)并提取3D Harris关键点(Rusu和Cousins,2011年)来提取3D关键点,半径为0.15m,非最大抑制阈值为10^-4。其次,我们将CAD模型上的每个关键点与网格模型上的任何关键点匹配。显然,这一步产生了许多错误的假定匹配(异常值)。第三,我们应用一个鲁棒的开源注册技术,TEASER++(Yang等人,2020年),以在存在极端异常值的情况下找到点云之间最佳对齐。这三个步骤的输出是对象的3D姿态(从其中也可以轻松提取与轴对齐的边界框),见图1(e)中的结果。
第3.7节 Kimera-BuildingParser:提取地点、房间和结构
Kimera-BuildingParser实现了简单但有效的方法,从Kimera的3D网格中解析地点、结构和房间。
地点。Kimera-Semantics使用Voxblox(Oleynikova等人,2017年)提取全局网格和ESDF。我们还使用(Oleynikova等人,2018年)从ESDF中获得拓扑图,其中节点稀疏地采样自由空间,而边表示两个节点之间的直线可通行性。我们直接使用这个图来提取地点及其拓扑结构(图2(a))。创建地点后,我们将每个对象和代理姿态与最近的地点关联,以模拟接近关系。图11(左图)显示了3D ESDF的2D切片。欧几里得距离从红色(0m)编码到绿色(0.5m)。(右图)显示了截断的(≤0.10m)2D ESDF,揭示了房间的轮廓。两个图中都叠加了估计的房间布局(方形节点)及其连通性(黑色边)。
结构。Kimera的语义网格已经包含墙壁、地板和天花板的不同标签。因此,隔离这三个结构元素是直接的(图3)。对于每种类型的结构,我们计算一个质心,分配一个与世界框架对齐的规范方向,并计算一个与轴对齐的边界框。我们进一步根据它们所属的房间对墙壁进行分割。为此,我们利用3D网格顶点法线的方向性:每个顶点的法线指向相机。对于墙壁网格的每个3D顶点,我们查询在法线方向上最近的地点节点,并限制搜索半径为保守的0.5m。然后我们使用检索到的地点的房间ID为当前墙壁网格顶点的房间标签进行投票。为了使方法在两个房间相遇(例如门框)的情况下更加鲁棒,我们通过n·d ∥d∥^2 2加权地点的投票,其中n是墙壁顶点处的法线(单位范数)和d是从墙壁顶点到地点节点的向量。这种加权方法降低了不在墙壁顶点附近和前面的地点的投票权重。
房间。虽然在一般情况下计算楼层平面图是具有挑战性的,(i)3D ESDF的可用性以及(ii)由Kimera-VIO提供的重力方向知识,使我们能够采用简单但有效的方法将环境划分为不同的房间。关键的洞察是,3D ESDF的水平2D截面,低于检测到的天花板水平,相对不受房间内杂物的影响(图11)。这个2D截面为房间布局提供了清晰的特征:截面中的体素几乎到处都是0.3m(对应于到天花板的距离),除了靠近墙壁的地方,距离减少到0m。我们称这个在天花板下方0.3m处切割的2D ESDF为ESDF截面。
为了补偿噪声,我们进一步将ESDF截面截断到0.2m以上的距离,以便移除房间之间的小开口(可能由于误差累积而产生)。这个划分操作的结果是一组不相连的2D ESDF,对应于每个房间,我们称之为2D ESDF房间。然后,我们将所有落在2D ESDF房间内的“地点”(第3层的节点)根据它们的2D(水平)位置进行标记。此时,一些地点可能没有被标记(靠近墙壁或门内开口的地方)。为了标记这些地点,我们使用“地点”拓扑图中每个节点的邻域的多数投票;我们重复多数投票,直到所有地点都被标记。最后,我们在每个地点(第3层)和其对应的房间(第4层)之间添加边,见图2(b-c),如果两个地点之间有边连接,我们也在两个房间(第4层)之间添加边(图2(b-c)中的红色边)。我们也请读者参考第二个视频附件。
第3.8节 调试工具
Kimera还提供了一个开源的评估工具套件,用于调试、可视化和基准测试VIO、SLAM和度量-语义重建。Kimera包括一个持续集成服务器(Jenkins),它断言代码的质量(编译、单元测试),还自动评估Kimera-VIO、Kimera-RPGO和Kimera-PGMO在EuRoC数据集上的性能,使用evo(Grupp,2017年)。此外,我们提供了Jupyter Notebook,用于可视化中间VIO统计数据(例如,特征轨迹的质量,IMU预积分误差),以及自动评估3D重建的质量,使用Open3D(Zhou等人,2018a年)。
第4节 实验评估
我们首先在第4.1节中介绍用于评估的数据集,这些数据集包括真实和模拟场景,有无动态代理,以及各种环境(室内和室外,小型和大型)。第4.2节显示Kimera-VIO和Kimera-RPGO在EuRoC数据集上的姿态估计性能。第4.3节使用提供地面真实点云的EuRoC子集,展示Kimera的3D网格几何精度。第4.4节提供了Kimera-Mesher和Kimera-Semantics的3D度量-语义重建在uHumans数据集上的详细评估。第4.5节评估了Kimera-PGMO的定位和重建性能。第4.6节评估了人类和对象定位误差。第4.7节评估了将地点分割成房间的准确性。第4.8节突出了Kimera的实时性能,并分析了每个模块的运行时间。此外,第4.9节展示了Kimera在嵌入式计算机上运行时的实时性能如何扩展。最后,第4.10节定性地展示了Kimera在我们收集的真实数据集上的性能。
4.1 数据集
图12提供了用于评估的数据集的概览,而它们的特点在下面详细说明。
4.1.1 EuRoC。我们使用EuRoC数据集(Burri等人,2016年),该数据集以一架小型无人机在室内飞行,装有立体相机和IMU。EuRoC数据集总共包括十一个数据集,记录在两个不同的静态场景中。机器厅场景(MH)是工业设施的内部。Vicon房间(V)类似于办公室。每个数据集对VIO的难度不同,无人机的速度越快(数据集的数字索引越大,对VIO来说难度越大;例如,MH_01比MH_03对VIO来说更容易)。该数据集在所有数据集中都提供无人机的地面真实定位。此外,Vicon房间的地面真实点云也可用。对于我们的实验评估,我们使用EuRoC来分析Kimera-VIO、Kimera-RPGO和Kimera-PGMO的定位性能,以及Kimera-Mesher、Kimera-Semantics和Kimera-PGMO的几何重建。由于该数据集中没有动态
元素,也没有语义上有意义的对象,我们不使用它来评估网格的语义精度或对动态场景的鲁棒性。
4.1.2 uHumans和uHumans2。
为了评估度量-语义重建的准确性和对动态元素的鲁棒性,我们使用我们引入的uHumans模拟数据集(Rosinol等人,2020b年),并在此论文中进一步发布了新的uHumans2数据集。
uHumans和uHumans2是使用MIT Lincoln Laboratory提供的基于照片真实的Unity模拟器生成的,该模拟器提供传感器流(在ROS中)以及场景的几何和语义的地面真实,并且界面类似于(Sayre-McCord等人,2018年;Guerra等人,2019年)。
uHumans展示了一个大型办公空间,多个房间,以及数量不等的人类(例如12个和60个),如图1中重建的。尽管人类的数量不同,uHumans的问题在于每次运行的轨迹都不相同;因此,将定位误差与场景中的动态人类和VIO的固有漂移耦合在一起。出于这个原因,并且为了扩展数据集以适应其他场景,我们收集了uHumans2数据集。uHumans2展示了室内场景,如“公寓”、“地铁”和“办公室”场景,以及“邻里”室外场景。请注意,“办公室”场景在uHumans2中与uHumans中的相同,但轨迹不同。最后,为了避免对特定的2D语义分割方法产生偏见,我们使用地面真实的2D语义分割,我们请读者参考Hu和Carlone(2019年)以了解潜在替代方案的综述。
4.1.3 “AeroAstro”、“学校”和“白猫头鹰”。由于uHumans和uHumans2数据集是模拟的,我们进一步评估了我们的方法在三个真实数据集上的性能,这些数据集是我们收集的。这三个数据集包括使用手持设备记录的RGB-D和IMU数据。第一个数据集展示了MIT一个学术建筑内的学生隔间集合(“AeroAstro”),并使用自制的传感装置进行记录。第二个数据集在学校(“学校”)中记录,使用相同的自制传感装置。第三个数据集在公寓(“白猫头鹰”)中记录,使用Microsoft的Azure Kinect。为了收集“AeroAstro”和“学校”数据集,我们使用了一个自制的传感装置,设计用于在垂直配置中安装两个Intel RealSense D435i设备,如图13所示。虽然单个Intel RealSense D435i已经提供了Kimera-Core所需的RGB-D和IMU数据,但我们使用了两个没有重叠视野的相机,因为深度相机发射的红外模式会在图像中可见。这个红外模式使得图像不适合Kimera-VIO中的特征跟踪。因此,我们为用于VIO的一个RealSense相机禁用了红外模式发射器,而另一个相机则启用了红外发射器以捕获高质量的深度数据。由于相机没有共享相同的视野,用于跟踪的相机不受另一个相机发射的红外模式的影响。在记录“AeroAstro”和“学校”数据集之前,我们校准了IMU、两个RealSense相机的内参和外参。特别是,我们使用Intel提供的脚本校准了每个RealSense设备的IMU¶,使用Kalibr工具包(Furgale等人,2013年)校准了所有相机的内参和外参。此外,我们使用Kalibr扩展的IMU到IMU外参校准(Rehder等人,2016年)估计了两个RealSense设备之间的变换。由于相机没有共享相同的视野,我们不能使用相机到相机的外参校准。两个RealSense设备都使用硬件同步。“AeroAstro”场景包括一个大约40米的循环,穿过空间的内部,经过四个隔间组和一个小厨房,有两个不同时间出现的站立人类。“学校”场景由三个通过走廊连接的房间组成,轨迹大约20米长。为了收集“白猫头鹰”场景,我们使用了Azure Kinect,因为它提供了比Intel RealSense D435i更密集、更准确的深度图(见图14进行比较)。我们还使用Kalibr校准了相机和IMU的外参和内参(Furgale等人,2013年)。“白猫头鹰”场景包括一个大约15米长的轨迹,穿过三个房间:卧室、厨房和客厅。在厨房区域可以看到一个坐着的人类。最后,我们使用在COCO数据集(Abdulla,2017年)上预训练的模型权重的Mask-RCNN(He等人,2017年)对两个场景的RGB图像进行语义分割。
¶https://github.com/IntelRealSense/librealsense/tree/master/tools/rs-imu-calibration
图12. 用于评估的数据集概览。我们在各种数据集上评估Kimera,包括真实生活(顶行)和模拟(底行),室内和室外,小型和大型。
(a)透视图
(b)顶视图
图13. (a)-(b)用于重建“AeroAstro”和“学校”场景的数据收集装置,包括两个Intel RealSense D435i设备和一个NVIDIA Jetson TX2。
4.2 姿态估计
在本节中,我们评估Kimera-VIO和Kimera-RPGO的性能。表1比较了Kimera-VIO与最先进的开源VIO管道的绝对平移误差(ATE)的均方根误差(RMSE):OKVIS(Leutenegger等人,2013年),MSCKF(Mourikis和Roumeliotis,2007年),ROVIO(Bloesch等人,2015年),VINSMono(Qin等人,2018年),Basalt(Usenko等人,2019年)和ORB-SLAM3(Campos等人,2021年)。使用(Delmerico和Scaramuzza,2018年)中独立报告的值和各自作者的自我报告值。请注意,OKVIS、MSCKF、ROVIO和VINS-Mono使用单目相机,其余使用立体相机。我们在评估误差之前对估计和地面真实轨迹进行SE(3)变换对齐。使用Sim(3)对齐,如(Delmerico和Scaramuzza,2018年)所述,会使Kimera的误差更小,但我们更倾向于SE(3)对齐,因为它更适合VIO,其中尺度是可观察的,这要归功于IMU。我们根据它们是否使用固定滞后平滑或循环闭合进行分组。Kimera-VIO、Kimera-RPGO和Kimera-PGMO(见第4.5节)实现了竞争性能。我们还比较了Kimera-VIO与SVO-GTSAM(Forster等人,2014年,2015年)在我们的先前论文(Rosinol等人,2020a年)中。此外,Kimera-RPGO确保了鲁棒性能,并且对循环闭合参数调整不太敏感。表2显示了不同循环闭合阈值α下Kimera-RPGO的准确性,这些值在DBoW2中使用。较小的α值会导致更多的循环闭合检测,但这些不太保守(更多的异常值)。表2显示,通过使用PCM,Kimera-RPGO对α的选择相当不敏感。表1中的结果使用α = 0.001。
4.2.1 动态场景中姿态估计的鲁棒性。
表4报告了使用5点RANSAC、2点RANSAC以及使用2点RANSAC和IMU感知特征跟踪(标签:DVIO)时Kimera的绝对轨迹误差。最低误差(最佳结果)以粗体显示。MH_01-V2_03行,对应于静态EuRoC数据集的测试,证实了在没有动态代理的情况下,所提出的方法与最新技术表现相当,而2点RANSAC的使用已经提高了性能。其余行(uHumans和uHumans2)进一步表明,在动态实体数量增加的情况下(第三列的人数),所提出的DVIO方法保持鲁棒。
4.3 几何重建
现在我们展示Kimera的准确姿态估计和对动态场景的鲁棒性如何提高重建的几何精度。我们使用EuRoC V1和V2数据集中提供的地面真实点云来评估Kimera产生的3D网格的质量。我们使用(Rosinol,2018年,第4.3节)中的准确性和完整性度量来评估每个网格与地面真实的对比:(i)我们通过以103点/平方米的均匀密度对网格进行采样来计算点云,(ii)我们使用ICP(Besl和Mackay,1992年)在CloudCompare(Cloudcompare.org,2019年)上注册估计和地面真实点云,(iii)我们评估从地面真实点云到估计点云最近邻的距离(准确性),反之亦然(完整性)。图15(a)显示了由Kimera-Semantics对V1_01数据集的全局网格估计的云,颜色编码为与地面真实云的距离;图15(b)显示了地面真实云,颜色编码为与估计云的最近点的距离。
图14显示了来自Intel RealSense D435i(左图)和Azure Kinect(右图)RGB-D相机的3D点云的侧视图,从同一场景和视点。中间的放大视图显示Azure Kinect提供的深度估计质量高于RealSense。尽管存在这些差异,Kimera对噪声是鲁棒的,如第4.10节所示。
表1列出了与最新开源VIO管道相比,Kimera在EuRoC数据集上的绝对平移误差(ATE)的均方根误差(RMSE)。粗体显示了每个类别的最佳结果:固定滞后平滑和带有循环闭合的PGO。−表示缺少数据。
绝对平移误差(ATE)的均方根误差(RMSE)[m]
固定滞后平滑 循环闭合 EuRoC序列 OKVIS MSCKF ROVIO VINSMono Kimera-VIO Basalt ORB-SLAM3 VINS-LC Kimera-RPGO Kimera-PGMO MH_1 0.16 0.42 0.21 0.15 0.11 0.08 0.04 0.12 0.13 0.09 MH_2 0.22 0.45 0.25 0.15 0.10 0.06 0.03 0.12 0.21 0.11 MH_3 0.24 0.23 0.25 0.22 0.16 0.05 0.04 0.13 0.12 0.12 MH_4 0.34 0.37 0.49 0.32 0.16 0.10 0.05 0.18 0.12 0.16 MH_5 0.47 0.48 0.52 0.30 0.15 0.08 0.08 0.21 0.15 0.18 V1_1 0.09 0.34 0.10 0.08 0.05 0.04 0.04 0.06 0.06 0.05 V1_2 0.20 0.20 0.10 0.11 0.08 0.02 0.01 0.08 0.05 0.06 V1_3 0.24 0.67 0.14 0.18 0.13 0.03 0.02 0.19 0.11 0.13 V2_1 0.13 0.10 0.12 0.08 0.06 0.03 0.03 0.08 0.06 0.05 V2_2 0.16 0.16 0.14 0.16 0.07 0.02 0.01 0.16 0.06 0.07 V2_3 0.29 1.13 0.14 0.27 0.21 - 0.02 1.39 0.24 0.23
表2. EuRoC V1_01数据集上不同循环闭合阈值α下的绝对平移误差(ATE)的均方根误差(RMSE)[m]。
α 101 100 10^-1 10^-2 10^-3 PGO w/o PCM 0.05 0.45 1.74 1.59 1.59 Kimera-RPGO 0.05 0.05 0.05 0.05 0.05
图15. (a)Kimera的3D网格估计,颜色编码为与地面真实点云的距离。(b)地面真实点云,颜色编码为与估计云的最近点的距离。EuRoC V1_01数据集。
表3提供了Kimera-Mesher产生的快速多帧网格与Kimera-Semantics通过TSDF产生的慢速网格之间的定量比较。为了从Kimera-Mesher获得完整的网格,我们设置了一个大的VIO范围(即,我们执行全平滑)。
正如图15(a)所预期的,Kimera-Semantics的全局网格非常准确,平均误差在0.35-0.48米之间。Kimera-Mesher产生了一个更嘈杂的网格(误差增加高达24%),但计算速度低两个数量级(见第4.8节)。
表3. 使用ICP阈值为1.0m时,Kimera多帧和全局网格的完整性评估(Rosinol,2018年,第4.3.3节)。
均方根误差(RMSE)[m] 相对改进率[%] EuRoC序列 多帧 全局 V1_01 0.482 0.364 24.00 V1_02 0.374 0.384 -2.00 V1_03 0.451 0.353 21.00 V2_01 0.465 0.480 -3.00 V2_02 0.491 0.432 12.00 V2_03 0.530 0.411 22.00
4.3.1 动态场景中网格重建的鲁棒性。
这里我们展示DVIO(在第4.2.1节中量化)的增强鲁棒性,结合动态掩蔽(第3.5节),在拥挤的动态环境中实现鲁棒和准确的度量-语义网格。
动态掩蔽。图16可视化了动态掩蔽对Kimera度量-语义网格重建的影响。图16(a)显示了没有动态掩蔽时,一个在相机前走动的人类在网格中留下了“尾迹”(青色),并在网格中创建了伪影。图16(b)显示了动态掩蔽避免了这个问题,并导致了干净的网格重建。表5报告了有和没有动态掩蔽的Kimera-Semantics的RMSE网格误差。为了独立于VIO定位误差评估网格精度,我们还报告了使用地面真实姿态(“GT姿态”列)与使用VIO姿态(“DVIO姿态”列)时的网格几何误差。表中的“GT姿态”列显示,即使在完美的定位下,动态实体(如图16(a)中所示)创建的伪影显著阻碍了网格精度,而动态掩蔽确保了高度准确的重建。当使用VIO姿态时,动态掩蔽的优势得以保持。值得一提的是,表5中的3D网格误差与表1中的定位误差相比要小,这是因为地板是所有重建中最可见的表面,由于我们的轨迹高度估计(z估计)非常准确,大多数网格误差都很小。我们还使用ICP对地面真实3D网格与估计的3D网格进行对齐,这进一步减少了网格误差。
表5. 在uHumans和uHumans2数据集中,使用地面真实姿态(GT姿态)和DVIO估计姿态(DVIO姿态)的Kimera-Semantics的3D网格RMSE[m],有和没有动态掩蔽(DM)。
Kimera-Semantics 3D网格RMSE [m] GT姿态 DVIO姿态 数据集 场景 人数 无DM 有DM 无DM 有DM uHumans 办公室 12 0.09 0.06 0.23 0.23 24 0.13 0.06 0.35 0.30 60 0.19 0.06 0.35 0.33 uHumans2 办公室 0 0.03 0.03 0.16 0.16 6 0.03 0.03 0.21 0.17 12 0.03 0.03 0.18 0.13 邻里 0 0.06 0.06 0.27 0.27 24 0.08 0.06 0.66 0.61 36 0.08 0.06 0.70 0.65 地铁 0 0.06 0.06 0.42 0.42 24 0.19 0.06 0.58 0.53 36 0.19 0.06 0.
49 0.43 公寓 0 0.05 0.05 0.06 0.06 1 0.05 0.05 0.07 0.07 2 0.05 0.05 0.07 0.07
4.4 语义重建
Kimera-Semantics基于VIO姿态估计构建3D网格,并结合密集立体视觉(如果可用)和捆绑射线投射。我们通过进行三种不同的实验来评估每个组件的影响。对于这些实验,我们使用(Rosinol等人,2020a年)中的模拟数据集,该数据集具有地面真实语义和几何形状,允许我们确定每个模块对性能的影响。首先,我们使用具有地面真实(GT)姿态和地面真实深度图的Kimera-Semantics来评估捆绑射线投射导致的初始性能损失。其次,我们使用Kimera-VIO的姿态估计。最后,我们使用包括密集立体视觉在内的完整Kimera-Semantics管道。为了分析语义性能,我们计算了平均交并比(mIoU)(Hackel等人,2017年),以及正确标记点的整体部分(Acc)(Wolf等人,2015年)。我们还报告了与Kimera-VIO的漂移相关的ATE。最后,我们通过注册估计的网格与地面真实网格来评估度量重建,并计算点的RMSE,如第4.3节所述。表6总结了我们的发现,表明捆绑射线投射在几何上(<8cm误差的3D网格)和语义上(准确率>94%)导致了小的性能下降。使用Kimera-VIO也导致了微不足道的性能损失,因为我们的VIO的漂移很小(<0.2%,对于32米长的轨迹为4cm)。当然,最大的性能下降是由于使用密集立体视觉。密集立体视觉(H. Hirschmüller,2008年)在解析无纹理区域(如墙壁)的深度方面存在困难,这在模拟场景中很常见。图17显示了使用具有Kimera-VIO和地面真实深度的Kimera-Semantics的混淆矩阵(图17(a)),与使用密集立体视觉的混淆矩阵(图17(b))的比较。混淆矩阵中的大型值出现在Wall/Shelf和Floor/Wall之间。这正是密集立体视觉最困难的地方;无纹理的墙壁很难重建,并且接近架子和地板,导致几何和语义误差增加。
图17. 使用捆绑射线投射和(a)地面真实立体深度或(b)密集立体视觉的Kimera-Semantics的混淆矩阵。两个实验都使用地面真实2D语义。值为104以供可视化。
4.5 循环闭合和网格变形
在EuRoC中的定位和几何评估。我们在表4(最后一列)中评估了Kimera-PGMO在定位误差方面的性能。我们观察到Kimera-PGMO在大规模场景(如“邻里”和“地铁”场景)中实现了显著的改进,这些场景中累积的ATE是明显的。相反,在EuRoC中,DVIO已经实现了非常准确的定位,Kimera-PGMO可能只在定位上提供边际收益。请注意,表4中Kimera-PGMO的定位误差与表1中Kimera-RPGO的定位误差不同,因为Kimera-RPGO不优化网格,与Kimera-PGMO相反。我们根据EuRoC数据集中的地面真实点云评估Kimera-PGMO的几何误差。表7显示Kimera-PGMO的3D网格比未优化的Kimera-Semantics 3D网格实现了更好的几何精度。有关Kimera-PGMO效果的定性可视化,请参见图18,展示了EuRoC V1_01数据集的网格重建,在和在变形之前和之后。
图18. EuRoC V1_01数据集的重建,循环闭合之前和Kimera-PGMO变形之后。轨迹RMSE在循环闭合应用之前为15厘米,循环闭合在Kimera-PGMO中优化后为13厘米。
在uHumans和uHumans2中的度量-语义评估。我们进一步评估了在uHumans和uHumans2数据集中变形网格对度量-语义重建的影响。表7显示了Kimera-PGMO与DVIO相比的重建误差的RMSE,以及正确语义匹配的百分比。我们观察到,与使用DVIO姿态估计的未优化3D网格相比,Kimera-PGMO的网格变形实现了最佳的几何和语义性能。
4.6 解析人类和对象
在这里,我们在uHumans数据集上评估了人类跟踪和对象定位的准确性。
人类节点。表8显示了uHumans数据集中每个人类的平均定位误差(骨盆估计位置与地面真实的不匹配)。每一列都增加了提高性能的模型特征。第一列报告了由Kolotouros等人(2019b年)(标签:“单图像”)产生的检测误差。第二列报告了我们过滤掉在相机图像中只有部分可见的人类或人类边界框太小(≤30像素,标签:“单图像过滤”)时的误差。第三列报告了我们在第3.5节讨论的提出的位姿图模型(标签:“位姿图轨迹”)的误差,包括PCM异常值拒绝和位姿图修剪。第四列报告了当启用网格可行性检查进行数据关联时(标签:“网格检查”)的误差,第五列报告了启用beta参数数据关联技术时(标签:“Beta检查”)的误差。模拟器中的人类都有在已知范围内随机化的beta参数,以更好地近似真实人类外观的分布。Graph-CNN方法(Kolotouros等人,2019b)对SMPL检测倾向于在人类被遮挡时产生不正确的估计。过滤掉这些检测提高了定位性能,但场景中由于物体遮挡导致的遮挡仍然导致显著误差。添加网格可行性检查通过在检测注册后使数据关联更有效来减少误差。beta参数检查也显著减少了误差,表明可以使用SMPL身体参数估计进行有效的数据关联。只有公寓场景没有遵循趋势;结果最好不使用任何提出的技术。这些是异常结果;公寓环境有许多镜面反射,可能导致了错误的检测。这些对象类别包括“沙发”、“椅子”和“汽车”(我们从Unity的3D资产商店获得)。在这两种情况下,我们都可以正确地定位对象,而CAD模型的可用性进一步提高了准确性。值得注意的是,我们数据集中的大多数已知对象都是在运行初期可视化的,当定位漂移较低时,使得对象定位几乎与漂移无关。最后,我们在评估对象定位误差之前使用ICP对3D地面真实网格与估计的3D网格进行对齐。
4.7 解析地点和房间
我们还计算了将地点分类为房间的平均精度和召回率。地面真实标签是通过手动分割地点获得的。对于uHumans2中的“办公室”(图1)和“地铁”(图24)场景,我们分别获得了99%和87%的平均精度,以及99%和92%的平均召回率。同样,对于真实生活的“白猫头鹰”(图21左侧DSG)和“学校”(图22)场景,我们分别实现了93%和91%的精度,以及94%和90%的平均召回率。实际上,“办公室”、“地铁”、“白猫头鹰”和“学校”场景中的所有房间都被正确检测到,地点被精确标记。不正确的地点分类通常发生在门附近,房间的误分类是不重要的。
然而,我们的方法在处理复杂建筑,如uHumans2中的“公寓”(图21右侧DSG),以及大量不完整的场景,如“航空宇航”数据集(图23)时存在困难。特别是对于“公寓”场景,暴露的天花板梁以一种方式扭曲了2D ESDF场,以至于客厅被过度分割为三个独立的房间:“R1”、“R3”和“R6”应该是图21右侧DSG中的一个房间节点。“公寓”场景的地点分割的精度和召回率分别为68%和61%。对于“航空宇航”场景(图23),平行的走廊“R1”也被过度分割为“R3”、“R5”和“R2”。在这种情况下,走廊中观察到的自由空间在“R2”和“R5”之间,以及“R5”和“R3”之间显著变窄,正如拓扑图中节点的密度所示。“航空宇航”场景的地点分割的精度和召回率分别为71%和67%。注意,通过对房间检测参数进行仔细调整,可以避免这种过度分割(第3.7节)。我们还讨论了在执行路径规划查询时房间过度分割的影响(第6.1节)。最后,我们注意到DSG足够通用,可以处理户外场景,如“邻里”场景(图25),在这种情况下,一些层(房间、建筑物)被跳过。
4.8 计时
图19报告了Kimera-Core模块的计时性能。IMU前端需要大约40
微秒进行预积分,因此它可以以IMU速率(>200 Hz)生成状态估计。视觉前端模块显示出双峰分布,因为对于每一帧,我们只执行特征跟踪(平均需要7.5毫秒),而在关键帧速率下,我们执行特征检测、立体匹配和几何验证,总共平均需要51毫秒。Kimera-Mesher能够在不到7毫秒内生成每帧3D网格,而构建多帧网格平均需要15毫秒。后端在不到60毫秒内解决因子图优化。循环闭合检测(LCD)最多需要180毫秒来寻找循环闭合候选者并执行几何验证和计算相对变换。Kimera-RPGO在我们的EuRoC实验中最多需要50毫秒,用于具有734条边和728个节点的姿态图,但通常其运行时间取决于姿态图的大小。同样,Kimera-PGMO在我们的EuRoC实验中最多需要140毫秒,用于具有14914条边和1759个节点的姿态图(728个姿态节点和1031个网格节点),但通常其运行时间取决于姿态图的大小、网格的大小和简化网格的分辨率。最后,Kimera-Semantics(为了清晰起见,未在图中报告)平均需要0.1秒来更新每个关键帧的全局度量-语义网格。Kimera-DSG的模块在Kimera-Core构建3D度量-语义网格后顺序运行。Kimera-Objects从3D度量-语义网格中分割对象实例需要几分钟,取决于场景的规模(从“白猫头鹰”场景的约100平方米的3分钟到最大的“地铁”场景的约3000平方米的12分钟),其中每个对象类别的实例分割是顺序进行的(可以并行化)。对于已知对象,Kimera-Objects使用TEASER++拟合CAD模型,运行速度为毫秒级(有关TEASER++的计时性能详细信息,请参见(Yang等人,2020年))。Kimera-Humans首先使用GraphCMR(Kolotouros等人,2019b)检测人类,这在单个图像上需要大约33毫秒,在Nvidia RTX 2080 Ti GPU上,跟踪在CPU上以毫秒级(大约10毫秒)进行。Kimera-BuildingParser首先使用Voxblox(Oleynikova等人,2017年)从TSDF构建ESDF,这可能需要几分钟,取决于场景的规模(对于大型场景如“地铁”大约需要10分钟)。然后,使用(Oleynikova等人,2018年)构建拓扑图,这也需要几分钟,取决于场景的规模(对于“地铁”需要大约10分钟)。最后,检测房间、将地点分割为房间以及找到房间之间的连通性需要几分钟,这也取决于场景的规模(对于“地铁”场景大约需要2分钟)。因此,对于“地铁”这样的大型场景,构建DSG可能需要大约30分钟,其中计算ESDF、拓扑图和对象实例分割是最耗时的操作。
4.9 在NVIDIA TX2嵌入式计算机上的计时
我们还评估了Kimera在许多机器人应用中常见的低SWaP处理器上的性能,即Nvidia Jetson TX2。对于TX2的所有基准测试,我们使用nvpmodel使用MAXN性能模式。我们将分析限于Kimera-Core。Kimera-VIO能够在默认设置下实时运行EuRoC,但我们也理解可能有对延迟或处理时间更敏感的应用。因此,我们分析了各种参数设置对Kimera-VIO运行时间的影响。我们确定了两个候选参数:(i)跟踪的最大特征数(maxFeaturesPerFrame),以及(ii)平滑的时间范围(horizon)。基于此分析,我们在开源存储库中提供了两组额外的参数:快速(最大250个特征和5秒的时间范围)和更快(最大200个特征和4.5秒的时间范围)的参数配置。图20显示了这些设置对TX2上Kimera-VIO处理时间的影响。对于所有配置,前端模块在非关键帧上平均需要10毫秒。快速和更快的配置分别需要关键帧的75%和50%的处理时间,以及后端的65%和50%的处理时间,与默认设置相比。请注意,在EuRoC的更具挑战性部分,Kimera-VIO的准确性在快速和更快的配置下会降低,这在所有情况下都可能不是所期望的。这在EuRoC的困难机器厅序列的APE增加中最为明显,如图20所示。此外,我们使用EuRoC数据集再次描述了Kimera-Semantics的计时。对于Kimera-VIO和Kimera-Semantics,默认设置,特别是体素大小为0.1米,我们能够实现实时操作的合适性能。Kimera-Semantics的更新平均需要65.8毫秒,跨越EuRoC。请注意,EuRoC数据不包括语义标签,因此体素大小可能仍需要调整以在其他情况下保持实时性能。
4.10 真实生活实验
在本节中,我们定性评估Kimera从真实生活数据集中生成DSG的能力,这些数据集是使用我们自制的传感装置(图13)收集的“学校”和“航空宇航”数据集,或使用Microsoft的Azure Kinect相机收集的“白猫头鹰”数据集,如第4.1节所述。
4.10.1 “学校”和“航空宇航”。
图22显示了Kimera重建的“学校”数据集的DSG,以及Kimera-Core重建的3D网格。我们注意到,尽管Intel RealSense D435i的深度流质量(见图14)导致3D网格嘈杂和不完整,但Kimera-Core重建的3D网格在全球范围内是一致的。特别是,Kimera-PGMO能够利用循环闭合同时变形网格和优化传感器的轨迹。尽管3D网格嘈杂和不完整,Kimera-DSG能够构建一个有意义的场景DSG。Kimera-Objects正确检测到大多数对象,并近似一个保守的边界框。然而,也存在一些错误检测。例如,图22中的绿色节点应该是冰箱,但“学校”数据集中没有冰箱。这些错误检测可以通过微调有效检测的最小对象大小,或通过在此场景中重新训练Mask-RCNN来轻松移除。还可以阻止Mask-RCNN检测此场景中不存在的某些对象类别。图22还显示,Kimera正确重建了地点层,并准确将地点分割成房间。DSG中的房间层准确地表示了场景的布局,有一个走廊(“R3”)和三个房间(“R1”、“R2”、“R4”)。DSG中房间之间的边正确表示了房间之间的可通行性。3D网格的嘈杂和不完整性似乎并没有对DSG的更高层次的抽象产生负面影响。图23显示了Kimera重建的“航空宇航”数据集的DSG。与“学校”数据集类似,Kimera-Core能够重建一个一致的3D网格,尽管由于我们使用了相同的传感器,网格仍然嘈杂和不完整。虽然对象和地点层被正确估计,但Kimera-BuildingParser过度分割了房间。特别是,Kimera-BuildingParser将一个走廊过度分割为三个房间(“R2”、“R3”、“R5”)。这是因为,在穿过走廊时,传感器被保持得太靠近墙壁,从而限制了观察到的自由空间。因此,ESDF和地点层在“R2”和“R5”之间,以及“R5”和“R3”之间显著变窄。这种变窄被Kimera误解释为房间之间的分隔,导致走廊的过度分割。
4.10.2 “白猫头鹰”。
为了进一步评估Kimera构建DSG的性能,我们使用高质量的深度相机,Microsoft的Azure Kinect,重建场景的准确和完整的3D网格。图21显示了使用Microsoft的Azure Kinect传感器收集的“白猫头鹰”场景的DSG(左图),以及模拟的uHumans2“公寓”场景的DSG(右图),两者都由Kimera重建。值得注意的是,无论数据是由真实生活(左图)还是模拟(右图)传感器生成的,Kimera都能够重建一个全局一致的3D网格以及一个连贯的DSG,同时使用相同的一组参数。此外,两种重建在质量上相似,表明我们的模拟是现实的,也表明,只要有足够的准确的深度传感器,Kimera就可以在真实数据上实现准确的重建。在“白猫头鹰”数据集上,我们仍然观察到一些错误的对象检测(例如,绿色节点)。地点和房间层的DSG保持准确,并正确表示场景和层之间的连通性。
5 激励示例
我们通过提供它启用的查询示例来突出3D动态场景图的可操作性。避碍和规划。我们的DSG中的代理、对象和房间都有边界框属性。此外,DSG的层次性质确保了较高层的边界框包含较低层的边界框(例如,房间的边界框包含该房间中的对象)。这形成了一个边界体积层次结构(BVH)(Larsson和Akenine-Möller,2006年),它在计算机图形中广泛用于碰撞检查。BVH提供了现成的机会,可以加速障碍物避让和运动规划查询,其中碰撞检查通常是原语(Karaman和Frazzoli,2011年)。人机交互。正如(Armeni等人,2019年;Kim等人,2019年)已经探索的,场景图可以支持用户导向的任务,如交互式可视化和问题回答。我们的动态场景图通过(i)允许可视化人类轨迹和密集姿态(见视频附件中的可视化),以及(ii)启用更复杂和时间感知的查询,例如“这个人在时间t在哪里?”或“这个人在房间A中拿起了哪个对象?”来扩展(Armeni等人,2019年;Kim等人,2019年)的范围。此外,DSG提供了一个框架,用于模拟代理和场景之间的合理交互(Zhang等人,2019年b;Hassan等人,2019年;Pirk等人,2017年;Monszpart等人,2019年)。我们认为DSG也补充了自然语言接地的工作(Kollar等人,2017年),其中主要关注点之一是推理人类指令的变异性。长期自主性。DSGs为“忘记”或保留长期自主性中的信息提供了自然方式。根据构造,DSG中的较高层是场景的更紧凑和抽象的表示。因此,机器人可以通过简单地修剪DSG中的相应分支来“忘记”不经常观察到的环境部分。例如,要忘记图1中的一个房间,我们只需要修剪相应的节点以及较低层(地点、对象等)的连接节点。更重要的是,机器人可以有选择地决定保留哪些信息:例如,它可以保留所有对象(这些通常存储成本较低),但可以选择性地忘记网格模型,这在大型环境中可能更难以存储。最后,DSG继承了标准场景图提供的记忆优势:如果机器人检测到N个已知对象(例如,椅子)的实例,它只需存储一个CAD模型,并在场景图中的N个节点中进行交叉引用;这个简单的观察进一步实现了数据压缩。预测。结合密集的度量-语义网格模型和对代理的丰富描述,可以执行场景动态的短期预测,并回答有关可能的未来结果的查询。例如,可以将网格模型输入到物理模拟器中,并模拟人类代理的潜在高级动作。
6 应用
在剩余部分,我们介绍我们开发的两个特定应用,并在第6.3节中评估它们。
6.1 层次路径规划
DSG提供的多个抽象层次有潜力启用层次和多分辨率规划方法(Schleich等人,2019年;Larsson等人,2019年),其中机器人可以在不同的抽象层次上规划以节省计算资源。实际上,在体积地图上查询从一个点到另一个点的路径在计算上是昂贵的,即使是在小场景中也是如此。有了DSGs,我们可以改为以层次方式计算路径,这通过几个数量级加速了路径规划查询。为了展示这种能力,我们首先在建筑物层面上计算可行的最短路径(使用A*)。给定要遍历的建筑物节点,我们提取它们的房间层,并在该层面上重新规划。类似地,给定要遍历的房间节点,我们进一步提取相关的地方图,并在该层面上再次规划。最后,我们提取一个平滑的无碰撞路径,使用(Oleynikova等人,2016年,2018年)的开源工作。虽然在体积ESDF层面上查询路径需要几分钟,但类似的查询在更高抽象层次上在毫秒级完成(第6.3节)。请注意,正如第3.7节中提到的,Kimera可能会在DSG中将一个房间过度分割为多个房间。尽管如此,由于这种过度分割通常很小(2或3个房间),层次路径规划的运行时间仍将保持在毫秒级。
6.2 语义路径规划
DSG还为涉及自然语言的高级路径规划查询提供了强大的工具,利用语义地图和不同的抽象层次。例如,DSG中的地方和对象的(连接)子图可以用来向机器人发出高级命令(例如,对象搜索(Joho等人,2011年)),机器人可以直接推断出它必须到达DSG中的最近地点以完成任务,并可以规划一条可行的路径到达那个地方。相比之下,体积表示不适合高级路径规划查询,因为操作员需要向机器人提供度量坐标。有了DSGs,用户可以使用自然语言(“到达房间y中的任何对象x”)。在第6.3节中,我们展示了我们给机器人的语义查询示例,并将其用作层次路径规划的输入。
6.3 DSG上的路径规划性能
表9显示了我们的语义层次路径规划实现的计时性能,我们运行A在建筑物、房间和地方层面,以层次方式进行,如第6.1节所述,并将其计时性能与直接在体积ESDF表示上运行A进行比较。为了进一步强调我们方法的可扩展性,我们将uHumans数据集中的“办公室”场景(见图1a和图11中的楼层平面图)以网格状模式复制,以增加其规模(其中每个新“办公室”场景被视为一个建筑物)。如图所示,层次路径规划在几个数量级上优于在体积ESDF层面上规划的计时性能,从而使路径规划在大规模场景中以交互速度运行。我们还报告了使用ESDF和使用层次路径规划方法时估计轨迹的长度。我们观察到,尽管我们的层次方法的轨迹更长,但表9中的轨迹与ESDF的轨迹几乎一样短。此外,提供给我们的层次路径规划模块的查询是:“在建筑物z的房间y中的任何对象x附近”,其中x ∈ X,X = {房间y中的建筑物z的对象},y ∈ Y,Y = {建筑物z的房间},z ∈ Z = {1, ..., N},N是场景中的建筑物数量。这与度量坐标x,y,z ∈ R^3形成鲜明对比;这表明能够在DSG上运行语义有意义的路径规划查询。
表9. 在不同抽象层次上使用A*进行层次语义路径规划。在建筑物(B)、房间(R)和地方(P)层面进行规划,与直接在体积ESDF层面上规划相比,计时性能快几个数量级。我们将办公室场景的3D DSG从uHumans复制并形成一个网格状的办公室区域,其中每个办公室被视为一个建筑物;因此创建了一个更大场景。我们还显示了路径中的节点和边的数量,以及估计轨迹的长度进行比较。
计时[s] 节点[#]/边[#] 路径长度[m] 数据集 场景 #B ESDF 层次路径规划 P R B ESDF 层次 P R B 总计 uHumans 办公室 1 420.4 0.339 0.001 0.000 0.340 89 / 120 16 / 9 1 / 0 54.2 56.3 2 944.8 0.771 0.004 0.000 0.775 178 / 241 32 / 19 2 / 1 101.2 109.8 6 21389.2 1.231 0.012 0.001 1.244 534 / 730 96 / 64 6 / 7 311.5 329.2
图21. (左图)使用Microsoft Azure Kinect传感器收集的“白猫头鹰”公寓的DSG(左上),重建的3D网格的俯视图(左下)。(右图)模拟的uHumans2“公寓”场景的DSG(右上),重建的3D网格的俯视图(右下)。注意,尽管数据是由真实生活(左图)和模拟(右图)传感器生成的,Kimera都能够重建一个全局一致的3D网格和一个连贯的DSG,使用相同的一组参数。
图22. (上)使用自制传感装置和Intel RealSense D435i传感器的“学校”数据集的DSG(图22顶部),Kimera重建的3D网格(图22底部)。尽管由于Intel RealSense D435i的深度流质量,重建的3D网格嘈杂和不完整,但DSG正确地将场景抽象为三个房间和一个走廊(“R3”)。
7 相关工作
我们回顾了机器人学和计算机视觉中使用的环境表示(第7.1节),以及构建这些表示所涉及的算法(第7.2节)。
7.1 世界表示 场景图。
场景图是计算机图形中流行的模型,用于描述、操作和渲染复杂场景,通常用于游戏引擎(Wang和Qian,2010)。虽然在游戏应用中,这些结构用于描述3D环境,但场景图主要用于计算机视觉中抽象2D图像的内容。Krishna等人(2016)使用场景图来模拟2D图像中对象的属性和关系,依赖于手动定义的自然语言标题。Xu等人(2017)和Li等人(2017)开发了2D场景图生成算法。2D场景图已用于图像检索(Johnson等人,2015)、描述(Krause等人,2017;Anderson等人,2016;Johnson等人,2017)、高级理解(Choi等人,2013;Zhao和Zhu,2013a;Huang等人,2018b;Jiang等人,2018)、视觉问题回答(Fukui等人,2016;Zhu等人,2016)和动作检测(Lu等人,2016;Liang等人,2017)。Armeni等人(2019)提出了一个3D场景图模型来描述3D静态场景,并描述了一个半自动算法来构建场景图。与(Armeni等人,2019)平行,Kim等人(2019)提出了一个用于机器人学的3D场景图模型,但只包括对象作为节点,错过了(Armeni等人,2019)和我们的提议所提供的一些抽象层次。机器人学中的表示和抽象。世界建模和地图表示问题自机器人学诞生以来就一直是中心议题(Thrun,2003;Cadena等人,2016)。需要使用层次地图来捕获丰富的空间和语义信息的需求已经在Kuipers、Chatila和Laumond(Kuipers,2000,1978;Chatila和Laumond,1985)的开创性论文中得到认可。Vasudevan等人(2006)提出了一个对象星座的层次表示。Galindo等人(2005)使用两个并行的层次表示(一个空间表示和一个语义表示),然后将其锚定在一起,并使用2D激光雷达数据进行估计。Ruiz-Sarmiento等人(2017)扩展了(Galindo等人,2005)的框架,以考虑空间和语义元素之间的不确定接地。Zender等人(2008)提出了一个单一的层次表示,包括一个2D地图、一个导航图和一个拓扑图(Ranganathan和Dellaert,2004;Remolina和Kuipers,2004),然后进一步抽象为一个概念图。注意,(Galindo等人,2005)和(Zender等人,2008)中的空间层次结构已经类似于场景图,但节点和层次的集合较少。一个更根本的区别是早期工作(i)没有对3D模型进行推理(但专注于2D占用地图),(ii)没有处理动态场景,以及(iii)没有包括密集的(例如,像素级)语义信息,这在近年来通过深度学习方法得以实现。
7.2 感知算法 动态环境中的SLAM和VIO。
本文还涉及对场景中动态元素的建模和鲁棒性。SLAM和移动对象跟踪(有时称为SLAMMOT(Wang等人,2007)或SLAM和检测与跟踪移动对象,DATMO(Azim和Aycard,2012))在机器人学中得到了广泛研究(Wang等人,2007),而更近期的工作集中在联合视觉-惯性里程计和目标姿态估计(Qiu等人,2019;Eckenhoff等人,2019;Geneva等人,2019)。大多数现有文献在机器人学中将动态目标建模为一个3D点(Chojnacki和Indelman,2018),或具有3D姿态,并依赖于激光雷达(Azim和Aycard,2012)、RGB-D相机(Aldoma等人,2013)、单目相机(Li等人,2018b)和视觉-惯性传感(Qiu等人,2019)。相关工作还尝试通过对动态场景使用IMU(Hwangbo等人,2009)来获得鲁棒性,通过掩蔽对应动态元素的场景部分(Cui和Ma,2019;Brasch等人,2018;Bescos等人,2018),或联合跟踪相机和动态对象(Wang等人,2007;Bescos等人,2020)。据我们所知,本文是第一个尝试执行视觉-惯性SLAM、分割密集对象模型、估计已知对象的3D姿态,并重建和跟踪密集人类SMPL网格的工作。度量-语义场景重建。这一领域的工作涉及从传感器数据中估计度量-语义(但通常是非层次的)表示。早期工作(Bao和Savarese,2011;Brostow等人,2008)集中在离线处理,近年来对实时度量-语义映射的兴趣激增,由SLAM++(Salas-Moreno等人,2013)等开创性工作引发。基于对象的方法计算对象图,包括SLAM++(Salas-Moreno等人,2013)、XIVO(Dong等人,2017)、OrcVIO(Shan等人,2019)、QuadricSLAM(Nicholson等人,2018)和(Bowman等人,2017)。对于大多数机器人应用,基于对象的图不能为导航和避障提供足够的分辨率。密集方法构建更密集的语义注释模型,形式为点云(Behley等人,2019;Tateno等人,2015;Dubé等人,2018;Lianos等人,2018)、网格(Rosinol等人,2020a;Rosu等人,2019)、surfels(Whelan等人,2015;Rünz等人,2018;Wald等人,2018)或体积模型(McCormac等人,2017;Rosinol等人,2020a;Grinvald等人,2019;Narita等人,2019)。其他方法同时使用对象和密集模型,参见Li等人(2016)和Fusion++(McCormac等人,2018)。这些方法专注于静态环境。处理移动对象的方法,如DynamicFusion(Newcombe等人,2015)、Mask-fusion(Rünz等人,2018)、Co-fusion(Rünz和Agapito,2017)和MID-Fusion(Xu等人,2019)目前限于小型桌面场景,侧重于对象或密集地图,而不是场景图。这些工作大多依赖于GPU处理(McCormac等人,2017;Zheng等人,2019;Tateno等人,2015;Li等人,2016;McCormac等人,2018;Rünz等人,2018;Rünz和Agapito,2017;Xu等人,2019)。最近的工作调查了与RGB-D传感相结合的基于CPU的方法,例如Wald等人(2018)、PanopticFusion(Narita等人,2019)和Voxblox++(Grinvald等人,2019)。一组更稀疏的贡献涉及其他传感方式,包括单目相机(例如,CNN-SLAM(Tateno等人,2017)、VSO(Lianos等人,2018)、VITAMIN-E(Yokozuka等人,2019)、XIVO(Dong等人,2017))和激光雷达(Behley等人,2019;Dubé等人,2018)。
循环闭合与密集表示。这一领域的工作涉及在循环闭合发生后校正环境的密集表示(例如,点云、网格、体素)。LSD-SLAM(Engel等人,2014)用点云表示环境;循环闭合不会直接影响点云地图,而是校正与相机关键帧相关联的姿态图,每个关键帧附加的半密集局部地图相应更新。我们特别感兴趣的是环境被表示为网格,并且循环闭合通过变形这个网格来实施的情况。Kintinuous(Whelan等人,2013)在两个优化步骤中完成:首先优化姿态图,然后利用网格顶点和姿态图中的姿态之间的关系,使用优化后的姿态图作为测量约束来变形网格。MIS-SLAM(Song等人,2018)也使用变形图方法来变形模型点云,使用ORB-SLAM(Mur-Artal和Tardós,2017)的估计。ElasticFusion(Whelan等人,2015)则变形一个密集的surfels地图,GravityFusion(Puri等人,2017)
在ElasticFusion的基础上通过强制所有surfels之间的一致重力方向进行构建。Voxgraph(Reijgwart等人,2020)通过在一组子图姿态上应用图优化来构建全局一致的体积地图,包括里程计和循环闭合约束。类似地,DynamicFusion(Newcombe等人,2015)、VolumeDeform(Innmann等人,2016)和Fusion4D(Dou等人,2016)使用体积表示进行融合和变形。我们的方法首次同时优化姿态图和网格,并且首次将这个问题形式化为姿态图优化。
度量到拓扑场景解析。这一领域的工作侧重于将度量地图划分为语义有意义的地点(例如,房间、走廊)。Nüchter和Hertzberg(2008)编码平面表面(例如,墙壁、地板、天花板)之间的关系,并在场景中检测对象。Blanco等人(2009);Gomez等人(2020)提出了一个混合度量-拓扑地图。Friedman等人(2007)提出Voronoi随机场来通过地点标记获得2D网格地图的抽象模型。Rogers和Christensen(2012)以及Lin等人(2013)利用对象进行联合对象和地点分类。Nie等人(2020);Huang等人(2018a);Zhao和Zhu(2013b)联合解决场景理解和重建的问题。Pangercic等人(2012)推理对象的功能。Pronobis和Jensfelt(2012)使用马尔可夫随机场来分割2D网格地图。Zheng等人(2018)使用图结构的求和积网络推断网格地图的拓扑结构,而Zheng和Pronobis(2019)使用神经网络。Armeni等人(2016)专注于3D网格,并提出一种将建筑物解析为房间的方法。从单个图像(Hedau等人,2009;Schwing等人,2013)、全景图像(Lukierski等人,2017)、2D激光雷达(Li和Stevenson,2020;Turner和Zakhor,2014)、3D激光雷达(Mura等人,2014;Ochmann等人,2014)、RGB-D(Liu等人,2018)或从众包手机轨迹(Alzantot和Youssef,2012)估计楼层平面图也得到了研究。Armeni等人(2016);Mura等人(2014);Ochmann等人(2014)的工作与我们的提议最接近,但与(Armeni等人,2016)不同,我们不依赖于曼哈顿世界假设,与(Mura等人,2014);Ochmann等人(2014)不同,我们操作网格模型。最近,Wald等人(2020)提出从点云中学习一个3D语义场景图,专注于表示实例间语义有意义的关系。人体姿态估计和跟踪。从单个图像中进行人体姿态和形状估计是一个日益增长的研究领域。我们参考(Kolotouros等人,2019b;Kolotouros等人,2019;Kolotouros等人,2019a;Kocabas等人,2020)进行更广泛的回顾,值得一提的是相关方法包括基于优化的方法,这些方法拟合3D网格到2D图像关键点(Bogo等人,2016;Lassner等人,2017;Zanfir等人,2018;Kolotouros等人,2019;Yang和Carlone,2020),以及基于学习的方法,这些方法直接从像素信息中推断网格(Tan等人,2017;Kanazawa等人,2018;Omran等人,2018;Pavlakos等人,2018;Kolotouros等人,2019b;Kolotouros等人,2019)。人体模型通常使用Skinned Multi-Person Linear Model(SMPL)(Loper等人,2015)进行参数化,该模型提供了紧凑的姿态和形状描述,并且可以渲染为具有6890个顶点和23个关节的网格。单目人体跟踪的常见方法是预测2D图像空间中的关节概率,这些概率基于多个时间序列观测和运动先验优化为3D关节(Andriluka等人,2010;Andriluka等人,2008;Arnab等人,2019;Bridgeman等人,2019;Elhayek等人,2012;Zhou等人,2018b;Wang等人,2020)。Taylor等人(2010)结合学习的运动模型和粒子滤波来预测3D人体姿态。在这项工作中,我们的目标不仅是估计人体的3D姿态,而且还要估计完整的SMPL形状,而不需要许多上述方法所必需的持久图像历史记录。在人体跟踪文献中,只有Arnab等人(2019)完全重建了人体的SMPL形状;然而,他们在执行多时间步长的数据关联后才重建形状。相比之下,我们使用Kolotouros等人(2019b)的方法,在每个时间步长直接获得人体的完整3D姿态,简化了姿态估计,并允许我们基于SMPL身体形状进行数据关联。
8 结论
我们介绍了3D动态场景图,这是一种可操作的空间感知的统一表示。此外,我们展示了Kimera,这是一个从视觉-惯性数据中全自动构建DSG的空间感知引擎。我们在照片级逼真的模拟和真实数据中展示了Kimera,并讨论了由所提出的DSG表示启用的应用,包括语义和层次路径规划。本文开辟了几个研究方向。首先,开发能够增量运行并实时运行的空间感知引擎将是可取的。目前,虽然度量-语义重建的创建是实时的,但其余的场景图是在运行结束时构建的,需要几分钟的时间来解析整个场景。其次,设计能够从异构传感器和多个机器人收集的传感器数据估计DSG的引擎将是有趣的。最后,丰富DSG与物理属性,包括对象的材料类型和可供性,以及尝试从数据中学习属性和关系,是一个自然的方向。
致谢 我们感谢Dan Griffith、Ben Smith、Arjun Majumdar和Zac Ravichandran开源化TESSE模拟器,以及与Winter Guerra和Varun Murali讨论Unity。
免责声明 分发声明A。经批准公开发布。分发不受限制。本材料基于由国防研究与工程副部长办公室支持的工作,空军合同号FA8702-15-D-0001。本文中表达的任何意见、发现、结论或建议仅代表作者的观点,并不一定反映国防研究与工程副部长办公室的观点。